Computer Vision
Extracting meaning and building representations of visual objects and events in the world.
Our main research themes cover the areas of deep learning and artificial intelligence for object and action detection, classification and scene understanding, robotic vision and object manipulation, 3D processing and computational geometry, as well as simulation of physical systems to enhance machine learning systems.
Quick Links
-
Researchers

Anoop
Cherian

Tim K.
Marks

Michael J.
Jones

Chiori
Hori

Suhas
Lohit

Jonathan
Le Roux

Matthew
Brand

Moitreya
Chatterjee

Hassan
Mansour

Kuan-Chuan
Peng

Siddarth
Jain

Devesh K.
Jha

Diego
Romeres

Radu
Corcodel

Pedro
Miraldo

Ye
Wang

Petros T.
Boufounos

Daniel N.
Nikovski

Anthony
Vetro

Gordon
Wichern

Dehong
Liu

William S.
Yerazunis

François
Germain

Toshiaki
Koike-Akino

Arvind
Raghunathan

Avishai
Weiss

Stefano
Di Cairano

Abraham P.
Vinod

Yanting
Ma

Yoshiki
Masuyama

Philip V.
Orlik

Joshua
Rapp

Naoko
Sawada

Huifang
Sun

Pu
(Perry)
Wang
Yebin
Wang

Kenji
Inomata

Huaizu
Jiang

Jing
Liu

Alexander
Schperberg
-
Awards
-
AWARD Best Paper - Honorable Mention Award at WACV 2021 Date: January 6, 2021
Awarded to: Rushil Anirudh, Suhas Lohit, Pavan Turaga
MERL Contact: Suhas Lohit
Research Areas: Computational Sensing, Computer Vision, Machine LearningBrief- A team of researchers from Mitsubishi Electric Research Laboratories (MERL), Lawrence Livermore National Laboratory (LLNL) and Arizona State University (ASU) received the Best Paper Honorable Mention Award at WACV 2021 for their paper "Generative Patch Priors for Practical Compressive Image Recovery".
The paper proposes a novel model of natural images as a composition of small patches which are obtained from a deep generative network. This is unlike prior approaches where the networks attempt to model image-level distributions and are unable to generalize outside training distributions. The key idea in this paper is that learning patch-level statistics is far easier. As the authors demonstrate, this model can then be used to efficiently solve challenging inverse problems in imaging such as compressive image recovery and inpainting even from very few measurements for diverse natural scenes.
- A team of researchers from Mitsubishi Electric Research Laboratories (MERL), Lawrence Livermore National Laboratory (LLNL) and Arizona State University (ASU) received the Best Paper Honorable Mention Award at WACV 2021 for their paper "Generative Patch Priors for Practical Compressive Image Recovery".
-
AWARD MERL Researchers win Best Paper Award at ICCV 2019 Workshop on Statistical Deep Learning in Computer Vision Date: October 27, 2019
Awarded to: Abhinav Kumar, Tim K. Marks, Wenxuan Mou, Chen Feng, Xiaoming Liu
MERL Contact: Tim K. Marks
Research Areas: Artificial Intelligence, Computer Vision, Machine LearningBrief- MERL researcher Tim Marks, former MERL interns Abhinav Kumar and Wenxuan Mou, and MERL consultants Professor Chen Feng (NYU) and Professor Xiaoming Liu (MSU) received the Best Oral Paper Award at the IEEE/CVF International Conference on Computer Vision (ICCV) 2019 Workshop on Statistical Deep Learning in Computer Vision (SDL-CV) held in Seoul, Korea. Their paper, entitled "UGLLI Face Alignment: Estimating Uncertainty with Gaussian Log-Likelihood Loss," describes a method which, given an image of a face, estimates not only the locations of facial landmarks but also the uncertainty of each landmark location estimate.
-
AWARD CVPR 2011 Longuet-Higgins Prize Date: June 25, 2011
Awarded to: Paul A. Viola and Michael J. Jones
Awarded for: "Rapid Object Detection using a Boosted Cascade of Simple Features"
Awarded by: Conference on Computer Vision and Pattern Recognition (CVPR)
MERL Contact: Michael J. Jones
Research Area: Machine LearningBrief- Paper from 10 years ago with the largest impact on the field: "Rapid Object Detection using a Boosted Cascade of Simple Features", originally published at Conference on Computer Vision and Pattern Recognition (CVPR 2001).
See All Awards for MERL -
-
News & Events
-
NEWS MERL Papers and Workshops at CVPR 2025 Date: June 11, 2025 - June 15, 2025
Where: Nashville, TN, USA
MERL Contacts: Matthew Brand; Moitreya Chatterjee; Anoop Cherian; François Germain; Michael J. Jones; Toshiaki Koike-Akino; Jing Liu; Suhas Lohit; Tim K. Marks; Pedro Miraldo; Kuan-Chuan Peng; Naoko Sawada; Pu (Perry) Wang; Ye Wang
Research Areas: Artificial Intelligence, Computer Vision, Machine Learning, Signal Processing, Speech & AudioBrief- MERL researchers are presenting 2 conference papers, co-organizing two workshops, and presenting 7 workshop papers at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2025 conference, which will be held in Nashville, TN, USA from June 11-15, 2025. CVPR is one of the most prestigious and competitive international conferences in the area of computer vision. Details of MERL contributions are provided below:
