Jonathan Le Roux

- Phone: 617-621-7547
- Email:
-
Position:
Research / Technical Staff
Distinguished Research Scientist,
Senior Team Leader,
IEEE Fellow -
Education:
Ph.D., University of Tokyo, 2009 -
Research Areas:
- Speech & Audio
- Artificial Intelligence
- Machine Learning
- Computer Vision
- Human-Computer Interaction
- Robotics
- Signal Processing
- Information Security
External Links:
Jonathan's Quick Links
-
Biography
Jonathan completed his B.Sc. and M.Sc. in Mathematics at the École Normale Supérieure in Paris, France. Before joining MERL in 2011, he spent several years in Beijing and Tokyo. In Tokyo he worked as a postdoctoral researcher at NTT's Communication Science Laboratories. His research interests are in signal processing and machine learning applied to speech and audio.
-
Recent News & Events
-
EVENT MERL Contributes to ICASSP 2024 Date: Sunday, April 14, 2024 - Friday, April 19, 2024
Location: Seoul, South Korea
MERL Contacts: Petros T. Boufounos; François Germain; Chiori Hori; Sameer Khurana; Toshiaki Koike-Akino; Jonathan Le Roux; Hassan Mansour; Zexu Pan; Kieran Parsons; Joshua Rapp; Anthony Vetro; Pu (Perry) Wang; Gordon Wichern; Ryoma Yataka
Research Areas: Artificial Intelligence, Computational Sensing, Machine Learning, Robotics, Signal Processing, Speech & AudioBrief- MERL has made numerous contributions to both the organization and technical program of ICASSP 2024, which is being held in Seoul, Korea from April 14-19, 2024.
Sponsorship and Awards
MERL is proud to be a Bronze Patron of the conference and will participate in the student job fair on Thursday, April 18. Please join this session to learn more about employment opportunities at MERL, including openings for research scientists, post-docs, and interns.
MERL is pleased to be the sponsor of two IEEE Awards that will be presented at the conference. We congratulate Prof. Stéphane G. Mallat, the recipient of the 2024 IEEE Fourier Award for Signal Processing, and Prof. Keiichi Tokuda, the recipient of the 2024 IEEE James L. Flanagan Speech and Audio Processing Award.
Jonathan Le Roux, MERL Speech and Audio Senior Team Leader, will also be recognized during the Awards Ceremony for his recent elevation to IEEE Fellow.
Technical Program
MERL will present 13 papers in the main conference on a wide range of topics including automated audio captioning, speech separation, audio generative models, speech and sound synthesis, spatial audio reproduction, multimodal indoor monitoring, radar imaging, depth estimation, physics-informed machine learning, and integrated sensing and communications (ISAC). Three workshop papers have also been accepted for presentation on audio-visual speaker diarization, music source separation, and music generative models.
Perry Wang is the co-organizer of the Workshop on Signal Processing and Machine Learning Advances in Automotive Radars (SPLAR), held on Sunday, April 14. It features keynote talks from leaders in both academia and industry, peer-reviewed workshop papers, and lightning talks from ICASSP regular tracks on signal processing and machine learning for automotive radar and, more generally, radar perception.
Gordon Wichern will present an invited keynote talk on analyzing and interpreting audio deep learning models at the Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA), held on Monday, April 15. He will also appear in a panel discussion on interpretable audio AI at the workshop.
Perry Wang also co-organizes a two-part special session on Next-Generation Wi-Fi Sensing (SS-L9 and SS-L13) which will be held on Thursday afternoon, April 18. The special session includes papers on PHY-layer oriented signal processing and data-driven deep learning advances, and supports upcoming 802.11bf WLAN Sensing Standardization activities.
Petros Boufounos is participating as a mentor in ICASSP’s Micro-Mentoring Experience Program (MiME).
About ICASSP
ICASSP is the flagship conference of the IEEE Signal Processing Society, and the world's largest and most comprehensive technical conference focused on the research advances and latest technological development in signal and information processing. The event attracts more than 3000 participants.
- MERL has made numerous contributions to both the organization and technical program of ICASSP 2024, which is being held in Seoul, Korea from April 14-19, 2024.
-
NEWS MERL co-organizes the 2023 Sound Demixing (SDX2023) Challenge and Workshop Date: January 23, 2023 - November 4, 2023
Where: International Symposium of Music Information Retrieval (ISMR)
MERL Contacts: Jonathan Le Roux; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL Speech & Audio team members Gordon Wichern and Jonathan Le Roux co-organized the 2023 Sound Demixing Challenge along with researchers from Sony, Moises AI, Audioshake, and Meta.
The SDX2023 Challenge was hosted on the AI Crowd platform and had a prize pool of $42,000 distributed to the winning teams across two tracks: Music Demixing and Cinematic Sound Demixing. A unique aspect of this challenge was the ability to test the audio source separation models developed by challenge participants on non-public songs from Sony Music Entertainment Japan for the music demixing track, and movie soundtracks from Sony Pictures for the cinematic sound demixing track. The challenge ran from January 23rd to May 1st, 2023, and had 884 participants distributed across 68 teams submitting 2828 source separation models. The winners will be announced at the SDX2023 Workshop, which will take place as a satellite event at the International Symposium of Music Information Retrieval (ISMR) in Milan, Italy on November 4, 2023.
