Speech & Audio
Audio source separation, recognition, and understanding.
Our current research focuses on application of machine learning to estimation and inference problems in speech and audio processing. Topics include end-to-end speech recognition and enhancement, acoustic modeling and analysis, statistical dialog systems, as well as natural language understanding and adaptive multimodal interfaces.
Quick Links
-
Researchers
-
Awards
-
AWARD MERL Team Wins DCASE 2026 Challenge on Anomalous Sound Detection for Machine Condition Monitoring Date: June 30, 2026
Awarded to: Takuya Fujimura, Gordon Wichern, Yoshiki Masuyama, Christoph Boeddeker, Kohei Saijo, Julius Richter, Takahiro Edo, and Jonathan Le Roux
MERL Contacts: Christoph Boeddeker; Takahiro Edo; Jonathan Le Roux; Yoshiki Masuyama; Julius Richter; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Signal Processing, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 51 teams in the DCASE 2026 Challenge’s Task 2, “Noise-aware Unsupervised Anomalous Sound Detection for Machine Condition Monitoring.” The team was led by MERL intern Takuya Fujimura, and also included Gordon Wichern, Yoshiki Masuyama, Christoph Boeddeker, Kohei Saijo, Julius Richter, Takahiro Edo, and Jonathan Le Roux.
The IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), started in 2013, has been organized yearly since 2016, and gathers challenges on multiple tasks related to the detection, analysis, and generation of sound events. This year, the DCASE 2026 Challenge received 421 submissions from 135 teams across seven tasks.
The MERL team won Task 2, Noise-aware Unsupervised Anomalous Sound Detection for Machine Condition Monitoring, which aims at building noise-robust systems for automatically detecting machine failure via microphones when only normal machine operating data is available for system development. Task 2 was by far the most popular out of the 7 DCASE 2026 tasks, with 51 teams submitting 168 entries. The MERL team's system was built around MERL’s recently proposed paradigm of noise-aware self-supervised learning, which extracts noise robust features leveraging two-channel recordings, in which one microphone is used to capture noise. Anomaly detection is then performed in the extracted denoised feature space using advanced score normalization. The team's best submission obtained a composite score of 70.24% on five evaluation machines, largely outperforming the 2nd best team's 65.45%.
MERL also participated in Task 4, Spatial Semantic Segmentation of Sound Scenes (S5) and placed 3rd out of 10 teams in separation performance. Our cascaded system consists of universal sound separation with source counting, source classification, and class-aware refinement, where the separation and refinement modules are built upon MERL's TF-Locoformer separation technology. Notably, the team's best submission obtained a label prediction accuracy of 76.92% on the evaluation set, largely outperforming the 2nd best team's 65.54%.
- MERL's Speech & Audio team ranked 1st out of 51 teams in the DCASE 2026 Challenge’s Task 2, “Noise-aware Unsupervised Anomalous Sound Detection for Machine Condition Monitoring.” The team was led by MERL intern Takuya Fujimura, and also included Gordon Wichern, Yoshiki Masuyama, Christoph Boeddeker, Kohei Saijo, Julius Richter, Takahiro Edo, and Jonathan Le Roux.
-
AWARD MERL team wins the Generative Data Augmentation of Room Acoustics (GenDARA) 2025 Challenge Date: April 7, 2025
Awarded to: Christopher Ick, Gordon Wichern, Yoshiki Masuyama, François G. Germain, and Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Yoshiki Masuyama; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 3 teams in the Generative Data Augmentation of Room Acoustics (GenDARA) 2025 Challenge, which focused on “generating room impulse responses (RIRs) to supplement a small set of measured examples and using the augmented data to train speaker distance estimation (SDE) models". The team was led by MERL intern Christopher Ick, and also included Gordon Wichern, Yoshiki Masuyama, François G. Germain, and Jonathan Le Roux.
The GenDARA Challenge was organized as part of the Generative Data Augmentation (GenDA) workshop at the 2025 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2025), and held on April 7, 2025 in Hyderabad, India. Yoshiki Masuyama presented the team's method, "Data Augmentation Using Neural Acoustic Fields With Retrieval-Augmented Pre-training".