Main Conference Papers:
1. "UWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing" by Y.H. Lai, J. Ebbers, Y. F. Wang, F. Germain, M. J. Jones, M. Chatterjee
This work deals with the task of weakly‑supervised Audio-Visual Video Parsing (AVVP) and proposes a novel, uncertainty-aware algorithm called UWAV towards that end. UWAV works by producing more reliable segment‑level pseudo‑labels while explicitly weighting each label by its prediction uncertainty. This uncertainty‑aware training, combined with a feature‑mixup regularization scheme, promotes inter‑segment consistency in the pseudo-labels. As a result, UWAV achieves state‑of‑the‑art performance on two AVVP datasets across multiple metrics, demonstrating both effectiveness and strong generalizability.
Paper: https://www.merl.com/publications/TR2025-072
2. "TailedCore: Few-Shot Sampling for Unsupervised Long-Tail Noisy Anomaly Detection" by Y. G. Jung, J. Park, J. Yoon, K.-C. Peng, W. Kim, A. B. J. Teoh, and O. Camps.
This work tackles unsupervised anomaly detection in complex scenarios where normal data is noisy and has an unknown, imbalanced class distribution. Existing models face a trade-off between robustness to noise and performance on rare (tail) classes. To address this, the authors propose TailSampler, which estimates class sizes from embedding similarities to isolate tail samples. Using TailSampler, they develop TailedCore, a memory-based model that effectively captures tail class features while remaining noise-robust, outperforming state-of-the-art methods in extensive evaluations.
paper: https://www.merl.com/publications/TR2025-077
MERL Co-Organized Workshops:
1. Multimodal Algorithmic Reasoning (MAR) Workshop, organized by A. Cherian, K.-C. Peng, S. Lohit, H. Zhou, K. Smith, L. Xue, T. K. Marks, and J. Tenenbaum.
Workshop link: https://marworkshop.github.io/cvpr25/
2. The 6th Workshop on Fair, Data-Efficient, and Trusted Computer Vision, organized by N. Ratha, S. Karanam, Z. Wu, M. Vatsa, R. Singh, K.-C. Peng, M. Merler, and K. Varshney.
Workshop link: https://fadetrcv.github.io/2025/
Workshop Papers:
1. "FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations" by N. Sawada, P. Miraldo, S. Lohit, T.K. Marks, and M. Chatterjee (Oral)
With their ability to model object surfaces in a scene as a continuous function, neural implicit surface reconstruction methods have made remarkable strides recently, especially over classical 3D surface reconstruction methods, such as those that use voxels or point clouds. Towards this end, we propose FreBIS - a neural implicit‑surface framework that avoids overloading a single encoder with every surface detail. It divides a scene into several frequency bands and assigns a dedicated encoder (or group of encoders) to each band, then enforces complementary feature learning through a redundancy‑aware weighting module. Swapping this frequency‑stratified stack into an off‑the‑shelf reconstruction pipeline markedly boosts 3D surface accuracy and view‑consistent rendering on the challenging BlendedMVS dataset.
paper: https://www.merl.com/publications/TR2025-074
2. "Multimodal 3D Object Detection on Unseen Domains" by D. Hegde, S. Lohit, K.-C. Peng, M. J. Jones, and V. M. Patel.
LiDAR-based object detection models often suffer performance drops when deployed in unseen environments due to biases in data properties like point density and object size. Unlike domain adaptation methods that rely on access to target data, this work tackles the more realistic setting of domain generalization without test-time samples. We propose CLIX3D, a multimodal framework that uses both LiDAR and image data along with supervised contrastive learning to align same-class features across domains and improve robustness. CLIX3D achieves state-of-the-art performance across various domain shifts in 3D object detection.
paper: https://www.merl.com/publications/TR2025-078
3. "Improving Open-World Object Localization by Discovering Background" by A. Singh, M. J. Jones, K.-C. Peng, M. Chatterjee, A. Cherian, and E. Learned-Miller.
This work tackles open-world object localization, aiming to detect both seen and unseen object classes using limited labeled training data. While prior methods focus on object characterization, this approach introduces background information to improve objectness learning. The proposed framework identifies low-information, non-discriminative image regions as background and trains the model to avoid generating object proposals there. Experiments on standard benchmarks show that this method significantly outperforms previous state-of-the-art approaches.
paper: https://www.merl.com/publications/TR2025-058