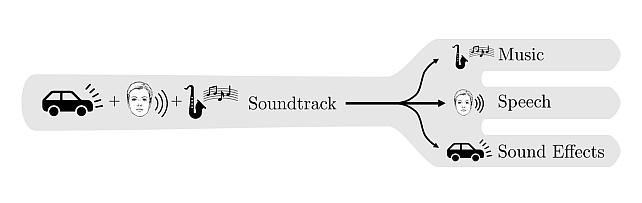
MERL’s contribution to SDX2023 focused mainly on the cinematic demixing track. In addition to sponsoring the prizes awarded to the winning teams for that track, the baseline system and initial training data were MERL’s Cocktail Fork separation model and Divide and Remaster dataset, respectively. MERL researchers also contributed to a Town Hall kicking off the challenge, co-authored a scientific paper describing the challenge outcomes, and co-organized the SDX2023 Workshop.
- MERL Speech & Audio team members Gordon Wichern and Jonathan Le Roux co-organized the 2023 Sound Demixing Challenge along with researchers from Sony, Moises AI, Audioshake, and Meta.
See All News & Events for Jonathan -
-
Awards
-
AWARD Jonathan Le Roux elevated to IEEE Fellow Date: January 1, 2024
Awarded to: Jonathan Le Roux
MERL Contact: Jonathan Le Roux
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL Distinguished Scientist and Speech & Audio Senior Team Leader Jonathan Le Roux has been elevated to IEEE Fellow, effective January 2024, "for contributions to multi-source speech and audio processing."
Mitsubishi Electric celebrated Dr. Le Roux's elevation and that of another researcher from the company, Dr. Shumpei Kameyama, with a worldwide news release on February 15.
Dr. Jonathan Le Roux has made fundamental contributions to the field of multi-speaker speech processing, especially to the areas of speech separation and multi-speaker end-to-end automatic speech recognition (ASR). His contributions constituted a major advance in realizing a practically usable solution to the cocktail party problem, enabling machines to replicate humans’ ability to concentrate on a specific sound source, such as a certain speaker within a complex acoustic scene—a long-standing challenge in the speech signal processing community. Additionally, he has made key contributions to the measures used for training and evaluating audio source separation methods, developing several new objective functions to improve the training of deep neural networks for speech enhancement, and analyzing the impact of metrics used to evaluate the signal reconstruction quality. Dr. Le Roux’s technical contributions have been crucial in promoting the widespread adoption of multi-speaker separation and end-to-end ASR technologies across various applications, including smart speakers, teleconferencing systems, hearables, and mobile devices.
IEEE Fellow is the highest grade of membership of the IEEE. It honors members with an outstanding record of technical achievements, contributing importantly to the advancement or application of engineering, science and technology, and bringing significant value to society. Each year, following a rigorous evaluation procedure, the IEEE Fellow Committee recommends a select group of recipients for elevation to IEEE Fellow. Less than 0.1% of voting members are selected annually for this member grade elevation.
- MERL Distinguished Scientist and Speech & Audio Senior Team Leader Jonathan Le Roux has been elevated to IEEE Fellow, effective January 2024, "for contributions to multi-source speech and audio processing."
-
AWARD MERL team wins the Audio-Visual Speech Enhancement (AVSE) 2023 Challenge Date: December 16, 2023
Awarded to: Zexu Pan, Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux
MERL Contacts: François Germain; Chiori Hori; Sameer Khurana; Jonathan Le Roux; Zexu Pan; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
The AVSE challenge aims to design better speech enhancement systems by harnessing the visual aspects of speech (such as lip movements and gestures) in a manner similar to the brain’s multi-modal integration strategies. MERL’s system was a scenario-aware audio-visual TF-GridNet, that incorporates the face recording of a target speaker as a conditioning factor and also recognizes whether the predominant interference signal is speech or background noise. In addition to outperforming all competing systems in terms of objective metrics by a wide margin, in a listening test, MERL’s model achieved the best overall word intelligibility score of 84.54%, compared to 57.56% for the baseline and 80.41% for the next best team. The Fisher’s least significant difference (LSD) was 2.14%, indicating that our model offered statistically significant speech intelligibility improvements compared to all other systems.
- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
-
AWARD MERL Intern and Researchers Win ICASSP 2023 Best Student Paper Award Date: June 9, 2023
Awarded to: Darius Petermann, Gordon Wichern, Aswin Subramanian, Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Gordon Wichern
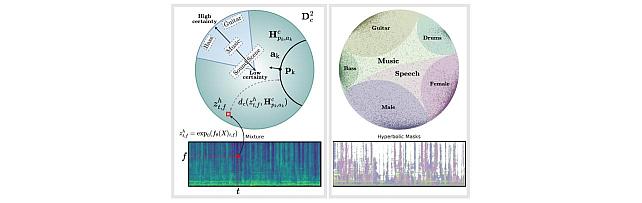
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- Former MERL intern Darius Petermann (Ph.D. Candidate at Indiana University) has received a Best Student Paper Award at the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023) for the paper "Hyperbolic Audio Source Separation", co-authored with MERL researchers Gordon Wichern and Jonathan Le Roux, and former MERL researcher Aswin Subramanian. The paper presents work performed during Darius's internship at MERL in the summer 2022. The paper introduces a framework for audio source separation using embeddings on a hyperbolic manifold that compactly represent the hierarchical relationship between sound sources and time-frequency features. Additionally, the code associated with the paper is publicly available at https://github.com/merlresearch/hyper-unmix.
ICASSP is the flagship conference of the IEEE Signal Processing Society (SPS). ICASSP 2023 was held in the Greek island of Rhodes from June 04 to June 10, 2023, and it was the largest ICASSP in history, with more than 4000 participants, over 6128 submitted papers and 2709 accepted papers. Darius’s paper was first recognized as one of the Top 3% of all papers accepted at the conference, before receiving one of only 5 Best Student Paper Awards during the closing ceremony.
