AWARD MERL team wins the Audio-Visual Speech Enhancement (AVSE) 2023 Challenge
Date released: December 16, 2023
-
AWARD MERL team wins the Audio-Visual Speech Enhancement (AVSE) 2023 Challenge Date:
December 16, 2023
Awarded to:
Zexu Pan, Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux
-
Description:
MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
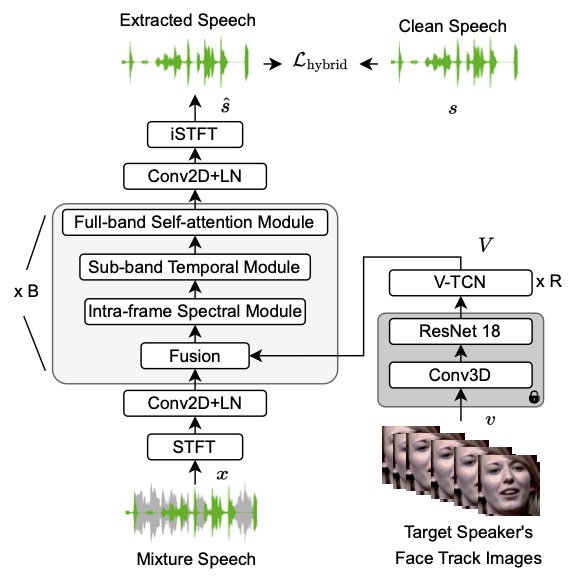
The AVSE challenge aims to design better speech enhancement systems by harnessing the visual aspects of speech (such as lip movements and gestures) in a manner similar to the brain’s multi-modal integration strategies. MERL’s system was a scenario-aware audio-visual TF-GridNet, that incorporates the face recording of a target speaker as a conditioning factor and also recognizes whether the predominant interference signal is speech or background noise. In addition to outperforming all competing systems in terms of objective metrics by a wide margin, in a listening test, MERL’s model achieved the best overall word intelligibility score of 84.54%, compared to 57.56% for the baseline and 80.41% for the next best team. The Fisher’s least significant difference (LSD) was 2.14%, indicating that our model offered statistically significant speech intelligibility improvements compared to all other systems. -
MERL Contacts:
-
External Link:
-
Research Areas:
-
Related Publications
- , "Scenario-Aware Audio-Visual TF-GridNet for Target Speech Extraction", IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), DOI: 10.1109/ASRU57964.2023.10389618, December 2023.
BibTeX TR2023-152 PDF Video- @inproceedings{Pan2023dec2,
- author = {Pan, Zexu and Wichern, Gordon and Masuyama, Yoshiki and Germain, François G and Khurana, Sameer and Hori, Chiori and {Le Roux}, Jonathan},
- title = {{Scenario-Aware Audio-Visual TF-GridNet for Target Speech Extraction}},
- booktitle = {IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU)},
- year = 2023,
- month = dec,
- doi = {10.1109/ASRU57964.2023.10389618},
- isbn = {979-8-3503-0689-7},
- url = {https://www.merl.com/publications/TR2023-152}
- }
- , "Scenario-Aware Audio-Visual TF-GridNet for Target Speech Extraction", IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), DOI: 10.1109/ASRU57964.2023.10389618, December 2023.
-