4. "PF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector" by K. Li, T. Zhang, K.-C. Peng, and G. Wang.
This work addresses challenges in 3D object detection for autonomous driving by improving the fusion of LiDAR and camera data, which is often hindered by domain gaps and limited labeled data. Leveraging advances in foundation models and prompt engineering, the authors propose PF3Det, a multi-modal detector that uses foundation model encoders and soft prompts to enhance feature fusion. PF3Det achieves strong performance even with limited training data. It sets new state-of-the-art results on the nuScenes dataset, improving NDS by 1.19% and mAP by 2.42%.
paper: https://www.merl.com/publications/TR2025-076
5. "Noise Consistency Regularization for Improved Subject-Driven Image Synthesis" by Y. Ni., S. Wen, P. Konius, A. Cherian
Fine-tuning Stable Diffusion enables subject-driven image synthesis by adapting the model to generate images containing specific subjects. However, existing fine-tuning methods suffer from two key issues: underfitting, where the model fails to reliably capture subject identity, and overfitting, where it memorizes the subject image and reduces background diversity. To address these challenges, two auxiliary consistency losses are porposed for diffusion fine-tuning. First, a prior consistency regularization loss ensures that the predicted diffusion noise for prior (non- subject) images remains consistent with that of the pretrained model, improving fidelity. Second, a subject consistency regularization loss enhances the fine-tuned model’s robustness to multiplicative noise modulated latent code, helping to preserve subject identity while improving diversity. Our experimental results demonstrate the effectiveness of our approach in terms of image diversity, outperforming DreamBooth in terms of CLIP scores, background variation, and overall visual quality.
paper: https://www.merl.com/publications/TR2025-073
6. "LatentLLM: Attention-Aware Joint Tensor Compression" by T. Koike-Akino, X. Chen, J. Liu, Y. Wang, P. Wang, M. Brand
We propose a new framework to convert a large foundation model such as large language models (LLMs)/large multi- modal models (LMMs) into a reduced-dimension latent structure. Our method uses a global attention-aware joint tensor decomposition to significantly improve the model efficiency. We show the benefit on several benchmark including multi-modal reasoning tasks.
paper: https://www.merl.com/publications/TR2025-075
7. "TuneComp: Joint Fine-Tuning and Compression for Large Foundation Models" by T. Koike-Akino, X. Chen, J. Liu, Y. Wang, P. Wang, M. Brand
To reduce model size during post-training, compression methods, including knowledge distillation, low-rank approximation, and pruning, are often applied after fine- tuning the model. However, sequential fine-tuning and compression sacrifices performance, while creating a larger than necessary model as an intermediate step. In this work, we aim to reduce this gap, by directly constructing a smaller model while guided by the downstream task. We propose to jointly fine-tune and compress the model by gradually distilling it to a pruned low-rank structure. Experiments demonstrate that joint fine-tuning and compression significantly outperforms other sequential compression methods.
paper: https://www.merl.com/publications/TR2025-079
- MERL researchers are presenting 2 conference papers, co-organizing two workshops, and presenting 7 workshop papers at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2025 conference, which will be held in Nashville, TN, USA from June 11-15, 2025. CVPR is one of the most prestigious and competitive international conferences in the area of computer vision. Details of MERL contributions are provided below:
-
NEWS MERL contributes to ICRA 2025 Date: May 19, 2025 - May 23, 2025
Where: IEEE ICRA
MERL Contacts: Stefano Di Cairano; Jianlin Guo; Chiori Hori; Siddarth Jain; Devesh K. Jha; Toshiaki Koike-Akino; Philip V. Orlik; Arvind Raghunathan; Diego Romeres; Yuki Shirai; Abraham P. Vinod; Yebin Wang
Research Areas: Artificial Intelligence, Computer Vision, Control, Dynamical Systems, Machine Learning, Optimization, Robotics, Human-Computer InteractionBrief- MERL made significant contributions to both the organization and the technical program of the International Conference on Robotics and Automation (ICRA) 2025, which was held in Atlanta, Georgia, USA, from May 19th to May 23rd.
MERL was a Bronze sponsor of the conference, and MERL researchers chaired four sessions in the areas of Manipulation Planning, Human-Robot Collaboration, Diffusion Policy, and Learning for Robot Control.