- Former MERL intern Darius Petermann (Ph.D. Candidate at Indiana University) has received a Best Student Paper Award at the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023) for the paper "Hyperbolic Audio Source Separation", co-authored with MERL researchers Gordon Wichern and Jonathan Le Roux, and former MERL researcher Aswin Subramanian. The paper presents work performed during Darius's internship at MERL in the summer 2022. The paper introduces a framework for audio source separation using embeddings on a hyperbolic manifold that compactly represent the hierarchical relationship between sound sources and time-frequency features. Additionally, the code associated with the paper is publicly available at https://github.com/merlresearch/hyper-unmix.
-
AWARD Joint CMU-MERL team wins DCASE2023 Challenge on Automated Audio Captioning Date: June 1, 2023
Awarded to: Shih-Lun Wu, Xuankai Chang, Gordon Wichern, Jee-weon Jung, Francois Germain, Jonathan Le Roux, Shinji Watanabe
MERL Contacts: François Germain; Jonathan Le Roux; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- A joint team consisting of members of CMU Professor and MERL Alumn Shinji Watanabe's WavLab and members of MERL's Speech & Audio team ranked 1st out of 11 teams in the DCASE2023 Challenge's Task 6A "Automated Audio Captioning". The team was led by student Shih-Lun Wu and also featured Ph.D. candidate Xuankai Chang, Postdoctoral research associate Jee-weon Jung, Prof. Shinji Watanabe, and MERL researchers Gordon Wichern, Francois Germain, and Jonathan Le Roux.
The IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), started in 2013, has been organized yearly since 2016, and gathers challenges on multiple tasks related to the detection, analysis, and generation of sound events. This year, the DCASE2023 Challenge received over 428 submissions from 123 teams across seven tasks.
The CMU-MERL team competed in the Task 6A track, Automated Audio Captioning, which aims at generating informative descriptions for various sounds from nature and/or human activities. The team's system made strong use of large pretrained models, namely a BEATs transformer as part of the audio encoder stack, an Instructor Transformer encoding ground-truth captions to derive an audio-text contrastive loss on the audio encoder, and ChatGPT to produce caption mix-ups (i.e., grammatical and compact combinations of two captions) which, together with the corresponding audio mixtures, increase not only the amount but also the complexity and diversity of the training data. The team's best submission obtained a SPIDEr-FL score of 0.327 on the hidden test set, largely outperforming the 2nd best team's 0.315.
- A joint team consisting of members of CMU Professor and MERL Alumn Shinji Watanabe's WavLab and members of MERL's Speech & Audio team ranked 1st out of 11 teams in the DCASE2023 Challenge's Task 6A "Automated Audio Captioning". The team was led by student Shih-Lun Wu and also featured Ph.D. candidate Xuankai Chang, Postdoctoral research associate Jee-weon Jung, Prof. Shinji Watanabe, and MERL researchers Gordon Wichern, Francois Germain, and Jonathan Le Roux.
-
AWARD Best Poster Award and Best Video Award at the International Society for Music Information Retrieval Conference (ISMIR) 2020 Date: October 15, 2020
Awarded to: Ethan Manilow, Gordon Wichern, Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- Former MERL intern Ethan Manilow and MERL researchers Gordon Wichern and Jonathan Le Roux won Best Poster Award and Best Video Award at the 2020 International Society for Music Information Retrieval Conference (ISMIR 2020) for the paper "Hierarchical Musical Source Separation". The conference was held October 11-14 in a virtual format. The Best Poster Awards and Best Video Awards were awarded by popular vote among the conference attendees.
The paper proposes a new method for isolating individual sounds in an audio mixture that accounts for the hierarchical relationship between sound sources. Many sounds we are interested in analyzing are hierarchical in nature, e.g., during a music performance, a hi-hat note is one of many such hi-hat notes, which is one of several parts of a drumkit, itself one of many instruments in a band, which might be playing in a bar with other sounds occurring. Inspired by this, the paper re-frames the audio source separation problem as hierarchical, combining similar sounds together at certain levels while separating them at other levels, and shows on a musical instrument separation task that a hierarchical approach outperforms non-hierarchical models while also requiring less training data. The paper, poster, and video can be seen on the paper page on the ISMIR website.
- Former MERL intern Ethan Manilow and MERL researchers Gordon Wichern and Jonathan Le Roux won Best Poster Award and Best Video Award at the 2020 International Society for Music Information Retrieval Conference (ISMIR 2020) for the paper "Hierarchical Musical Source Separation". The conference was held October 11-14 in a virtual format. The Best Poster Awards and Best Video Awards were awarded by popular vote among the conference attendees.
-
AWARD Best Paper Award at the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) 2019 Date: December 18, 2019
Awarded to: Xuankai Chang, Wangyou Zhang, Yanmin Qian, Jonathan Le Roux, Shinji Watanabe
MERL Contact: Jonathan Le Roux
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL researcher Jonathan Le Roux and co-authors Xuankai Chang, Shinji Watanabe (Johns Hopkins University), Wangyou Zhang, and Yanmin Qian (Shanghai Jiao Tong University) won the Best Paper Award at the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU 2019), for the paper "MIMO-Speech: End-to-End Multi-Channel Multi-Speaker Speech Recognition". MIMO-Speech is a fully neural end-to-end framework that can transcribe the text of multiple speakers speaking simultaneously from multi-channel input. The system is comprised of a monaural masking network, a multi-source neural beamformer, and a multi-output speech recognition model, which are jointly optimized only via an automatic speech recognition (ASR) criterion. The award was received by lead author Xuankai Chang during the conference, which was held in Sentosa, Singapore from December 14-18, 2019.
