Kuan-Chuan Peng

- Phone: 617-621-7576
- Email:
-
Position:
Research / Technical Staff
Principal Research Scientist -
Education:
Ph.D., Cornell University, 2016 -
Research Areas:
External Links:
Kuan-Chuan's Quick Links
-
Biography
Before joining MERL, he was a Research Scientist (2016-2018) and Staff Scientist (2019) at Siemens Corporate Technology. His PhD research focuses on solving abstract tasks in computer vision using convolutional neural networks. In addition to his PhD, he received a bachelor's degree in Electrical Engineering and an MS degree in Computer Science and Information Engineering from National Taiwan University in 2009 and 2012 respectively. His research interests include incremental learning, developing practical solutions given biased or scarce data, and fundamental computer vision and machine learning problems.
-
Recent News & Events
-
NEWS MERL Presents 4 Main Conference Papers and 6 Workshop Papers at ICML 2026 Date: July 6, 2026 - July 11, 2026
Where: COEX, Seoul, South Korea
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Stefano Di Cairano; Toshiaki Koike-Akino; Christopher R. Laughman; Jing Liu; Suhas Lohit; Kuan-Chuan Peng; Alexander Schperberg; Ye Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Computer Vision, Machine Learning, Signal ProcessingBrief- MERL researchers are proud to present 4 main conference papers and 6 workshop papers at ICML 2026. ICML, taking place from July 6-11 in Seoul, South Korea, is a premier international conference in machine learning.
Main Conference Papers with MERL Authors:
1. Understanding Dynamic Compute Allocation in Recurrent Transformers by Ibraheem Muhammad Moosa, Suhas Lohit, Ye Wang, Moitreya Chatterjee, and Wenpeng Yin.
2. LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior by Qinhong Zhou, Chuang Gan, and Anoop Cherian.
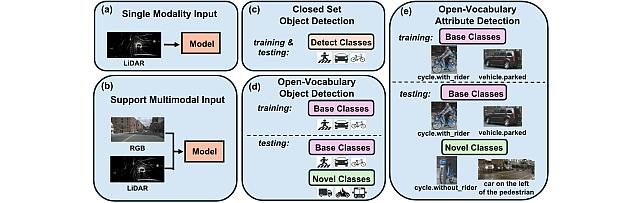
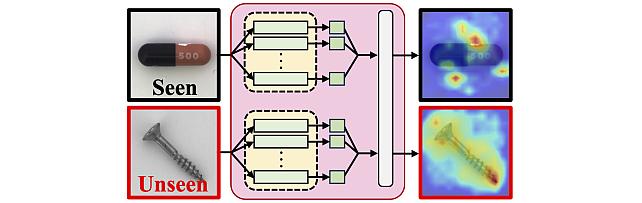
3. Memory-Distilled Selection for Noise-Robust Anomaly Detection by Sirojbek Safarov, Jaewoo Park, Yoon G. Jung, Kuan-Chuan Peng, Wonchul Kim, Seongdeok Bang, and Octavia Camps.
4. Partial Ring Scan: Revisiting Scan Order in Vision State Space Models by Yi-Kuan Hsieh, Kuan-Chuan Peng, Xin Li, Ming-Ching Chang, Yu-Chee Tseng, and Jun-Wei Hsieh.
Workshop Papers with MERL Authors:
1. WISE: Weighted Iterative Society-of-Experts for Multimodal Multi-Agent Debate with Probabilistic Consensus by Anoop Cherian, Suhas Lohit, and Kuan-Chuan Peng. (Workshop on Scalable Learning and Optimization for Efficient Multimodal AI Agents (SCALE))
2. MIRROR: Multisensory Implicit Rejection-sampled RObotic policy by Amisha Bhaskar, Pratap Tokekar, Stefano Di Cairano, and Alexander Schperberg. (Workshop on Structured Probabilistic Inference & Generative Modeling)
3. Reinforced Neural Processes: Memory-Efficient Time-Series Forecasting with a World-Feedback-Trained Memory Policy by Nibraas Khan, Gordon Wichern, and Christopher R. Laughman. (Workshop on Reinforcement Learning from World Feedback (RLxF))
4. Connecting Low-Rank Adapters and Policy Stability in GRPO Fine-Tuning by Antonin Rottman, Francesco Tonin, Yongtao Wu, Toshiaki Koike-Akino, and Volkan Cevher. (Workshop on Connecting Low-rank Representations in AI (CoLorAI))
5. EinSort: Sorting is All We Need for Tensorizing LLM by Toshiaki Koike-Akino, Jing Liu, and Ye Wang. (Workshop on Connecting Low-rank Representations in AI (CoLorAI))
6. Temper and Tilt Lead to SLOP: Reward Hacking Mitigation with Inference-Time Alignment by Ye Wang, and Jing Liu, and Toshiaki Koike-Akino. (Workshop on Agents in the Wild: Safety, Security, and Beyond)
- MERL researchers are proud to present 4 main conference papers and 6 workshop papers at ICML 2026. ICML, taking place from July 6-11 in Seoul, South Korea, is a premier international conference in machine learning.
