Computer Vision
Extracting meaning and building representations of visual objects and events in the world.
Our main research themes cover the areas of deep learning and artificial intelligence for object and action detection, classification and scene understanding, robotic vision and object manipulation, 3D processing and computational geometry, as well as simulation of physical systems to enhance machine learning systems.
Quick Links
-
Researchers

Anoop
Cherian

Tim K.
Marks

Michael J.
Jones

Suhas
Lohit

Chiori
Hori

Kuan-Chuan
Peng

Moitreya
Chatterjee

Jonathan
Le Roux

Hassan
Mansour

Siddarth
Jain

Matthew
Brand

Pedro
Miraldo

Radu
Corcodel

Petros T.
Boufounos

Ye
Wang

Daniel N.
Nikovski

Anthony
Vetro

Gordon
Wichern

William S.
Yerazunis

Toshiaki
Koike-Akino

Dehong
Liu

Arvind
Raghunathan

Abraham P.
Vinod

Pu
(Perry)
Wang
Avishai
Weiss

Stefano
Di Cairano

Lalit
Manam

Yoshiki
Masuyama

Kaen
Kogashi

Yanting
Ma

Joshua
Rapp

Alexander
Schperberg

Huifang
Sun

Kento
Tomita

Yebin
Wang

Kenji
Inomata

Jin
Kato

Jing
Liu

Kei
Suzuki
-
Awards
-
AWARD Best Paper - Honorable Mention Award at WACV 2021 Date: January 6, 2021
Awarded to: Rushil Anirudh, Suhas Lohit, Pavan Turaga
MERL Contact: Suhas Lohit
Research Areas: Computational Sensing, Computer Vision, Machine LearningBrief- A team of researchers from Mitsubishi Electric Research Laboratories (MERL), Lawrence Livermore National Laboratory (LLNL) and Arizona State University (ASU) received the Best Paper Honorable Mention Award at WACV 2021 for their paper "Generative Patch Priors for Practical Compressive Image Recovery".
The paper proposes a novel model of natural images as a composition of small patches which are obtained from a deep generative network. This is unlike prior approaches where the networks attempt to model image-level distributions and are unable to generalize outside training distributions. The key idea in this paper is that learning patch-level statistics is far easier. As the authors demonstrate, this model can then be used to efficiently solve challenging inverse problems in imaging such as compressive image recovery and inpainting even from very few measurements for diverse natural scenes.
- A team of researchers from Mitsubishi Electric Research Laboratories (MERL), Lawrence Livermore National Laboratory (LLNL) and Arizona State University (ASU) received the Best Paper Honorable Mention Award at WACV 2021 for their paper "Generative Patch Priors for Practical Compressive Image Recovery".
-
AWARD MERL Researchers win Best Paper Award at ICCV 2019 Workshop on Statistical Deep Learning in Computer Vision Date: October 27, 2019
Awarded to: Abhinav Kumar, Tim K. Marks, Wenxuan Mou, Chen Feng, Xiaoming Liu
MERL Contact: Tim K. Marks
Research Areas: Artificial Intelligence, Computer Vision, Machine LearningBrief- MERL researcher Tim Marks, former MERL interns Abhinav Kumar and Wenxuan Mou, and MERL consultants Professor Chen Feng (NYU) and Professor Xiaoming Liu (MSU) received the Best Oral Paper Award at the IEEE/CVF International Conference on Computer Vision (ICCV) 2019 Workshop on Statistical Deep Learning in Computer Vision (SDL-CV) held in Seoul, Korea. Their paper, entitled "UGLLI Face Alignment: Estimating Uncertainty with Gaussian Log-Likelihood Loss," describes a method which, given an image of a face, estimates not only the locations of facial landmarks but also the uncertainty of each landmark location estimate.
-
AWARD CVPR 2011 Longuet-Higgins Prize Date: June 25, 2011
Awarded to: Paul A. Viola and Michael J. Jones
Awarded for: "Rapid Object Detection using a Boosted Cascade of Simple Features"
Awarded by: Conference on Computer Vision and Pattern Recognition (CVPR)
MERL Contact: Michael J. Jones
Research Area: Machine LearningBrief- Paper from 10 years ago with the largest impact on the field: "Rapid Object Detection using a Boosted Cascade of Simple Features", originally published at Conference on Computer Vision and Pattern Recognition (CVPR 2001).
See All Awards for MERL -
-
News & Events
-
NEWS MERL Presents 4 Main Conference Papers and 6 Workshop Papers at ICML 2026 Date: July 6, 2026 - July 11, 2026
Where: COEX, Seoul, South Korea
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Stefano Di Cairano; Toshiaki Koike-Akino; Christopher R. Laughman; Jing Liu; Suhas Lohit; Kuan-Chuan Peng; Alexander Schperberg; Ye Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Computer Vision, Machine Learning, Signal ProcessingBrief- MERL researchers are proud to present 4 main conference papers and 6 workshop papers at ICML 2026. ICML, taking place from July 6-11 in Seoul, South Korea, is a premier international conference in machine learning.