-
AWARD Best Student Paper Award at IEEE ICASSP 2018 Date: April 17, 2018
Awarded to: Zhong-Qiu Wang
MERL Contact: Jonathan Le Roux
Research Area: Speech & AudioBrief- Former MERL intern Zhong-Qiu Wang (Ph.D. Candidate at Ohio State University) has received a Best Student Paper Award at the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2018) for the paper "Multi-Channel Deep Clustering: Discriminative Spectral and Spatial Embeddings for Speaker-Independent Speech Separation" by Zhong-Qiu Wang, Jonathan Le Roux, and John Hershey. The paper presents work performed during Zhong-Qiu's internship at MERL in the summer 2017, extending MERL's pioneering Deep Clustering framework for speech separation to a multi-channel setup. The award was received on behalf on Zhong-Qiu by MERL researcher and co-author Jonathan Le Roux during the conference, held in Calgary April 15-20.
-
AWARD MERL's Speech Team Achieves World's 2nd Best Performance at the Third CHiME Speech Separation and Recognition Challenge Date: December 15, 2015
Awarded to: John R. Hershey, Takaaki Hori, Jonathan Le Roux and Shinji Watanabe
MERL Contact: Jonathan Le Roux
Research Area: Speech & AudioBrief- The results of the third 'CHiME' Speech Separation and Recognition Challenge were publicly announced on December 15 at the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU 2015) held in Scottsdale, Arizona, USA. MERL's Speech and Audio Team, in collaboration with SRI, ranked 2nd out of 26 teams from Europe, Asia and the US. The task this year was to recognize speech recorded using a tablet in real environments such as cafes, buses, or busy streets. Due to the high levels of noise and the distance from the speaker's mouth to the microphones, this is very challenging task, where the baseline system only achieved 33.4% word error rate. The MERL/SRI system featured state-of-the-art techniques including multi-channel front-end, noise-robust feature extraction, and deep learning for speech enhancement, acoustic modeling, and language modeling, leading to a dramatic 73% reduction in word error rate, down to 9.1%. The core of the system has since been released as a new official challenge baseline for the community to use.
-
AWARD Awaya Prize Young Researcher Award Date: March 11, 2014
Awarded to: Yuuki Tachioka
Awarded for: "Effectiveness of discriminative approaches for speech recognition under noisy environments on the 2nd CHiME Challenge"
Awarded by: Acoustical Society of Japan (ASJ)
MERL Contact: Jonathan Le Roux
Research Area: Speech & AudioBrief- MELCO researcher Yuuki Tachioka received the Awaya Prize Young Researcher Award from the Acoustical Society of Japan (ASJ) for "effectiveness of discriminative approaches for speech recognition under noisy environments on the 2nd CHiME Challenge", which was based on joint work with MERL Speech & Audio team researchers Shinji Watanabe, Jonathan Le Roux and John R. Hershey.
-
AWARD Awaya Prize Young Researcher Award Date: September 26, 2013
Awarded to: Jonathan Le Roux
Awarded for: "A new non-negative dynamical system for speech and audio modeling"
Awarded by: Acoustical Society of Japan (ASJ)
MERL Contact: Jonathan Le Roux
Research Area: Speech & Audio -
AWARD CHiME 2012 Speech Separation and Recognition Challenge Best Performance Date: June 1, 2013
Awarded to: Yuuki Tachioka, Shinji Watanabe, Jonathan Le Roux and John R. Hershey
Awarded for: "Discriminative Methods for Noise Robust Speech Recognition: A CHiME Challenge Benchmark"
Awarded by: International Workshop on Machine Listening in Multisource Environments (CHiME)
MERL Contact: Jonathan Le Roux
Research Area: Speech & AudioBrief- The results of the 2nd 'CHiME' Speech Separation and Recognition Challenge are out! The team formed by MELCO researcher Yuuki Tachioka and MERL Speech & Audio team researchers Shinji Watanabe, Jonathan Le Roux and John Hershey obtained the best results in the continuous speech recognition task (Track 2). This very challenging task consisted in recognizing speech corrupted by highly non-stationary noises recorded in a real living room. Our proposal, which also included a simple yet extremely efficient denoising front-end, focused on investigating and developing state-of-the-art automatic speech recognition back-end techniques: feature transformation methods, as well as discriminative training methods for acoustic and language modeling. Our system significantly outperformed other participants. Our code has since been released as an improved baseline for the community to use.
