TR2025-162
Towards Open-Vocabulary Multimodal 3D Object Detection with Attributes
-
- , "Towards Open-Vocabulary Multimodal 3D Object Detection with Attributes", British Machine Vision Conference (BMVC), November 2025.BibTeX TR2025-162 PDF Video Data Presentation
- @inproceedings{Xiang2025nov,
- author = {{{Xiang, Xinhao and Peng, Kuan-Chuan and Lohit, Suhas and Jones, Michael J. and Zhang, Jiawei}}},
- title = {{{Towards Open-Vocabulary Multimodal 3D Object Detection with Attributes}}},
- booktitle = {British Machine Vision Conference (BMVC)},
- year = 2025,
- month = nov,
- url = {https://www.merl.com/publications/TR2025-162}
- }
- , "Towards Open-Vocabulary Multimodal 3D Object Detection with Attributes", British Machine Vision Conference (BMVC), November 2025.
-
MERL Contacts:
-
Research Areas:



Abstract:
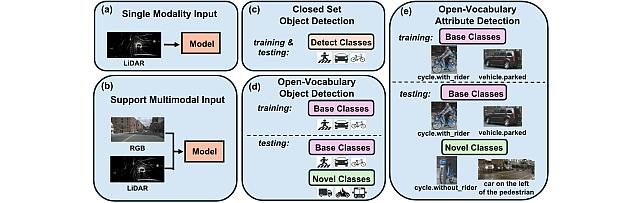
3D object detection plays a crucial role in autonomous systems, yet existing methods are limited by closed-set assumptions and struggle to recognize novel objects and their attributes in real-world scenarios. We propose OVODA, a novel framework enabling both open-vocabulary 3D object and attribute detection with no need to know the novel class anchor size. OVODA uses foundation models to bridge the semantic gap between 3D features and texts while jointly detecting attributes, e.g., spatial relationships, motion states, etc. To facilitate such research direction, we propose OVAD, a new dataset that supplements existing 3D object detection benchmarks with comprehensive attribute annotations. OVODA incorporates several key innovations, including foundation model feature concatenation, prompt tuning strategies, and specialized techniques for attribute detection, including perspective-specified prompts and horizontal flip augmentation. Our results on both the nuScenes and Argoverse 2 datasets show that under the condition of no given anchor sizes of novel classes, OVODA outperforms the state-of-the-art methods in open-vocabulary 3D object detection while successfully recognizing object attributes. Our OVAD dataset is released here.
Software & Data Downloads
Related Video
Related Publication
- @article{Xiang2025aug,
- author = {Xiang, Xinhao and Peng, Kuan-Chuan and Lohit, Suhas and Jones, Michael J. and Zhang, Jiawei},
- title = {{Towards Open-Vocabulary Multimodal 3D Object Detection with Attributes}},
- journal = {arXiv},
- year = 2025,
- month = aug,
- url = {https://arxiv.org/abs/2508.16812}
- }