Main Conference Papers with MERL Authors:
1. Understanding Dynamic Compute Allocation in Recurrent Transformers by Ibraheem Muhammad Moosa, Suhas Lohit, Ye Wang, Moitreya Chatterjee, and Wenpeng Yin.
2. LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior by Qinhong Zhou, Chuang Gan, and Anoop Cherian.
3. Memory-Distilled Selection for Noise-Robust Anomaly Detection by Sirojbek Safarov, Jaewoo Park, Yoon G. Jung, Kuan-Chuan Peng, Wonchul Kim, Seongdeok Bang, and Octavia Camps.
4. Partial Ring Scan: Revisiting Scan Order in Vision State Space Models by Yi-Kuan Hsieh, Kuan-Chuan Peng, Xin Li, Ming-Ching Chang, Yu-Chee Tseng, and Jun-Wei Hsieh.
Workshop Papers with MERL Authors:
1. WISE: Weighted Iterative Society-of-Experts for Multimodal Multi-Agent Debate with Probabilistic Consensus by Anoop Cherian, Suhas Lohit, and Kuan-Chuan Peng. (Workshop on Scalable Learning and Optimization for Efficient Multimodal AI Agents (SCALE))
2. MIRROR: Multisensory Implicit Rejection-sampled RObotic policy by Amisha Bhaskar, Pratap Tokekar, Stefano Di Cairano, and Alexander Schperberg. (Workshop on Structured Probabilistic Inference & Generative Modeling)
3. Reinforced Neural Processes: Memory-Efficient Time-Series Forecasting with a World-Feedback-Trained Memory Policy by Nibraas Khan, Gordon Wichern, and Christopher R. Laughman. (Workshop on Reinforcement Learning from World Feedback (RLxF))
4. Connecting Low-Rank Adapters and Policy Stability in GRPO Fine-Tuning by Antonin Rottman, Francesco Tonin, Yongtao Wu, Toshiaki Koike-Akino, and Volkan Cevher. (Workshop on Connecting Low-rank Representations in AI (CoLorAI))
5. EinSort: Sorting is All We Need for Tensorizing LLM by Toshiaki Koike-Akino, Jing Liu, and Ye Wang. (Workshop on Connecting Low-rank Representations in AI (CoLorAI))
6. Temper and Tilt Lead to SLOP: Reward Hacking Mitigation with Inference-Time Alignment by Ye Wang, and Jing Liu, and Toshiaki Koike-Akino. (Workshop on Agents in the Wild: Safety, Security, and Beyond)
- MERL researchers are proud to present 4 main conference papers and 6 workshop papers at ICML 2026. ICML, taking place from July 6-11 in Seoul, South Korea, is a premier international conference in machine learning.
-
NEWS MERL researchers present 9 papers at IEEE ICRA 2026 Date: June 1, 2026 - June 5, 2026
Where: Vienna, Austria
MERL Contacts: Radu Corcodel; Stefano Di Cairano; Purnanand Elango; Siddarth Jain; Alexander Schperberg; Kento Tomita
Research Areas: Artificial Intelligence, Computer Vision, Control, Dynamical Systems, Machine Learning, Optimization, RoboticsBrief- MERL researchers presented nine papers at the recently concluded IEEE International Conference on Robotics and Automation (ICRA) 2026 in Vienna, Austria. The papers covered a broad set of topics in robotics, including robot perception, visuo-tactile sensing, contact and pose estimation, manipulation, reinforcement learning, diffusion policies, loco-manipulation, contact-implicit trajectory optimization, legged locomotion, localization, and perception-aware planning.
IEEE ICRA is the flagship conference of the IEEE Robotics and Automation Society and the world’s largest and most comprehensive technical conference focused on research advances and the latest technological developments in robotics. The event attracts nearly 8,000 participants and receives more than 5,000 paper submissions.
- MERL researchers presented nine papers at the recently concluded IEEE International Conference on Robotics and Automation (ICRA) 2026 in Vienna, Austria. The papers covered a broad set of topics in robotics, including robot perception, visuo-tactile sensing, contact and pose estimation, manipulation, reinforcement learning, diffusion policies, loco-manipulation, contact-implicit trajectory optimization, legged locomotion, localization, and perception-aware planning.
See All News & Events for Computer Vision -
-
Research Highlights
-
LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior -
Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting -
AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects -
SLAM-MER: Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling -
Parallel Rigidity Matters for Bundle Adjustment -
LLMPhy: Parameter-Identifiable Physical Reasoning Combining Large Language Models and Physics Engines -
SAC-GNC: SAmple Consensus for adaptive Graduated Non-Convexity -
PS-NeuS: A Probability-guided Sampler for Neural Implicit Surface Rendering -
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models -
Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-Aware Spatio-Temporal Sampling -
Steered Diffusion -
Robust Machine Learning -
Video Anomaly Detection -
MERL Shopping Dataset -
Point-Plane SLAM
-
-
Internships
-
CV0101: Internship - Multimodal Algorithmic Reasoning
-
CI0213: Internship - Efficient Foundation Models for Edge Intelligence
-
CA0153: Internship - High-Fidelity Visualization and Simulation for Space Applications
See All Internships for Computer Vision -
-
Openings
See All Openings at MERL -
Recent Publications
- , "Partial Ring Scan: Revisiting Scan Order in Vision State Space Models", International Conference on Machine Learning (ICML), July 2026.BibTeX TR2026-091 PDF
- @inproceedings{Hsieh2026jul,
- author = {Hsieh, Yi-Kuan and Peng, Kuan-Chuan and Li, Xin and Chang, Ming-Ching and Tseng, Yu-Chee and Hsieh, Jun-Wei},
- title = {{Partial Ring Scan: Revisiting Scan Order in Vision State Space Models}},
- booktitle = {International Conference on Machine Learning (ICML)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-091}
- }
- , "Understanding Dynamic Compute Allocation in Recurrent Transformers", International Conference on Machine Learning (ICML), July 2026.BibTeX TR2026-090 PDF Software Presentation
- @inproceedings{Moosa2026jul,
- author = {{Moosa, Ibraheem Muhammad and Lohit, Suhas and Wang, Ye and Chatterjee, Moitreya and Yin, Wenpeng}},
- title = {{Understanding Dynamic Compute Allocation in Recurrent Transformers}},
- booktitle = {International Conference on Machine Learning (ICML)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-090}
- }
- , "Memory-Distilled Selection for Noise-Robust Anomaly Detection", International Conference on Machine Learning (ICML), July 2026.BibTeX TR2026-089 PDF
- @inproceedings{Safarov2026jul,
- author = {{Safarov, Sirojbek and Park, Jaewoo and Jung, Yoon G. and Peng, Kuan-Chuan and Kim, Wonchul and Bang, Seongdeok and Camps, Octavia}},
- title = {{Memory-Distilled Selection for Noise-Robust Anomaly Detection}},
- booktitle = {International Conference on Machine Learning (ICML)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-089}
- }
- , "WISE: Weighted Iterative Society-of-Experts for Multimodal Multi-Agent Debate with Probabilistic Consensus", ICML SCALE AI Workshop, June 2026.BibTeX TR2026-083 PDF
- @inproceedings{Cherian2026jun,
- author = {Cherian, Anoop and Lohit, Suhas and Peng, Kuan-Chuan},
- title = {{WISE: Weighted Iterative Society-of-Experts for Multimodal Multi-Agent Debate with Probabilistic Consensus}},
- booktitle = {ICML SCALE AI Workshop},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-083}
- }
- , "LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior", International Conference on Machine Learning (ICML), June 2026.BibTeX TR2026-081 PDF Video Software
- @inproceedings{Zhou2026jun,
- author = {Zhou, Qinhong and Gan, Chuang and Cherian, Anoop},
- title = {{LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior}},
- booktitle = {International Conference on Machine Learning (ICML)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-081}
- }
- , "SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification Supplementary Material", CVPR Findings, June 2026.BibTeX TR2026-074 PDF
- @inproceedings{Hsieh2026jun,
- author = {Hsieh, Jun-Wei and Wu, Ying-Hsuan and Hsieh, Yi-Kuan and Li, Xin and Peng, Kuan-Chuan and Chang, Ming-Ching},
- title = {{SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification Supplementary Material}},
- booktitle = {CVPR Findings},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-074}
- }
- , "SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification", CVPR Findings, June 2026.BibTeX TR2026-075 PDF
- @inproceedings{Hsieh2026jun2,
- author = {Hsieh, Jun-Wei and Wu, Ying-Hsuan and Hsieh, Yi-Kuan and Li, Xin and Peng, Kuan-Chuan and Chang, Ming-Ching},
- title = {{SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification}},
- booktitle = {CVPR Findings},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-075}
- }
- , "AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2026.BibTeX TR2026-076 PDF Video Data Software
- @inproceedings{Li2026jun,
- author = {Li, Danrui and Zhang, Jiahao and Egger, Bernhard and Chatterjee, Moitreya and Lohit, Suhas and Marks, Tim K. and Cherian, Anoop},
- title = {{AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-076}
- }
- , "Partial Ring Scan: Revisiting Scan Order in Vision State Space Models", International Conference on Machine Learning (ICML), July 2026.
-
Videos
-
Software & Data Downloads
-
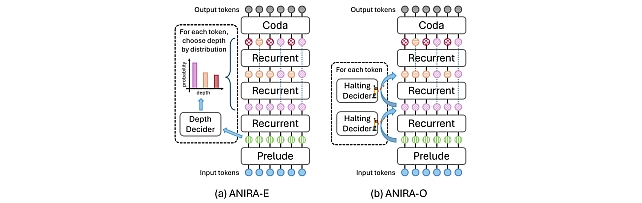
Understanding Dynamic Compute Allocation in Recurrent Transformers -

Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior -
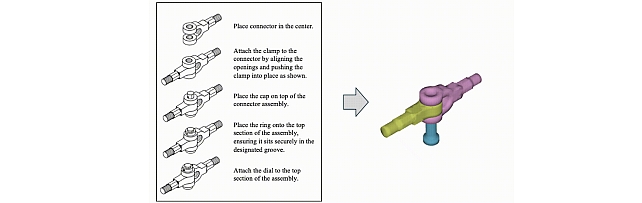
Physics-Aware Assembly of Complex Industrial Objects -
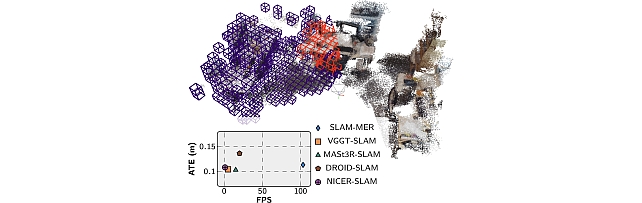
Mitsubishi Electric Research framework for visual SLAM -
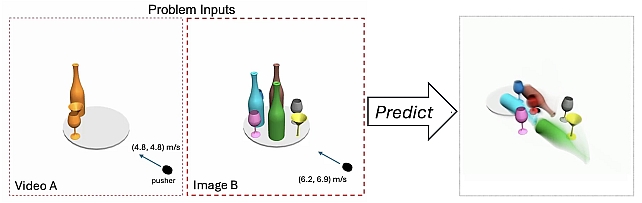
Parameter-Identifiable Physical Reasoning Combining Large Language Models and Physics Engines -