-
-
Research Highlights
-
MERL Publications
- , "Late Audio-Visual Fusion for In-The-Wild Speaker Diarization", Hands-free Speech Communication and Microphone Arrays (HSCMA), April 2024.BibTeX TR2024-029 PDF
- @inproceedings{Pan2024apr,
- author = {Pan, Zexu and Wichern, Gordon and Germain, François G and Subramanian, Aswin and Le Roux, Jonathan},
- title = {Late Audio-Visual Fusion for In-The-Wild Speaker Diarization},
- booktitle = {Hands-free Speech Communication and Microphone Arrays (HSCMA)},
- year = 2024,
- month = apr,
- url = {https://www.merl.com/publications/TR2024-029}
- }
- , "SMITIN: Self-Monitored Inference-Time INtervention for Generative Music Transformers", arXiv, April 2024.BibTeX arXiv
- @article{Koo2024apr2,
- author = {Koo, Junghyun and Wichern, Gordon and Germain, François G and Khurana, Sameer and Le Roux, Jonathan},
- title = {SMITIN: Self-Monitored Inference-Time INtervention for Generative Music Transformers},
- journal = {arXiv},
- year = 2024,
- month = apr,
- url = {https://arxiv.org/abs/2404.02252}
- }
- , "Understanding and Controlling Generative Music Transformers by Probing Individual Attention Heads", IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA), April 2024.BibTeX TR2024-032 PDF
- @inproceedings{Koo2024apr,
- author = {Koo, Junghyun and Wichern, Gordon and Germain, François G and Khurana, Sameer and Le Roux, Jonathan},
- title = {Understanding and Controlling Generative Music Transformers by Probing Individual Attention Heads},
- booktitle = {IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA)},
- year = 2024,
- month = apr,
- url = {https://www.merl.com/publications/TR2024-032}
- }
- , "Why does music source separation benefit from cacophony?", IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA), March 2024.BibTeX TR2024-030 PDF Video
- @inproceedings{Jeon2024mar,
- author = {Jeon, Chang-Bin and Wichern, Gordon and Germain, François G and Le Roux, Jonathan},
- title = {Why does music source separation benefit from cacophony?},
- booktitle = {IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-030}
- }
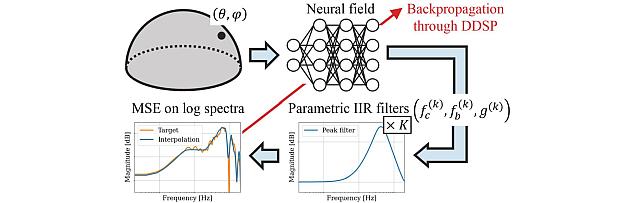
- , "Generation or Replication: Auscultating Audio Latent Diffusion Models", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2024.BibTeX TR2024-027 PDF
- @inproceedings{Bralios2024mar,
- author = {Bralios, Dimitrios and Wichern, Gordon and Germain, François G and Pan, Zexu and Khurana, Sameer and Hori, Chiori and Le Roux, Jonathan},
- title = {Generation or Replication: Auscultating Audio Latent Diffusion Models},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-027}
- }
- , "Late Audio-Visual Fusion for In-The-Wild Speaker Diarization", Hands-free Speech Communication and Microphone Arrays (HSCMA), April 2024.
-
Other Publications
- , "Bayesian Nonparametric Spectrogram Modeling Based on Infinite Factorial Infinite Hidden Markov Model", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), October 2011.BibTeX
- @Inproceedings{Nakano2011WASPAA10,
- author = {Nakano, Masahiro and Le Roux, Jonathan and Kameoka, Hirokazu and Nakamura, Tomohiro and Ono, Nobutaka and Sagayama, Shigeki},
- title = {Bayesian Nonparametric Spectrogram Modeling Based on Infinite Factorial Infinite Hidden Markov Model},
- booktitle = {IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
- year = 2011,
- month = oct
- }
- , "Infinite-State Spectrum Model for Music Signal Analysis", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), May 2011, pp. 1972-1975.BibTeX
- @Inproceedings{Nakano2011ICASSP05,
- author = {Nakano, Masahiro and Le Roux, Jonathan and Kameoka, Hirokazu and Ono, Nobutaka and Sagayama, Shigeki},
- title = {Infinite-State Spectrum Model for Music Signal Analysis},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2011,
- pages = {1972--1975},
- month = may
- }
- , "Computational Auditory Induction as a Missing-Data Model-Fitting Problem with Bregman Divergence", Speech Communication (Special issue on Perceptual and Statistical Audition), Vol. 53, No. 5, pp. 658-676, May-June 2011.BibTeX
- @Article{LeRoux2011Specom05,
- author = {Le Roux, Jonathan and Kameoka, Hirokazu and Ono, Nobutaka and de Cheveigne, Alain and Sagayama, Shigeki},
- title = {Computational Auditory Induction as a Missing-Data Model-Fitting Problem with Bregman Divergence},
- journal = {Speech Communication (Special issue on Perceptual and Statistical Audition)},
- year = 2011,
- volume = 53,
- number = 5,
- pages = {658--676},
- month = {May-June}
- }
- , "Statistical Model of Speech Signals Based on Composite Autoregressive System with Application to Blind Source Separation", International Conference on Latent Variable Analysis and Signal Separation (LVA/ICA), September 2010, pp. 245-253.BibTeX
- @Inproceedings{Kameoka2010LVA09,
- author = {Kameoka, Hirokazu and Yoshioka, Takuya and Hamamura, Mariko and Le Roux, Jonathan and Kashino, Kunio},