MERL researchers presented four papers in the main conference on the topics of contact-implicit trajectory optimization, proactive robotic assistance in human-robot collaboration, diffusion policy with human preferences, and dynamic and model learning of robotic manipulators. In addition, five more papers were presented in the workshops: “Structured Learning for Efficient, Reliable, and Transparent Robots,” “Safely Leveraging Vision-Language Foundation Models in Robotics: Challenges and Opportunities,” “Long-term Human Motion Prediction,” and “The Future of Intelligent Manufacturing: From Innovation to Implementation.”
MERL researcher Diego Romeres delivered an invited talk titled “Dexterous Robotics: From Multimodal Sensing to Real-World Physical Interactions.”
MERL also collaborated with the University of Padua on one of the conference’s challenges: the “3rd AI Olympics with RealAIGym” (https://ai-olympics.dfki-bremen.de).
During the conference, MERL researchers received the IEEE Transactions on Automation Science and Engineering Best New Application Paper Award for their paper titled “Smart Actuation for End-Edge Industrial Control Systems.”
About ICRA
The IEEE International Conference on Robotics and Automation (ICRA) is the flagship conference of the IEEE Robotics and Automation Society and the world’s largest and most comprehensive technical conference focused on research advances and the latest technological developments in robotics. The event attracts over 7,000 participants, 143 partners and exhibitors, and receives more than 4,000 paper submissions.
- MERL made significant contributions to both the organization and the technical program of the International Conference on Robotics and Automation (ICRA) 2025, which was held in Atlanta, Georgia, USA, from May 19th to May 23rd.
See All News & Events for Computer Vision -
-
Research Highlights
-
PS-NeuS: A Probability-guided Sampler for Neural Implicit Surface Rendering -
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models -
Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-Aware Spatio-Temporal Sampling -
Steered Diffusion -
Robust Machine Learning -
Video Anomaly Detection -
MERL Shopping Dataset -
Point-Plane SLAM
-
-
Internships
-
ST0096: Internship - Multimodal Tracking and Imaging
MERL is seeking a motivated intern to assist in developing hardware and algorithms for multimodal imaging applications. The project involves integration of radar, camera, and depth sensors in a variety of sensing scenarios. The ideal candidate should have experience with FMCW radar and/or depth sensing, and be fluent in Python and scripting methods. Familiarity with optical tracking of humans and experience with hardware prototyping is desired. Good knowledge of computational imaging and/or radar imaging methods is a plus.
Required Specific Experience
- Experience with Python and Python Deep Learning Frameworks.
- Experience with FMCW radar and/or Depth Sensors.
-
CV0063: Internship - Visual Simultaneous Localization and Mapping
MERL is looking for a self-motivated graduate student to work on Visual Simultaneous Localization and Mapping (V-SLAM). Based on the candidate’s interests, the intern can work on a variety of topics such as (but not limited to): camera pose estimation, feature detection and matching, visual-LiDAR data fusion, pose-graph optimization, loop closure detection, and image-based camera relocalization. The ideal candidate would be a PhD student with a strong background in 3D computer vision and good programming skills in C/C++ and/or Python. The candidate must have published at least one paper in a top-tier computer vision, machine learning, or robotics venue, such as CVPR, ECCV, ICCV, NeurIPS, ICRA, or IROS. The intern will collaborate with MERL researchers to derive and implement new algorithms for V-SLAM, conduct experiments, and report findings. A submission to a top-tier conference is expected. The duration of the internship and start date are flexible.
Required Specific Experience
- Experience with 3D Computer Vision and Simultaneous Localization & Mapping.
-
CA0153: Internship - High-Fidelity Visualization and Simulation for Space Applications
MERL is seeking a highly motivated graduate student to develop high-fidelity full-stack GNC simulators for space applications. The ideal candidate has strong experience with rendering engines, synthetic image generation, and computer vision, as well as familiarity with spacecraft dynamics, motion planning, and state estimation. The developed software should allow for closed-loop execution with the synthetic imagery, and ideally allow for real-time visualization. Publication of results produced during the internship is desired. The expected duration of the internship is 3-6 months with a flexible start date.
Required Specific Experience
- Current enrollment in a graduate program in Aerospace, Computer Science, Robotics, Mechanical, Electrical Engineering, or a related field
-