The GenDARA challenge aims to promote the use of generative AI to synthesize RIRs from limited room data, as collecting or simulating RIR datasets at scale remains a significant challenge due to high costs and trade-offs between accuracy and computational efficiency. The challenge asked participants to first develop RIR generation systems capable of expanding a sparse set of labeled room impulse responses by generating RIRs at new source–receiver positions. They were then tasked with using this augmented dataset to train speaker distance estimation systems. Ranking was determined by the overall performance on the downstream SDE task. MERL’s approach to the GenDARA challenge centered on a geometry-aware neural acoustic field model that was first pre-trained on a large external RIR dataset to learn generalizable mappings from 3D room geometry to room impulse responses. For each challenge room, the model was then adapted or fine-tuned using the small number of provided RIRs, enabling high-fidelity generation of RIRs at unseen source–receiver locations. These augmented RIR sets were subsequently used to train the SDE system, improving speaker distance estimation by providing richer and more diverse acoustic training data.
- MERL's Speech & Audio team ranked 1st out of 3 teams in the Generative Data Augmentation of Room Acoustics (GenDARA) 2025 Challenge, which focused on “generating room impulse responses (RIRs) to supplement a small set of measured examples and using the augmented data to train speaker distance estimation (SDE) models". The team was led by MERL intern Christopher Ick, and also included Gordon Wichern, Yoshiki Masuyama, François G. Germain, and Jonathan Le Roux.
-
AWARD MERL team wins the Listener Acoustic Personalisation (LAP) 2024 Challenge Date: August 29, 2024
Awarded to: Yoshiki Masuyama, Gordon Wichern, Francois G. Germain, Christopher Ick, and Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Gordon Wichern; Yoshiki Masuyama
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 7 teams in Task 2 of the 1st SONICOM Listener Acoustic Personalisation (LAP) Challenge, which focused on "Spatial upsampling for obtaining a high-spatial-resolution HRTF from a very low number of directions". The team was led by Yoshiki Masuyama, and also included Gordon Wichern, Francois Germain, MERL intern Christopher Ick, and Jonathan Le Roux.
The LAP Challenge workshop and award ceremony was hosted by the 32nd European Signal Processing Conference (EUSIPCO 24) on August 29, 2024 in Lyon, France. Yoshiki Masuyama presented the team's method, "Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization", and received the award from Prof. Michele Geronazzo (University of Padova, IT, and Imperial College London, UK), Chair of the Challenge's Organizing Committee.
The LAP challenge aims to explore challenges in the field of personalized spatial audio, with the first edition focusing on the spatial upsampling and interpolation of head-related transfer functions (HRTFs). HRTFs with dense spatial grids are required for immersive audio experiences, but their recording is time-consuming. Although HRTF spatial upsampling has recently shown remarkable progress with approaches involving neural fields, HRTF estimation accuracy remains limited when upsampling from only a few measured directions, e.g., 3 or 5 measurements. The MERL team tackled this problem by proposing a retrieval-augmented neural field (RANF). RANF retrieves a subject whose HRTFs are close to those of the target subject at the measured directions from a library of subjects. The HRTF of the retrieved subject at the target direction is fed into the neural field in addition to the desired sound source direction. The team also developed a neural network architecture that can handle an arbitrary number of retrieved subjects, inspired by a multi-channel processing technique called transform-average-concatenate.
- MERL's Speech & Audio team ranked 1st out of 7 teams in Task 2 of the 1st SONICOM Listener Acoustic Personalisation (LAP) Challenge, which focused on "Spatial upsampling for obtaining a high-spatial-resolution HRTF from a very low number of directions". The team was led by Yoshiki Masuyama, and also included Gordon Wichern, Francois Germain, MERL intern Christopher Ick, and Jonathan Le Roux.
See All Awards for Speech & Audio -
-
News & Events
-
EVENT MERL Contributes to ICASSP 2026 Date: Monday, May 4, 2026 - , May 8, 2026
Location: Barcelona, Spain
MERL Contacts: Wael H. Ali; Petros T. Boufounos; Chiori Hori; Jonathan Le Roux; Yanting Ma; Hassan Mansour; Yoshiki Masuyama; Joshua Rapp; Anthony Vetro; Pu (Perry) Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Computational Sensing, Computer Vision, Machine Learning, Optimization, Signal Processing, Speech & AudioBrief- MERL has made numerous contributions to both the organization and technical program of ICASSP 2026, which is being held in Barcelona, Spain from May 4-8, 2026.