- title = {Statistical Model of Speech Signals Based on Composite Autoregressive System with Application to Blind Source Separation},
- booktitle = {International Conference on Latent Variable Analysis and Signal Separation (LVA/ICA)},
- year = 2010,
- pages = {245--253},
- month = sep
- }
- , "A Statistical Model of Speech F0 Contours", ISCA Tutorial and Research Workshop on Statistical And Perceptual Audition (SAPA), September 2010, pp. 43-48.BibTeX
- @Inproceedings{Kameoka2010SAPA09,
- author = {Kameoka, Hirokazu and Le Roux, Jonathan and Ohishi, Yasunori},
- title = {A Statistical Model of Speech F0 Contours},
- booktitle = {ISCA Tutorial and Research Workshop on Statistical And Perceptual Audition (SAPA)},
- year = 2010,
- pages = {43--48},
- month = sep
- }
- , "Fast Signal Reconstruction from Magnitude STFT Spectrogram Based on Spectrogram Consistency", International Conference on Digital Audio Effects (DAFx), September 2010, pp. 397-403.BibTeX
- @Inproceedings{LeRoux2010DAFx09,
- author = {Le Roux, Jonathan and Kameoka, Hirokazu and Ono, Nobutaka and Sagayama, Shigeki},
- title = {Fast Signal Reconstruction from Magnitude STFT Spectrogram Based on Spectrogram Consistency},
- booktitle = {International Conference on Digital Audio Effects (DAFx)},
- year = 2010,
- pages = {397--403},
- month = sep
- }
- , "Consistent Wiener Filtering: Generalized Time-Frequency Masking Respecting Spectrogram Consistency", International Conference on Latent Variable Analysis and Signal Separation (LVA/ICA), September 2010, pp. 89-96.BibTeX
- @Inproceedings{LeRoux2010LVA09,
- author = {Le Roux, Jonathan and Vincent, Emmanuel and Mizuno, Yuu and Kameoka, Hirokazu and Ono, Nobutaka and Sagayama, Shigeki},
- title = {Consistent Wiener Filtering: Generalized Time-Frequency Masking Respecting Spectrogram Consistency},
- booktitle = {International Conference on Latent Variable Analysis and Signal Separation (LVA/ICA)},
- year = 2010,
- pages = {89--96},
- month = sep
- }
- , "Nonnegative Matrix Factorization with Markov-chained Bases for Modeling Time-varying patterns in Music Spectrograms", International Conference on Latent Variable Analysis and Signal Separation (LVA/ICA), September 2010, pp. 149-156.BibTeX
- @Inproceedings{Nakano2010LVA09,
- author = {Nakano, Masahiro and Le Roux, Jonathan and Kameoka, Hirokazu and Kitano, Yu and Ono, Nobutaka and Sagayama, Shigeki},
- title = {Nonnegative Matrix Factorization with Markov-chained Bases for Modeling Time-varying patterns in Music Spectrograms},
- booktitle = {International Conference on Latent Variable Analysis and Signal Separation (LVA/ICA)},
- year = 2010,
- pages = {149--156},
- month = sep
- }
- , "Convergence-Guaranteed Multiplicative Algorithms for Non-Negative Matrix Factorization with Beta-Divergence", IEEE International Workshop on Machine Learning for Signal Processing (MLSP), August 2010.BibTeX
- @Inproceedings{Nakano2010MLSP08,
- author = {Nakano, Masahiro and Kameoka, Hirokazu and Le Roux, Jonathan and Kitano, Yu and Ono, Nobutaka and Sagayama, Shigeki},
- title = {Convergence-Guaranteed Multiplicative Algorithms for Non-Negative Matrix Factorization with Beta-Divergence},
- booktitle = {IEEE International Workshop on Machine Learning for Signal Processing (MLSP)},
- year = 2010,
- month = aug
- }
- , "Entropy and Chaos in the Kac Model", Kinetic and Related Models, Vol. 3, No. 1, pp. 85-122, March 2010.BibTeX
- @Article{Carlen2010KRM03,
- author = {Carlen, Eric and Carvalho, Maria C. and Le Roux, Jonathan and Loss, Michael and Villani, Cedric},
- title = {Entropy and Chaos in the Kac Model},
- journal = {Kinetic and Related Models},
- year = 2010,
- volume = 3,
- number = 1,
- pages = {85--122},
- month = mar
- }
- , "Harmonic and Percussive Sound Separation and Its Application to MIR-Related Tasks" in Advances in Music Information Retrieval, Ras, Z. W. and Wieczorkowska, A., Eds., vol. 274 of Studies in Computational Intelligence, pp. 213-236, Springer, 2010.BibTeX
- @Incollection{Ono2010Springer,
- author = {Ono, Nobutaka and Miyamoto, Kenichi and Kameoka, Hirokazu and Le Roux, Jonathan and Uchiyama, Yuuki and Tsunoo, Emiru and Nishimoto, Takuya and Sagayama, Shigeki},
- title = {Harmonic and Percussive Sound Separation and Its Application to MIR-Related Tasks},
- booktitle = {Advances in Music Information Retrieval},
- year = 2010,
- editor = {Ras, Z. W. and Wieczorkowska, A.},
- volume = 274,
- series = {Studies in Computational Intelligence},
- pages = {213--236},
- publisher = {Springer}
- }
- , "Exploiting Regularities in Natural Acoustical Scenes for Monaural Audio Signal Estimation, Decomposition, Restoration and Modification", March 2009, The University of Tokyo & Université Paris VI--Pierre et Marie Curie.BibTeX
- @Phdthesis{LeRoux2009PhD03,
- author = {Le Roux, Jonathan},
- title = {Exploiting Regularities in Natural Acoustical Scenes for Monaural Audio Signal Estimation, Decomposition, Restoration and Modification},