Experience with one or more of Blender, Unreal, Unity, along with their APIs
-
Strong programming skills in one or more of Matlab, Python, and/or C/C++
See All Internships for Computer Vision -
-
Openings
See All Openings at MERL -
Recent Publications
- , "State Representation Learning for Visual Servo Control", European Control Conference (ECC), June 2025.BibTeX TR2025-094 PDF
- @inproceedings{Wang2025jun,
- author = {Wang, Jen-Wei and Nikovski, Daniel N.},
- title = {{State Representation Learning for Visual Servo Control}},
- booktitle = {European Control Conference (ECC)},
- year = 2025,
- month = jun,
- url = {https://www.merl.com/publications/TR2025-094}
- }
- , "Multimodal 3D Object Detection on Unseen Domains", IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshop, June 2025.BibTeX TR2025-078 PDF
- @inproceedings{Hegde2025jun,
- author = {Hegde, Deepti and Lohit, Suhas and Peng, Kuan-Chuan and Jones, Michael J. and Patel, Vishal M.},
- title = {{Multimodal 3D Object Detection on Unseen Domains}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshop},
- year = 2025,
- month = jun,
- url = {https://www.merl.com/publications/TR2025-078}
- }
- , "TailedCore: Few-Shot Sampling for Unsupervised Long-Tail Noisy Anomaly Detection", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2025.BibTeX TR2025-077 PDF Video Presentation
- @inproceedings{Jung2025jun,
- author = {{{Jung, Yoon G. and Park, Jaewoo and Yoon, Jaeho and Peng, Kuan-Chuan and Kim, Wonchul and Teoh, Andrew B. J. and Camps, Octavia}}},
- title = {{{TailedCore: Few-Shot Sampling for Unsupervised Long-Tail Noisy Anomaly Detection}}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2025,
- month = jun,
- url = {https://www.merl.com/publications/TR2025-077}
- }
- , "UWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2025.BibTeX TR2025-072 PDF
- @inproceedings{Lai2025jun,
- author = {Lai, Yung-Hsuan and Ebbers, Janek and Wang, Yu-Chiang Frank and Germain, François G and Jones, Michael J. and Chatterjee, Moitreya},
- title = {{UWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2025,
- month = jun,
- url = {https://www.merl.com/publications/TR2025-072}
- }
- , "PF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector", IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshop, June 2025.BibTeX TR2025-076 PDF Presentation
- @inproceedings{Li2025jun,
- author = {{{Li, Kaidong and Zhang, Tianxiao and Peng, Kuan-Chuan and Wang, Guanghui}}},
- title = {{{PF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector}}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshop},
- year = 2025,
- month = jun,
- url = {https://www.merl.com/publications/TR2025-076}
- }
- , "Noise Consistency Regularization for Improved Subject-Driven Image Synthesis", IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR), June 2025.BibTeX TR2025-073 PDF
- @inproceedings{Ni2025jun,
- author = {Ni, Yao and Wen, Song and Koniusz, Piotr and Cherian, Anoop},
- title = {{Noise Consistency Regularization for Improved Subject-Driven Image Synthesis}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR)},
- year = 2025,
- month = jun,
- url = {https://www.merl.com/publications/TR2025-073}
- }
- , "FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations", IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR), June 2025.BibTeX TR2025-074 PDF
- @inproceedings{Sawada2025jun,
- author = {Sawada, Naoko and Miraldo, Pedro and Lohit, Suhas and Marks, Tim K. and Chatterjee, Moitreya},
- title = {{FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR)},
- year = 2025,
- month = jun,
- url = {https://www.merl.com/publications/TR2025-074}
- }
- , "KitchenVLA: Iterative Vision-Language Corrections for Robotic Execution of Human Tasks", IEEE International Conference on Robotics and Automation Workshop on Safely Leveraging Vision-Language Foundation Models in Robotics (SafeLVMs@ICRA), May 2025.BibTeX TR2025-068 PDF
- @inproceedings{Lu2025may,
- author = {Lu, Kai and Ma, Chenyang and Hori, Chiori and Romeres, Diego},
- title = {{KitchenVLA: Iterative Vision-Language Corrections for Robotic Execution of Human Tasks}},
- booktitle = {IEEE International Conference on Robotics and Automation Workshop on Safely Leveraging Vision-Language Foundation Models in Robotics (SafeLVMs@ICRA)},
- year = 2025,
- month = may,
- url = {https://www.merl.com/publications/TR2025-068}
- }
- , "State Representation Learning for Visual Servo Control", European Control Conference (ECC), June 2025.
-
Videos
-
Software & Data Downloads
-
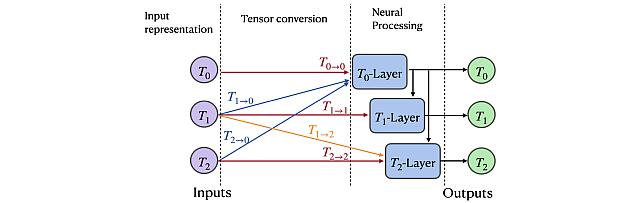
Group Representation Networks -
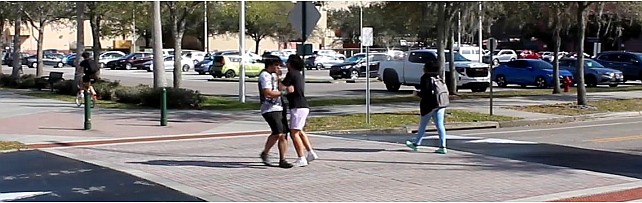
ComplexVAD Dataset -
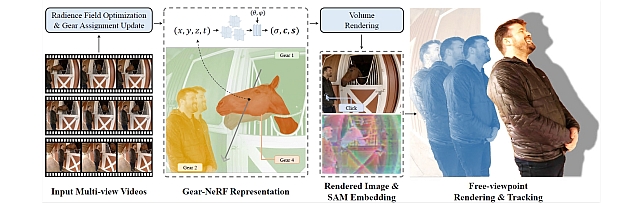
Gear Extensions of Neural Radiance Fields -
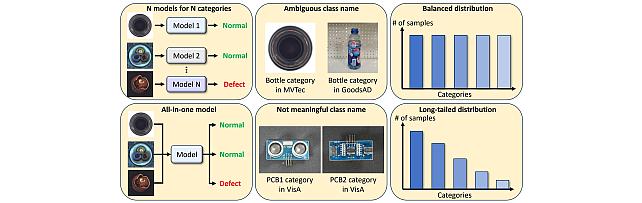
Long-Tailed Anomaly Detection Dataset -