-
NEWS MERL Presents 7 Papers and 2 Workshops at CVPR 2026 Date: June 3, 2026 - June 7, 2026
Where: Colorado Convention Center, Denver, Colorado
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Kaen Kogashi; Suhas Lohit; Lalit Manam; Tim K. Marks; Pedro Miraldo; Kuan-Chuan Peng
Research Areas: Artificial Intelligence, Computer Vision, Machine LearningBrief- MERL researchers are proud to present 7 papers, including two highlight papers (top 3.6% of submissions), and 2 workshops at CVPR 2026. CVPR, taking place from June 3-7 in Denver, CO, USA, is a premier international conference in computer vision.
Papers with MERL Authors:
1. Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting by Xinhang Liu, Pedro Miraldo, Suhas Lohit, Huaizu Jiang, Naoko Sawada, Yu-Wing Tai, Chi-Keung Tang, and Moitreya Chatterjee (Highlight Paper)
2. Parallel Rigidity Matters for Bundle Adjustment by Lalit Manam and Venu Govindu (Highlight Paper)
3. Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling by Valter Piedade, Lalit Manam, Masashi Yamazaki, and Pedro Miraldo
4. AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects by Danrui Li, Jiahao Zhang, Bernhard Egger, Moitreya Chatterjee, Suhas Lohit, Tim K. Marks, and Anoop Cherian
5. LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction by Tianye Ding, Yiming Xie, Yiqing Liang, Moitreya Chatterjee, Pedro Miraldo, and Huaizu Jiang
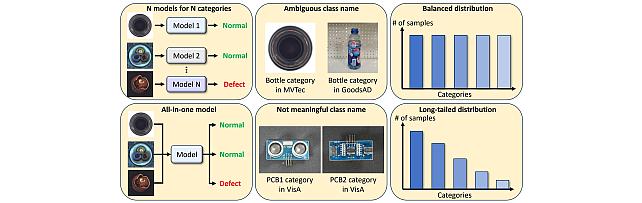
6. SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification by Jun-Wei Hsieh, Ying-Hsuan Wu, Yi-Kuan Hsieh, Xin Li, Kuan-Chuan Peng, Ming-Ching Chang (CVPR Findings paper)
7. MMHOI: Complex 3D Multi-Human-Object Interaction Understanding by Kaen Kogashi and Anoop Cherian (PhysHuman Workshop paper)
Workshops Co-Organized by MERL:
1. Multimodal Algorithmic Reasoning Workshop by Anoop Cherian, Suhas Lohit, Kuan-Chuan Peng, Honglu Zhou, Kevin Smith, and Josh Tenenbaum
2. The Third Workshop on Anomaly Detection with Foundation Models by Kuan-Chuan Peng, Ying Zhao, and Abhishek Aich
- MERL researchers are proud to present 7 papers, including two highlight papers (top 3.6% of submissions), and 2 workshops at CVPR 2026. CVPR, taking place from June 3-7 in Denver, CO, USA, is a premier international conference in computer vision.