- school = {The University of Tokyo & Universite Paris VI--Pierre et Marie Curie},
- year = 2009,
- month = mar
- }
- , "Adaptive Template Matching with Shift-Invariant Semi-NMF", Advances in Neural Information Processing Systems (Proc. NIPS), Koller, D. and Bengio, Y. and Shuurmans, D. and Bottou, L., Eds., 2009.BibTeX
- @Inproceedings{LeRoux2008NIPS12,
- author = {Le Roux, Jonathan and de Cheveigne, Alain and Parra, Lucas C.},
- title = {Adaptive Template Matching with Shift-Invariant Semi-NMF},
- booktitle = {Advances in Neural Information Processing Systems (Proc. NIPS)},
- year = 2009,
- editor = {Koller, D. and Bengio, Y. and Shuurmans, D. and Bottou, L.},
- address = {Cambridge, MA},
- publisher = {The MIT Press}
- }
- , "Computational Auditory Induction by Missing-Data Non-Negative Matrix Factorization", ISCA Workshop on Statistical and Perceptual Audition (SAPA), September 2008, pp. 1-6.BibTeX
- @Inproceedings{LeRoux2008SAPA09a,
- author = {Le Roux, Jonathan and Kameoka, Hirokazu and Ono, Nobutaka and de Cheveigne, Alain and Sagayama, Shigeki},
- title = {Computational Auditory Induction by Missing-Data Non-Negative Matrix Factorization},
- booktitle = {ISCA Workshop on Statistical and Perceptual Audition (SAPA)},
- year = 2008,
- pages = {1--6},
- month = sep
- }
- , "Explicit Consistency Constraints for STFT Spectrograms and Their Application to Phase Reconstruction", ISCA Workshop on Statistical and Perceptual Audition (SAPA), September 2008, pp. 23-28.BibTeX
- @Inproceedings{LeRoux2008SAPA09b,
- author = {Le Roux, Jonathan and Ono, Nobutaka and Sagayama, Shigeki},
- title = {Explicit Consistency Constraints for STFT Spectrograms and Their Application to Phase Reconstruction},
- booktitle = {ISCA Workshop on Statistical and Perceptual Audition (SAPA)},
- year = 2008,
- pages = {23--28},
- month = sep
- }
- , "Separation of a Monaural Audio Signal into Harmonic/Percussive Components by Complementary Diffusion on Spectrogram", European Signal Processing Conference (EUSIPCO), August 2008.BibTeX
- @Inproceedings{Ono2008EUSIPCO08,
- author = {Ono, Nobutaka and Miyamoto, Ken-Ichi and Le Roux, Jonathan and Kameoka, Hirokazu and Sagayama, Shigeki},
- title = {Separation of a Monaural Audio Signal into Harmonic/Percussive Components by Complementary Diffusion on Spectrogram},
- booktitle = {European Signal Processing Conference (EUSIPCO)},
- year = 2008,
- month = aug
- }
- , "Modulation Analysis of Speech Through Orthogonal FIR Filterbank Optimization", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2008, pp. 4189-4192.BibTeX
- @Inproceedings{LeRoux2008ICASSP04,
- author = {Le Roux, Jonathan and Kameoka, Hirokazu and Ono, Nobutaka and Sagayama, Shigeki and de Cheveigne, Alain},
- title = {Modulation Analysis of Speech Through Orthogonal FIR Filterbank Optimization},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2008,
- pages = {4189--4192},
- month = apr
- }
- , "On the Interpretation of I-Divergence-Based Distribution-Fitting as a Maximum-Likelihood Estimation Problem," Tech. Rep. METR 2008-11, The University of Tokyo, March 2008.BibTeX
- @Techreport{LeRoux2008TechRep03,
- author = {Le Roux, Jonathan and Kameoka, Hirokazu and Ono, Nobutaka and Sagayama, Shigeki},
- title = {On the Interpretation of I-Divergence-Based Distribution-Fitting as a Maximum-Likelihood Estimation Problem},
- institution = {The University of Tokyo},
- year = 2008,
- number = {METR 2008-11},
- month = mar
- }
- , "Single Channel Speech and Background Segregation through Harmonic-Temporal Clustering", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), October 2007, pp. 279-282.BibTeX
- @Inproceedings{LeRoux2007WASPAA10,
- author = {Le Roux, Jonathan and Kameoka, Hirokazu and Ono, Nobutaka and de Cheveigne, Alain and Sagayama, Shigeki},
- title = {Single Channel Speech and Background Segregation through Harmonic-Temporal Clustering},
- booktitle = {IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
- year = 2007,
- pages = {279--282},
- month = oct
- }
- , "Single and Multiple F0 Contour Estimation Through Parametric Spectrogram Modeling of Speech in Noisy Environments", IEEE Transactions on Audio, Speech and Language Processing, Vol. 15, No. 4, pp. 1135-1145, May 2007.BibTeX
- @Article{LeRoux2007IEEETASLP05,
- author = {Le Roux, Jonathan and Kameoka, Hirokazu and Ono, Nobutaka and de Cheveigne, Alain and Sagayama, Shigeki},
- title = {Single and Multiple F0 Contour Estimation Through Parametric Spectrogram Modeling of Speech in Noisy Environments},
- journal = {IEEE Transactions on Audio, Speech and Language Processing},
- year = 2007,
- volume = 15,
- number = 4,
- pages = {1135--1145},
- month = may
- }
- , "Harmonic-Temporal Clustering of Speech for Single and Multiple F0 Contour Estimation in Noisy Environments", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2007, vol. 4, pp. 1053-1056.BibTeX
- @Inproceedings{LeRoux2007ICASSP04,