Pixel-Grounded Prototypical Part Networks -

Steered Diffusion -

BAyesian Network for adaptive SAmple Consensus -
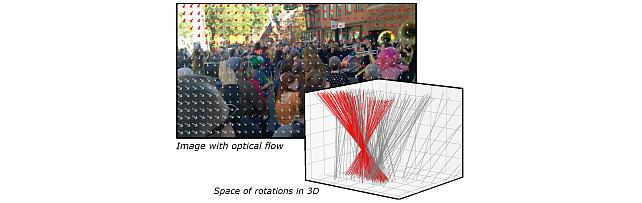
Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes
-
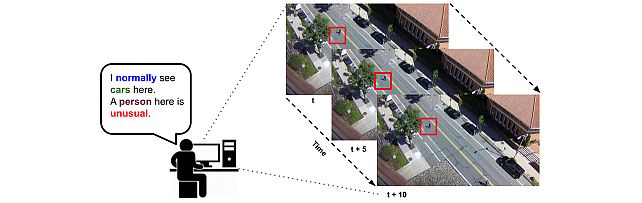
Explainable Video Anomaly Localization -

Simple Multimodal Algorithmic Reasoning Task Dataset -
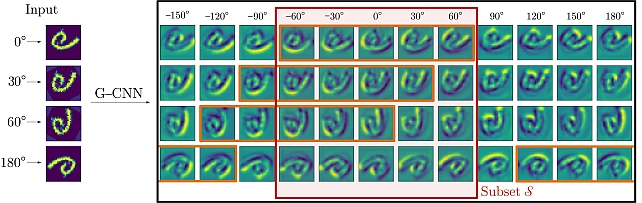
Partial Group Convolutional Neural Networks -
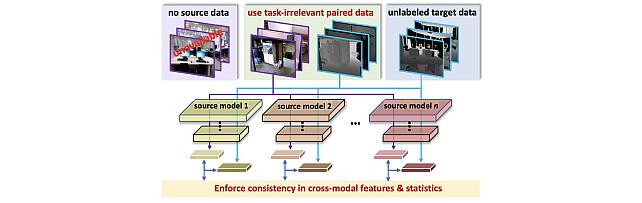
SOurce-free Cross-modal KnowledgE Transfer -
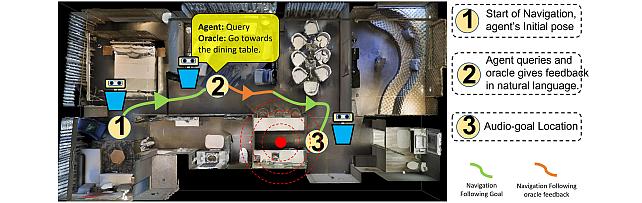
Audio-Visual-Language Embodied Navigation in 3D Environments -

3D MOrphable STyleGAN -
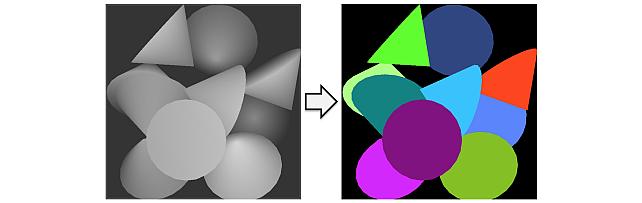
Instance Segmentation GAN -
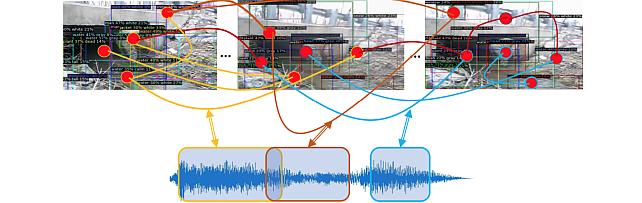
Audio Visual Scene-Graph Segmentor -
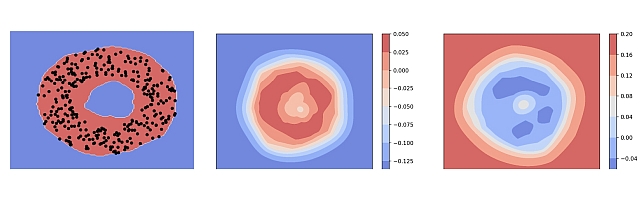
Generalized One-class Discriminative Subspaces -