Sponsorship
MERL is proud to be a Silver Patron of the conference and will participate in the student job fair on Thursday, May 7. Please join this session to learn more about employment opportunities at MERL, including openings for research scientists, post-docs, and interns. MERL Distinguished Research Scientists Petros T. Boufounos and Jonathan Le Roux will also present a spotlight session on MERL’s research in signal processing on Tuesday, May 5 at 13:05. Finally, MERL will sponsor a photo booth on Thursday, May 7 and Friday, May 8, where ICASSP participants can take professional photos with friends and colleagues, which will be emailed to them.
MERL is also pleased to be the sponsor of two IEEE Awards that will be presented at the conference. We congratulate Prof. Nasir Ahmed, the recipient of the 2026 IEEE Fourier Award for Signal Processing, and Dr. Alex Acero, the recipient of the 2026 IEEE James L. Flanagan Speech and Audio Processing Award.
Technical Program
MERL is presenting 8 papers in the main conference on a wide range of topics including source separation, spatial audio, neural audio codecs, radar-based pose estimation, camera-based airflow sensing, radar array processing, and optimization. Another paper on neural speech codecs will be presented at the Low-Resource Audio Codec (LRAC) Satellite Workshop. MERL researchers will also present two articles published in IEEE Open Journal of Signal Processing (OJSP) on music source separation and head-related transfer function (HRTF) modeling. Finally, Speech and Audio Team members Yoshiki Masuyama and Jonathan Le Roux co-organized a Special Session on Neural Spatial Audio Processing, which will feature six oral presentations.
About ICASSP
ICASSP is the flagship conference of the IEEE Signal Processing Society, and the world's largest and most comprehensive technical conference focused on the research advances and latest technological development in signal and information processing. The event attracts more than 4000 participants each year.
- MERL has made numerous contributions to both the organization and technical program of ICASSP 2026, which is being held in Barcelona, Spain from May 4-8, 2026.
-
NEWS MERL hosts Boston AI Music Meetup Date: March 19, 2026
Where: Cambridge, MA
MERL Contact: Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL hosted the Boston AI Music Meetup on March 19, 2026, bringing together researchers, musicians, and technologists from the local community to explore the intersection of artificial intelligence and music. The event featured talks on emerging approaches in AI-driven audio and creative tools, including a presentation by Elena Georgieva (NYU MARL) on improving audio quality for singing and speech using CLAP-based methods, as well as a talk by Ashvala Vinay (NoneType) on creative workflows using infinite canvas systems. Following the presentations, attendees participated in a networking session, fostering discussion and collaboration across academia and industry.
The Boston AI Music Meetup has been held monthly since 2024 (including a presentation on MERL’s music source separation work in May 2025), and has grown to include over 1,200 subscribers, attracting attendees from across the Northeast. It provides a forum for knowledge exchange and collaboration within the rapidly evolving AI music ecosystem, with discussions spanning music information retrieval, generative AI, and machine learning for creative practice.
- MERL hosted the Boston AI Music Meetup on March 19, 2026, bringing together researchers, musicians, and technologists from the local community to explore the intersection of artificial intelligence and music. The event featured talks on emerging approaches in AI-driven audio and creative tools, including a presentation by Elena Georgieva (NYU MARL) on improving audio quality for singing and speech using CLAP-based methods, as well as a talk by Ashvala Vinay (NoneType) on creative workflows using infinite canvas systems. Following the presentations, attendees participated in a networking session, fostering discussion and collaboration across academia and industry.