MMHOI Dataset: Modeling Complex 3D Multi-Human Multi-Object Interactions -
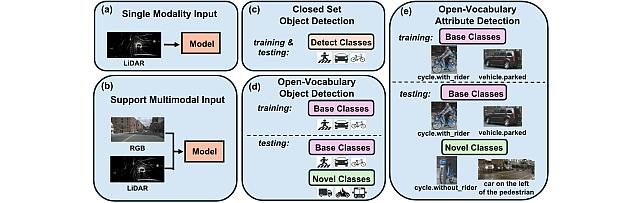
Open Vocabulary Attribute Detection Dataset -
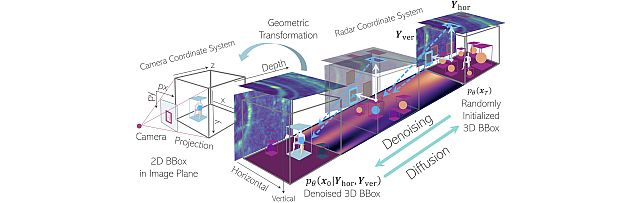
multi-view Radar object dEtection with 3D bounding boX diffusiOn -
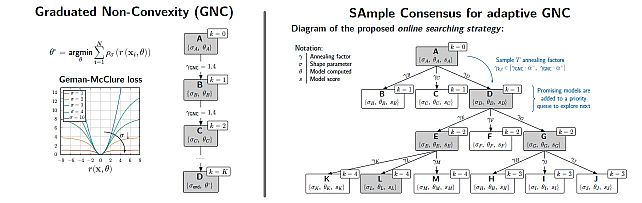
SAmple Consensus for Adaptive Graduated Non-Convexity -
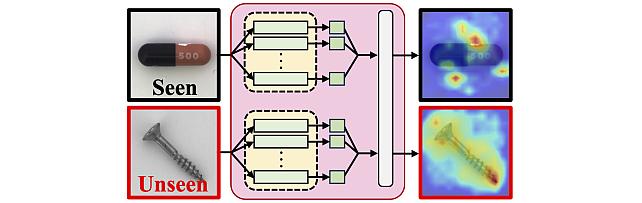
Long-Tailed Online Anomaly Detection dataset -
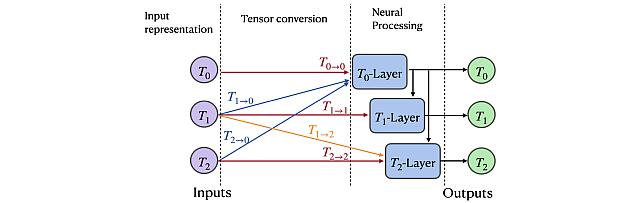
Group Representation Networks -
ComplexVAD Dataset -