See All News & Events for Kuan-Chuan -
-
Research Highlights
-
MERL Publications
- , "Partial Ring Scan: Revisiting Scan Order in Vision State Space Models", International Conference on Machine Learning (ICML), July 2026.BibTeX TR2026-091 PDF
- @inproceedings{Hsieh2026jul,
- author = {Hsieh, Yi-Kuan and Peng, Kuan-Chuan and Li, Xin and Chang, Ming-Ching and Tseng, Yu-Chee and Hsieh, Jun-Wei},
- title = {{Partial Ring Scan: Revisiting Scan Order in Vision State Space Models}},
- booktitle = {International Conference on Machine Learning (ICML)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-091}
- }
- , "Memory-Distilled Selection for Noise-Robust Anomaly Detection", International Conference on Machine Learning (ICML), July 2026.BibTeX TR2026-089 PDF
- @inproceedings{Safarov2026jul,
- author = {{Safarov, Sirojbek and Park, Jaewoo and Jung, Yoon G. and Peng, Kuan-Chuan and Kim, Wonchul and Bang, Seongdeok and Camps, Octavia}},
- title = {{Memory-Distilled Selection for Noise-Robust Anomaly Detection}},
- booktitle = {International Conference on Machine Learning (ICML)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-089}
- }
- , "WISE: Weighted Iterative Society-of-Experts for Multimodal Multi-Agent Debate with Probabilistic Consensus", ICML SCALE AI Workshop, June 2026.BibTeX TR2026-083 PDF
- @inproceedings{Cherian2026jun,
- author = {Cherian, Anoop and Lohit, Suhas and Peng, Kuan-Chuan},
- title = {{WISE: Weighted Iterative Society-of-Experts for Multimodal Multi-Agent Debate with Probabilistic Consensus}},
- booktitle = {ICML SCALE AI Workshop},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-083}
- }
- , "SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification", CVPR Findings, June 2026.BibTeX TR2026-075 PDF
- @inproceedings{Hsieh2026jun2,
- author = {Hsieh, Jun-Wei and Wu, Ying-Hsuan and Hsieh, Yi-Kuan and Li, Xin and Peng, Kuan-Chuan and Chang, Ming-Ching},
- title = {{SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification}},
- booktitle = {CVPR Findings},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-075}
- }
- , "SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification Supplementary Material", CVPR Findings, June 2026.BibTeX TR2026-074 PDF
- @inproceedings{Hsieh2026jun,
- author = {Hsieh, Jun-Wei and Wu, Ying-Hsuan and Hsieh, Yi-Kuan and Li, Xin and Peng, Kuan-Chuan and Chang, Ming-Ching},
- title = {{SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification Supplementary Material}},
- booktitle = {CVPR Findings},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-074}
- }
- , "Partial Ring Scan: Revisiting Scan Order in Vision State Space Models", International Conference on Machine Learning (ICML), July 2026.
-
Other Publications
- , "Learning without Memorizing", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.BibTeX
- @Inproceedings{Dhar_CVPR19,
- author = {Dhar, Prithviraj and Singh, Rajat Vikram and Peng, Kuan-Chuan and Wu, Ziyan and Chellappa, Rama},
- title = {Learning without Memorizing},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2019
- }
- , "Guided Attention Inference Network", IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2019.BibTeX
- @Article{Li_TPAMI19,
- author = {Li, Kunpeng and Wu, Ziyan and Peng, Kuan-Chuan and Ernst, Jan and Fu, Yun},
- title = {Guided Attention Inference Network},
- journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
- year = 2019,
- publisher = {IEEE}
- }
- , "Sharpen Focus: Learning with Attention Separability and Consistency", IEEE International Conference on Computer Vision (ICCV), 2019.BibTeX
- @Inproceedings{Wang_ICCV19,
- author = {Wang, Lezi and Wu, Ziyan and Karanam, Srikrishna and Peng, Kuan-Chuan and Singh, Rajat Vikram and Liu, Bo and Metaxas, Dimitris N.},
- title = {Sharpen Focus: Learning with Attention Separability and Consistency},
- booktitle = {IEEE International Conference on Computer Vision (ICCV)},
- year = 2019
- }
- , "Learning Compositional Visual Concepts with Mutual Consistency", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.BibTeX
- @Inproceedings{Gong_CVPR18,
- author = {Gong, Yunye and Karanam, Srikrishna and Wu, Ziyan and Peng, Kuan-Chuan and Ernst, Jan and Doerschuk, Peter C.},
- title = {Learning Compositional Visual Concepts with Mutual Consistency},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2018
- }
- , "Tell Me Where to Look: Guided Attention Inference Network", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.BibTeX