See All News & Events for Speech & Audio -
-
Research Highlights
-
Internships
-
SA0307: Internship - Neural Spatial Audio Processing
-
SA0302: Internship - Audio Processing for Moving Sounds
-
CV0075: Internship - Multimodal Embodied AI
See All Internships for Speech & Audio -
-
Openings
-
CI0177: Postdoctoral Research Fellow - Agentic AI
-
SA0297: Postdoctoral Research Fellow - AI for Science
See All Openings at MERL -
-
Recent Publications
- , "Technical Report for MERL’s Real-TSE Challenge Submission," Tech. Rep. TR2026-112, Mitsubishi Electric Research Laboratories, July 2026.BibTeX TR2026-112 PDF
- @techreport{Klement2026jul2,
- author = {Klement, Dominik and Masuyama, Yoshiki and Boeddeker, Christoph and Saijo, Kohei and Richter, Julius and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{Technical Report for MERL’s Real-TSE Challenge Submission}},
- institution = {Real-TSE Challenge},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-112}
- }
- , "The MERL Systems for DCASE 2026 Challenge Task 2," Tech. Rep. TR2026-100, IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), June 2026.BibTeX TR2026-100 PDF
- @techreport{Fujimura2026jun,
- author = {{Fujimura, Takuya and Wichern, Gordon and Masuyama, Yoshiki and Boeddeker, Christoph and Saijo, Kohei and Richter, Julius and Edo, Takahiro and Le Roux, Jonathan}},
- title = {{The MERL Systems for DCASE 2026 Challenge Task 2}},
- institution = {IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-100}
- }
- , "The MERL Systems for DCASE 2026 Challenge Task 4," Tech. Rep. TR2026-098, IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), June 2026.BibTeX TR2026-098 PDF
- @techreport{Saijo2026jun,
- author = {{Saijo, Kohei and Masuyama, Yoshiki and Boeddeker, Christoph and Wichern, Gordon and Richter, Julius and Edo, Takahiro and Le Roux, Jonathan}},
- title = {{The MERL Systems for DCASE 2026 Challenge Task 4}},
- institution = {IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-098}
- }
- , "Exploring Disentangled Neural Speech Codecs from Self-Supervised Representations", IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), DOI: 10.1109/ICASSP55912.2026.11462776, May 2026, pp. 21992-21996.BibTeX TR2026-035 PDF
- @inproceedings{Aihara2026may2,
- author = {Aihara, Ryo and Masuyama, Yoshiki and Germain, François G and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{Exploring Disentangled Neural Speech Codecs from Self-Supervised Representations}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW)},
- year = 2026,
- pages = {21992--21996},
- month = may,
- doi = {10.1109/ICASSP55912.2026.11462776},
- url = {https://www.merl.com/publications/TR2026-035}
- }
- , "SUNAC: Source-aware Unified Neural Audio Codec", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), DOI: 10.1109/ICASSP55912.2026.11461849, May 2026, pp. 14427-14431.BibTeX TR2026-032 PDF
- @inproceedings{Aihara2026may,
- author = {Aihara, Ryo and Masuyama, Yoshiki and Paissan, Francesco and Germain, François G and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{SUNAC: Source-aware Unified Neural Audio Codec}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2026,
- pages = {14427--14431},
- month = may,
- doi = {10.1109/ICASSP55912.2026.11461849},
- url = {https://www.merl.com/publications/TR2026-032}
- }
- , "Spatially Aware Self-Supervised Models for Multi-Channel Neural Speaker Diarization", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), DOI: 10.1109/ICASSP55912.2026.11463023, May 2026, pp. 17447-17451.BibTeX TR2026-047 PDF
- @inproceedings{Han2026may,
- author = {Han, Jiangyu and Wang, Ruoyu and Masuyama, Yoshiki and Delcroix, Marc and Rohdin, Johan and Du, Jun and Burget, Lukáš},
- title = {{Spatially Aware Self-Supervised Models for Multi-Channel Neural Speaker Diarization}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2026,
- pages = {17447--17451},
- month = may,
- doi = {10.1109/ICASSP55912.2026.11463023},
- url = {https://www.merl.com/publications/TR2026-047}
- }
- , "Velocity Potential Neural Field for Efficient Ambisonics Impulse Response Modeling", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), DOI: 10.1109/ICASSP55912.2026.11460631, May 2026, pp. 22582-22586.BibTeX TR2026-033 PDF
- @inproceedings{Masuyama2026may,
- author = {Masuyama, Yoshiki and Germain, François G and Wichern, Gordon and Hori, Chiori and {Le Roux}, Jonathan},
- title = {{Velocity Potential Neural Field for Efficient Ambisonics Impulse Response Modeling}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2026,
- pages = {22582--22586},
- month = may,
- doi = {10.1109/ICASSP55912.2026.11460631},
- url = {https://www.merl.com/publications/TR2026-033}
- }
- , "FlexIO: Flexible Single- and Multi-Channel Speech Separation and Enhancement", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), DOI: 10.1109/ICASSP55912.2026.11462393, May 2026, pp. 14417-14421.BibTeX TR2026-034 PDF
- @inproceedings{Masuyama2026may2,
- author = {Masuyama, Yoshiki and Saijo, Kohei and Paissan, Francesco and Han, Jiangyu and Delcroix, Marc and Aihara, Ryo and Germain, François G and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{FlexIO: Flexible Single- and Multi-Channel Speech Separation and Enhancement}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2026,
- pages = {14417--14421},
- month = may,
- doi = {10.1109/ICASSP55912.2026.11462393},
- url = {https://www.merl.com/publications/TR2026-034}
- }
- , "Technical Report for MERL’s Real-TSE Challenge Submission," Tech. Rep. TR2026-112, Mitsubishi Electric Research Laboratories, July 2026.