Zero-Shot Image Conditioning for Text-to-Video Diffusion Models -
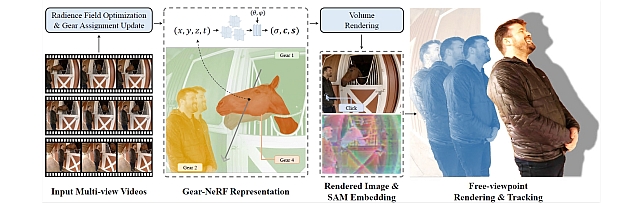
Gear Extensions of Neural Radiance Fields -
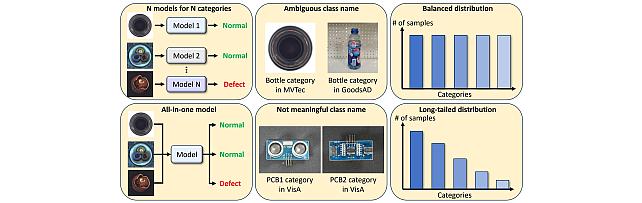
Long-Tailed Anomaly Detection Dataset -

Pixel-Grounded Prototypical Part Networks -

Steered Diffusion -

BAyesian Network for adaptive SAmple Consensus -
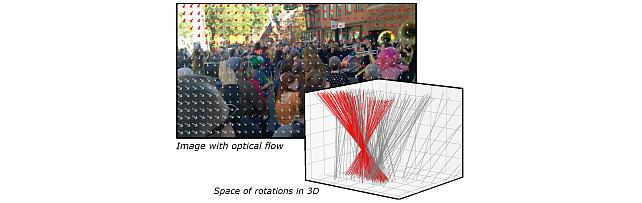
Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes
-
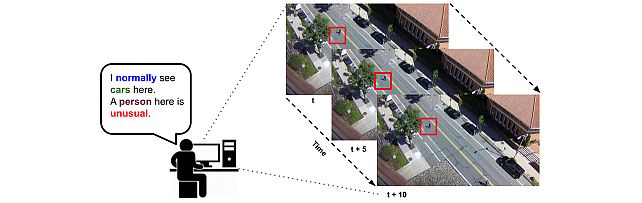
Explainable Video Anomaly Localization -

Simple Multimodal Algorithmic Reasoning Task Dataset -
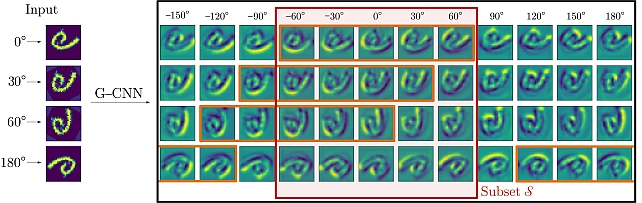
Partial Group Convolutional Neural Networks -
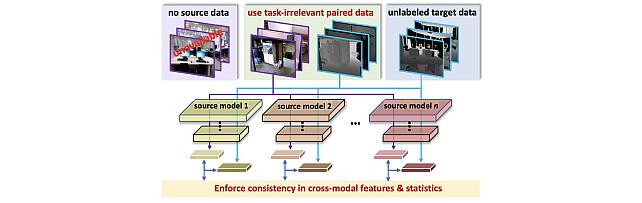
SOurce-free Cross-modal KnowledgE Transfer -
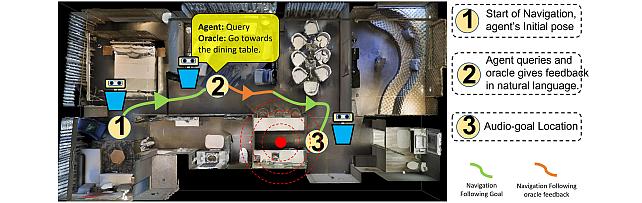
Audio-Visual-Language Embodied Navigation in 3D Environments -

3D MOrphable STyleGAN -
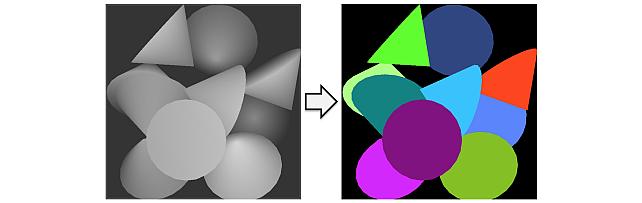
Instance Segmentation GAN -
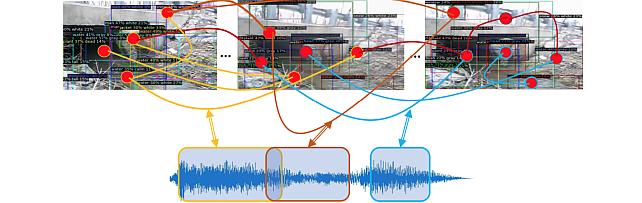
Audio Visual Scene-Graph Segmentor -
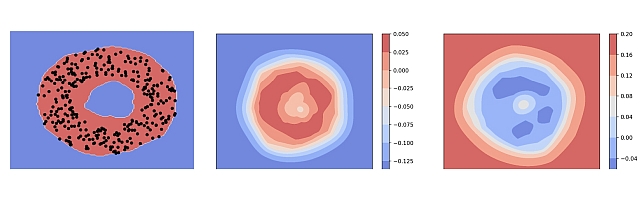
Generalized One-class Discriminative Subspaces -