Generating Visual Dynamics from Sound and Context -

Adversarially-Contrastive Optimal Transport -
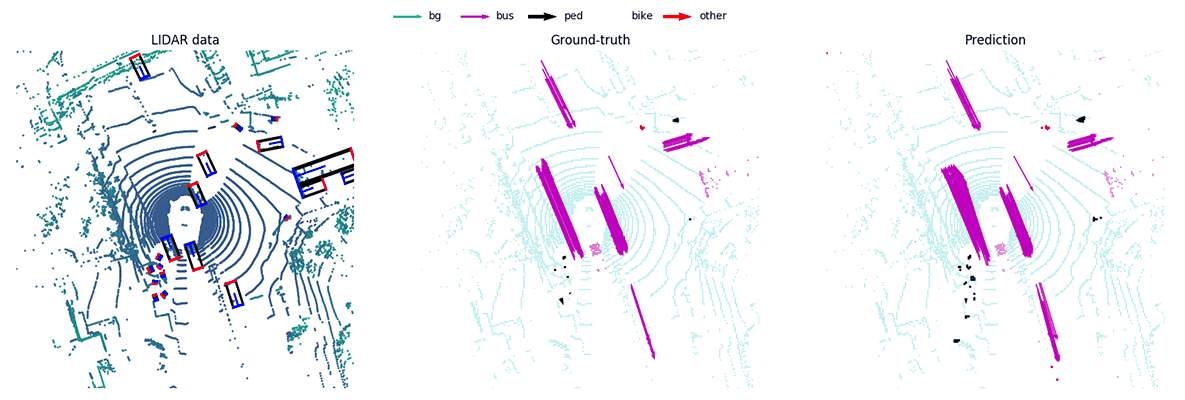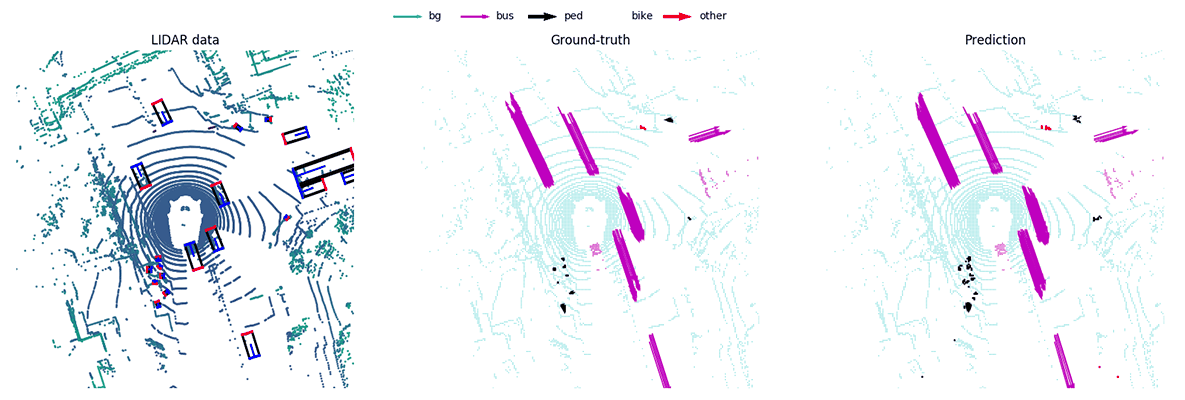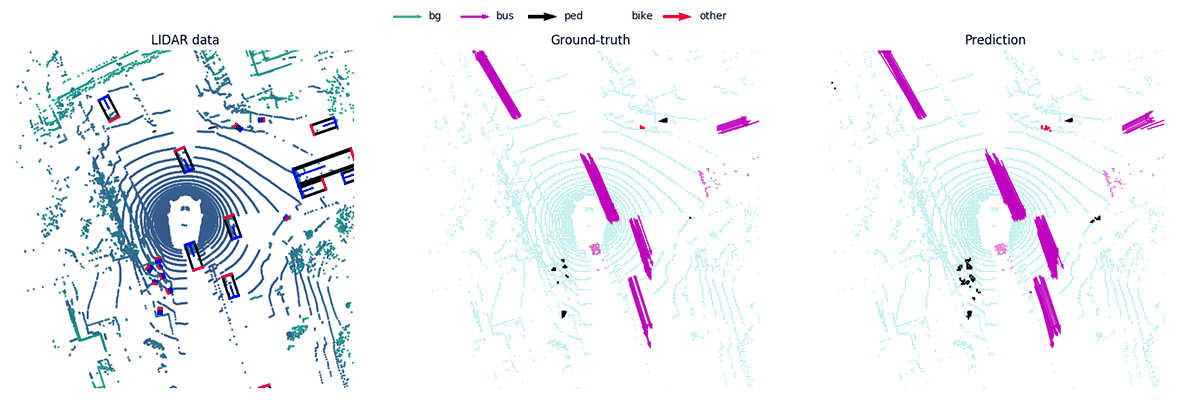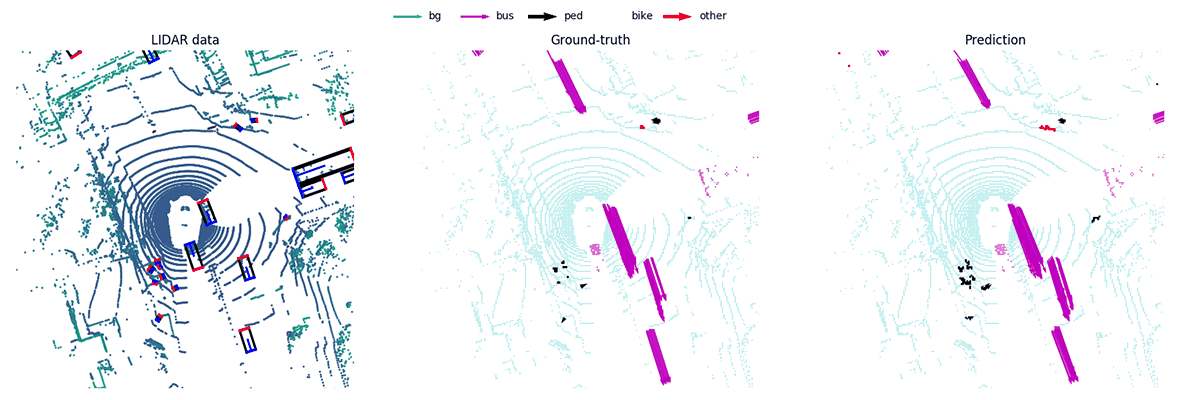
MotionNet -