- @Inproceedings{Li_CVPR18,
- author = {Li, Kunpeng and Wu, Ziyan and Peng, Kuan-Chuan and Ernst, Jan and Fu, Yun},
- title = {Tell Me Where to Look: Guided Attention Inference Network},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2018
- }
- , "Zero-Shot Deep Domain Adaptation", European Conference on Computer Vision (ECCV), 2018.BibTeX
- @Inproceedings{Peng_ECCV18,
- author = {Peng, Kuan-Chuan and Wu, Ziyan and Ernst, Jan},
- title = {Zero-Shot Deep Domain Adaptation},
- booktitle = {European Conference on Computer Vision (ECCV)},
- year = 2018
- }
- , "Where Do Emotions Come from? Predicting the Emotion Stimuli Map", IEEE International Conference on Image Processing (ICIP), 2016.BibTeX
- @Inproceedings{Peng_ICIP16,
- author = {Peng, Kuan-Chuan and Chen, Tsuhan and Sadovnik, Amir and Gallagher, Andrew C.},
- title = {Where Do Emotions Come from? Predicting the Emotion Stimuli Map},
- booktitle = {IEEE International Conference on Image Processing (ICIP)},
- year = 2016
- }
- , "Toward Correlating and Solving Abstract Tasks Using Convolutional Neural Networks", IEEE Winter Conference on Applications of Computer Vision (WACV), 2016.BibTeX
- @Inproceedings{Peng_WACV16,
- author = {Peng, Kuan-Chuan and Chen, Tsuhan},
- title = {Toward Correlating and Solving Abstract Tasks Using Convolutional Neural Networks},
- booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)},
- year = 2016
- }
- , "A Mixed Bag of Emotions: Model, Predict, and Transfer Emotion Distributions", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.BibTeX
- @Inproceedings{Peng_CVPR15,
- author = {Peng, Kuan-Chuan and Chen, Tsuhan and Sadovnik, Amir and Gallagher, Andrew C.},
- title = {A Mixed Bag of Emotions: Model, Predict, and Transfer Emotion Distributions},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2015
- }
- , "Cross-layer Features in Convolutional Neural Networks for Generic Classification Tasks", IEEE International Conference on Image Processing (ICIP), 2015.BibTeX
- @Inproceedings{Peng_ICIP15,
- author = {Peng, Kuan-Chuan and Chen, Tsuhan},
- title = {Cross-layer Features in Convolutional Neural Networks for Generic Classification Tasks},
- booktitle = {IEEE International Conference on Image Processing (ICIP)},
- year = 2015
- }
- , "A Framework of Extracting Multi-scale Features Using Multiple Convolutional Neural Network", IEEE International Conference on Multimedia and Expo (ICME), 2015.BibTeX
- @Inproceedings{Peng_ICME15,
- author = {Peng, Kuan-Chuan and Chen, Tsuhan},
- title = {A Framework of Extracting Multi-scale Features Using Multiple Convolutional Neural Network},
- booktitle = {IEEE International Conference on Multimedia and Expo (ICME)},
- year = 2015
- }
- , "A Framework of Changing Image Emotion Using Emotion Prediction", IEEE International Conference on Image Processing (ICIP), 2014.BibTeX
- @Inproceedings{Peng_ICIP14,
- author = {Peng, Kuan-Chuan and Karlsson, Kolbeinn and Chen, Tsuhan and Zhang, Dongqing and Yu, Hong Heather},
- title = {A Framework of Changing Image Emotion Using Emotion Prediction},
- booktitle = {IEEE International Conference on Image Processing (ICIP)},
- year = 2014
- }
- , "Incorporating Cloud Distribution in Sky Representation", IEEE International Conference on Computer Vision (ICCV), 2013.BibTeX
- @Inproceedings{Peng_ICCV13,
- author = {Peng, Kuan-Chuan and Chen, Tsuhan},
- title = {Incorporating Cloud Distribution in Sky Representation},
- booktitle = {IEEE International Conference on Computer Vision (ICCV)},
- year = 2013
- }
- , "Learning without Memorizing", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
-
Software & Data Downloads
-
Videos
-
MERL Issued Patents
-
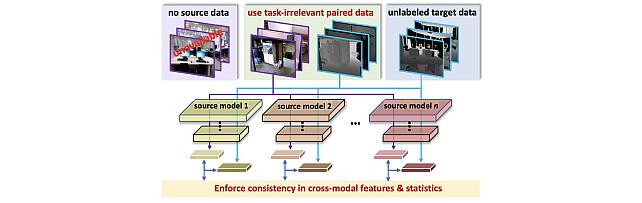
Title: "System and Method for Cross-Modal Knowledge Transfer Without Task-Relevant Source Data"
Inventors: Lohit, Suhas; Ahmed, Sk Miraj; Peng, Kuan-Chuan; Jones, Michael J.
Patent No.: 12,511,549
Issue Date: Dec 30, 2025 -
Title: "Method and System for Zero-Shot Cross Domain Video Anomaly Detection"
Inventors: Peng, Kuan-Chuan; Aich, Abhishek
Patent No.: 12,315,242
Issue Date: May 27, 2025 -
Title: "Contactless Elevator Service for an Elevator Based on Augmented Datasets"
Inventors: Sahinoglu, Zafer; Peng, Kuan-Chuan; Sullivan, Alan; Yerazunis, William S.
Patent No.: 12,071,323
Issue Date: Aug 27, 2024
-
Title: "System and Method for Cross-Modal Knowledge Transfer Without Task-Relevant Source Data"