Generating Visual Dynamics from Sound and Context -

Adversarially-Contrastive Optimal Transport -
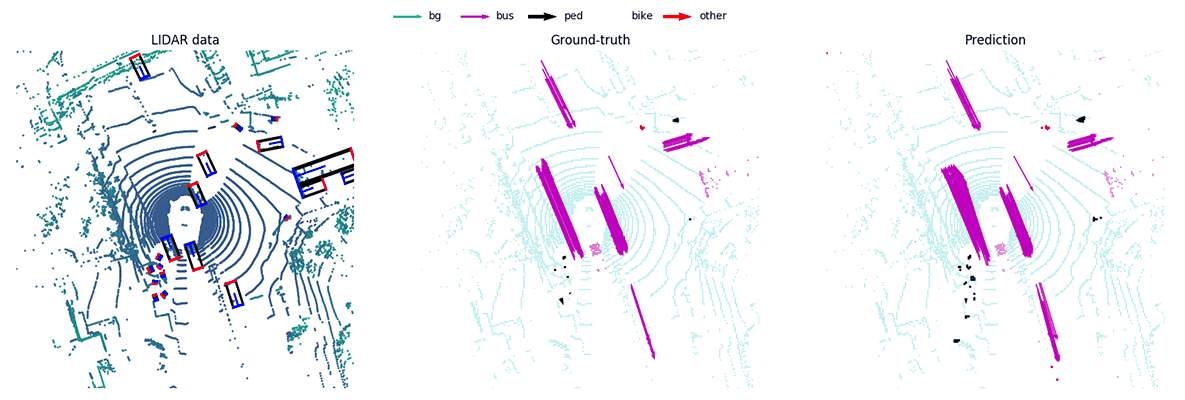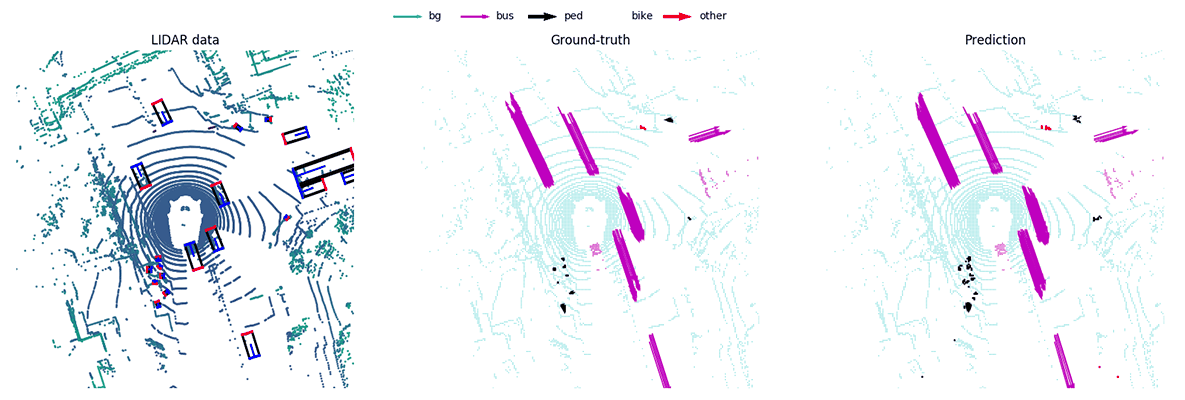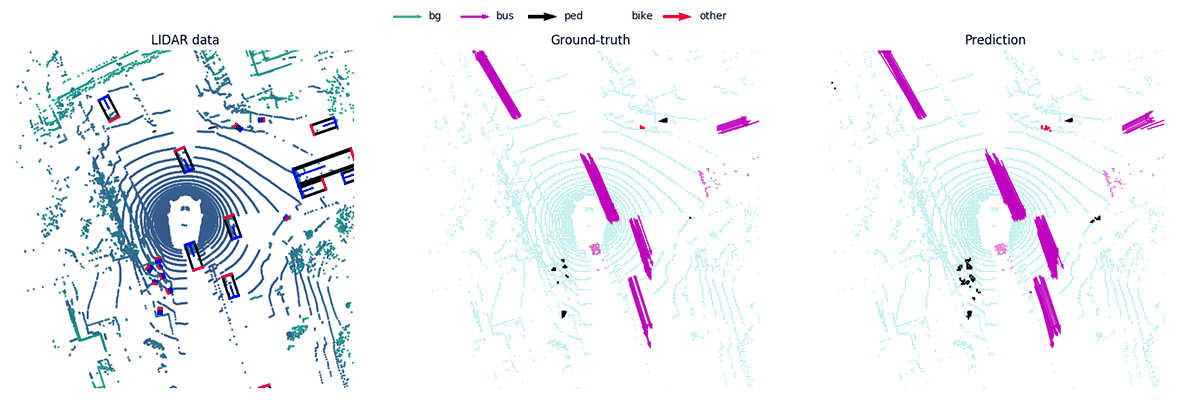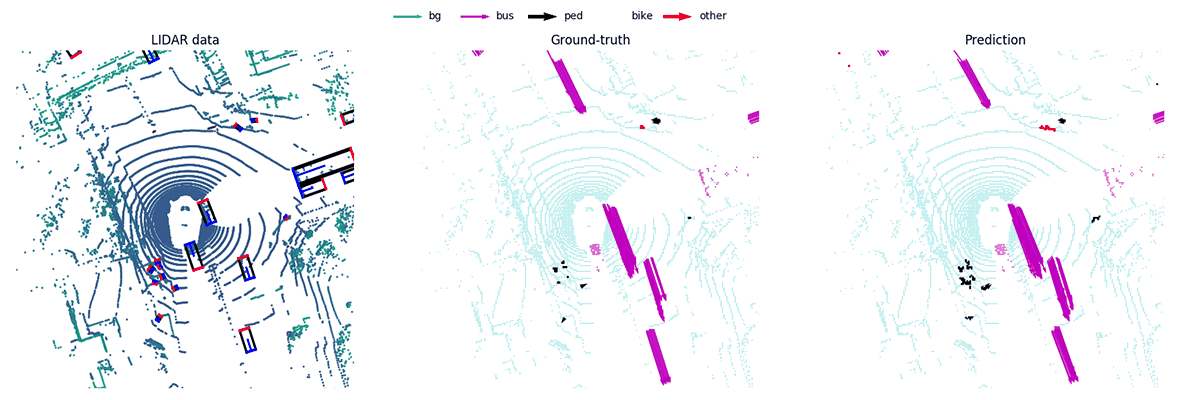
MotionNet -