Street Scene Dataset -

FoldingNet++ -
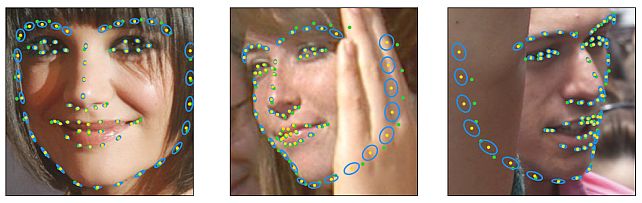
Landmarks’ Location, Uncertainty, and Visibility Likelihood -
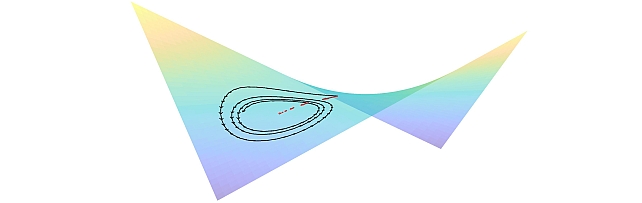
Gradient-based Nikaido-Isoda -
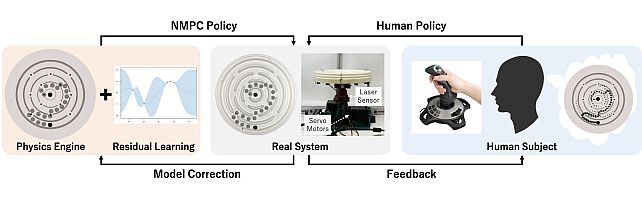
Circular Maze Environment -

Discriminative Subspace Pooling -
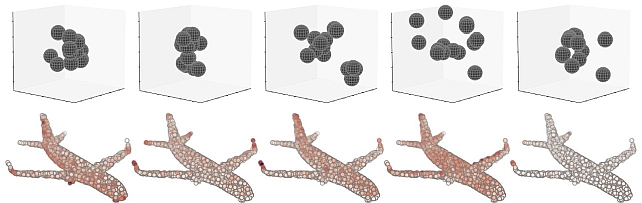
Kernel Correlation Network -

Fast Resampling on Point Clouds via Graphs -
FoldingNet -

MERL Shopping Dataset -

Joint Geodesic Upsampling -

Plane Extraction using Agglomerative Clustering
-