-
Videos
-
Software & Data Downloads
-
Embracing Cacophony -
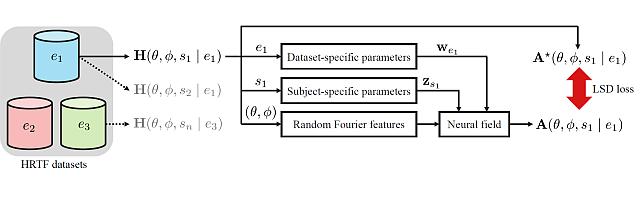
Subject- and Dataset-Aware Neural Field for HRTF Modeling -
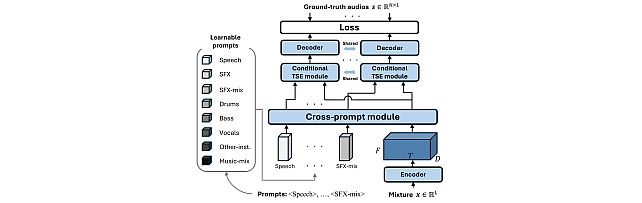
Task-Aware Unified Source Separation -
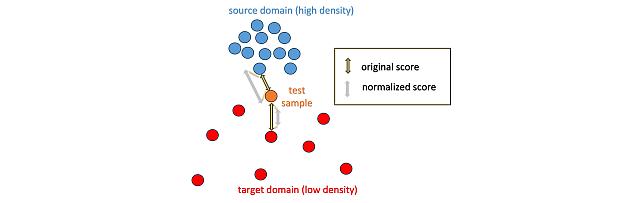
Local Density-Based Anomaly Score Normalization for Domain Generalization -
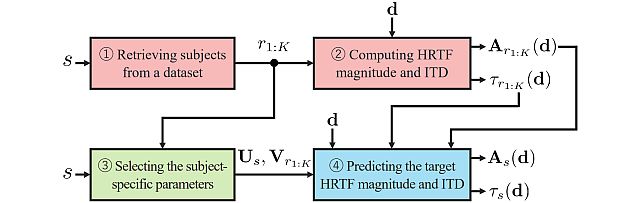
Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization -
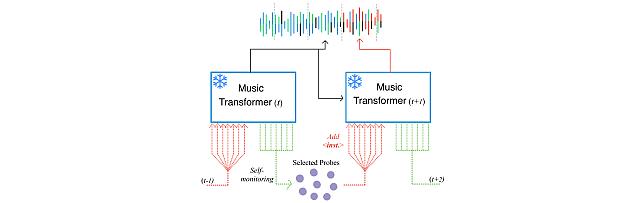
Self-Monitored Inference-Time INtervention for Generative Music Transformers -
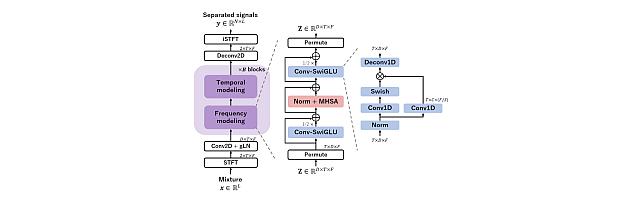
Transformer-based model with LOcal-modeling by COnvolution -
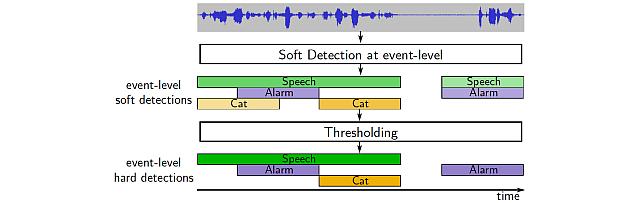