Street Scene Dataset -

FoldingNet++ -
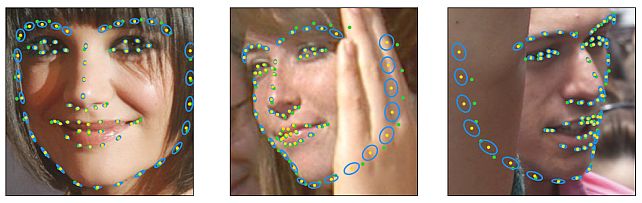
Landmarks’ Location, Uncertainty, and Visibility Likelihood -
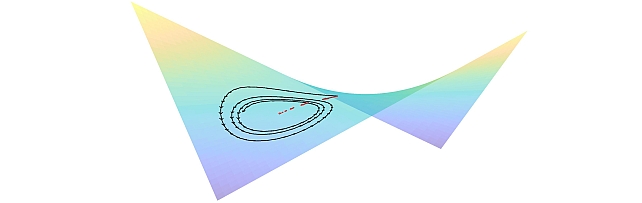
Gradient-based Nikaido-Isoda -
Circular Maze Environment -

Discriminative Subspace Pooling -
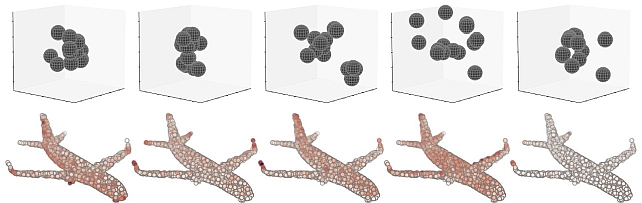
Kernel Correlation Network -

Fast Resampling on Point Clouds via Graphs -
FoldingNet -

MERL Shopping Dataset -

Joint Geodesic Upsampling -

Plane Extraction using Agglomerative Clustering -

MERL BRDF Database
-