Sound Event Bounding Boxes -
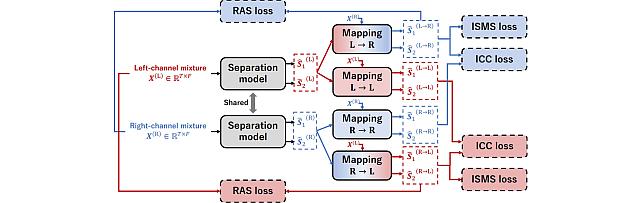
Enhanced Reverberation as Supervision -
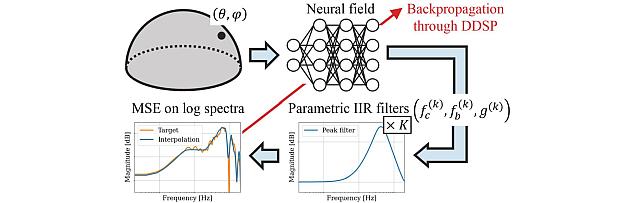
Neural IIR Filter Field for HRTF Upsampling and Personalization -
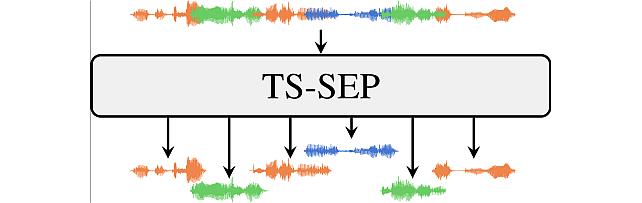
Target-Speaker SEParation -
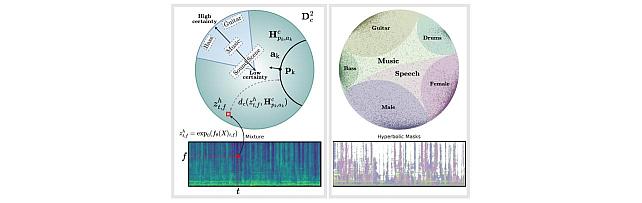
Hyperbolic Audio Source Separation -
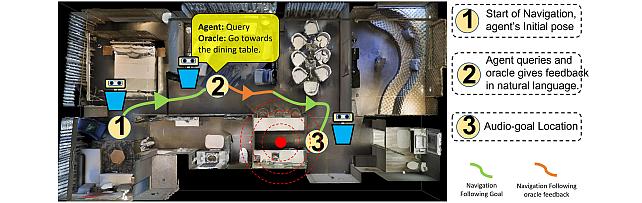
Audio-Visual-Language Embodied Navigation in 3D Environments -
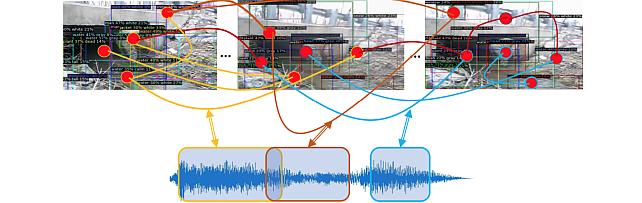
Audio Visual Scene-Graph Segmentor -
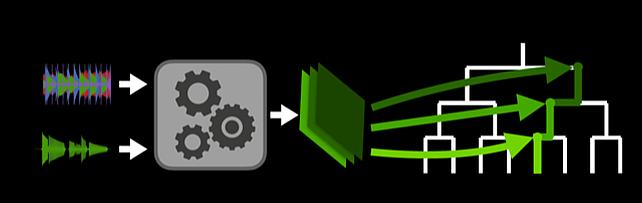
Hierarchical Musical Instrument Separation -
Non-negative Dynamical System model
-
