- author = {Le Roux, Jonathan and Kameoka, Hirokazu and Ono, Nobutaka and de Cheveigne, Alain and Sagayama, Shigeki},
- title = {Harmonic-Temporal Clustering of Speech for Single and Multiple F0 Contour Estimation in Noisy Environments},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2007,
- volume = 4,
- pages = {1053--1056},
- month = apr
- }
- , "MEG Signal Denoising based on Time-Shift PCA", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2007, vol. 1, pp. 317-320.BibTeX
- @Inproceedings{deCheveigne2007ICASSP04,
- author = {de Cheveigne, Alain and Le Roux, Jonathan and Simon, Jonathan Z.},
- title = {MEG Signal Denoising based on Time-Shift PCA},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2007,
- volume = 1,
- pages = {317--320},
- month = apr
- }
- , "Discriminative Training for Large Vocabulary Speech Recognition Using Minimum Classification Error", IEEE Transactions on Audio, Speech and Language Processing, Vol. 15, No. 1, pp. 203-223, January 2007.BibTeX
- @Article{McDermott2007IEEETASLP03,
- author = {McDermott, Erik and Hazen, Timothy J. and Le Roux, Jonathan and Nakamura, Atsushi and Katagiri, Shigeru},
- title = {Discriminative Training for Large Vocabulary Speech Recognition Using Minimum Classification Error},
- journal = {IEEE Transactions on Audio, Speech and Language Processing},
- year = 2007,
- volume = 15,
- number = 1,
- pages = {203--223},
- month = jan
- }
- , "Speech Analyzer Using a Joint Estimation Model of Spectral Envelope and Fine Structure", ISCA International Conference on Spoken Language Processing (ICSLP/Interspeech), September 2006, pp. 2502-2505.BibTeX
- @Inproceedings{Kameoka2006Interspeech09,
- author = {Kameoka, Hirokazu and Le Roux, Jonathan and Ono, Nobutaka and Sagayama, Shigeki},
- title = {Speech Analyzer Using a Joint Estimation Model of Spectral Envelope and Fine Structure},
- booktitle = {ISCA International Conference on Spoken Language Processing (ICSLP/Interspeech)},
- year = 2006,
- pages = {2502--2505},
- month = sep
- }
- , "Optimization Methods for Discriminative Training", ISCA European Conference on Speech Communication and Technology (Eurospeech/Interspeech), September 2005, pp. 3341-3344.BibTeX
- @Inproceedings{LeRoux2005Eurospeech09,
- author = {Le Roux, Jonathan and McDermott, Erik},
- title = {Optimization Methods for Discriminative Training},
- booktitle = {ISCA European Conference on Speech Communication and Technology (Eurospeech/Interspeech)},
- year = 2005,
- pages = {3341--3344},
- month = sep
- }
- , "Bayesian Nonparametric Spectrogram Modeling Based on Infinite Factorial Infinite Hidden Markov Model", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), October 2011.
-
Software & Data Downloads
-
Videos
-
MERL Issued Patents
-
Title: "Method and System for Detecting Anomalous Sound"
Inventors: Wichern, Gordon P; Chakrabarty, Ankush; Wang, Zhongqiu; Le Roux, Jonathan
Patent No.: 11,978,476
Issue Date: May 7, 2024 -
Title: "Long-context End-to-end Speech Recognition System"
Inventors: Hori, Takaaki; Moritz, Niko; Hori, Chiori; Le Roux, Jonathan
Patent No.: 11,978,435
Issue Date: May 7, 2024 -
Title: "Artificial Intelligence System for Sequence-to-Sequence Processing With Attention Adapted for Streaming Applications"
Inventors: Moritz, Niko; Hori, Takaaki; Le Roux, Jonathan
Patent No.: 11,810,552
Issue Date: Nov 7, 2023 -
Title: "Low-latency speech separation using LC-BLSTM and Teacher-Student Learning"
Inventors: AIHARA, RYO; HANAZAWA, TOSHIYUKI; OKATO, YOHEI; Wichern, Gordon P; Le Roux, Jonathan
Patent No.: 11798574
Issue Date: Oct 24, 2023 -
Title: "Method and System for Dereverberation of Speech Signals"
Inventors: Wang, Zhongqiu; Wichern, Gordon P; Le Roux, Jonathan
Patent No.: 11,790,930
Issue Date: Oct 17, 2023 -
Title: "System and Method for Producing Metadata of an Audio Signal"
Inventors: Moritz, Niko; Wichern, Gordon P; Hori, Takaaki; Le Roux, Jonathan
Patent No.: 11,756,551
Issue Date: Sep 12, 2023 -
Title: "Method and System for Scene-Aware Interaction"
Inventors: Hori, Chiori; Cherian, Anoop; Chen, Siheng; Marks, Tim; Le Roux, Jonathan; Hori, Takaaki; Harsham, Bret A.; Vetro, Anthony; Sullivan, Alan
Patent No.: 11,635,299
Issue Date: Apr 25, 2023 -
Title: "Scene-Aware Video Encoder System and Method"
Inventors: Cherian, Anoop; Hori, Chiori; Le Roux, Jonathan; Marks, Tim; Sullivan, Alan
Patent No.: 11,582,485
Issue Date: Feb 14, 2023 -
Title: "Manufacturing Automation using Acoustic Separation Neural Network"
Inventors: Wichern, Gordon P; Le Roux, Jonathan; Pishdadian, Fatemeh
Patent No.: 11,579,598
Issue Date: Feb 14, 2023 -
Title: "An Artificial Intelligence System for Capturing Context by Dilated Self-Attention"
Inventors: Moritz, Niko; Hori, Takaaki; Le Roux, Jonathan
Patent No.: 11,557,283
Issue Date: Jan 17, 2023 -
Title: "System and Method for Hierarchical Audio Source Separation"
Inventors: Wichern, Gordon P; Le Roux, Jonathan; Manilow, Ethan
Patent No.: 11,475,908
Issue Date: Oct 18, 2022 -
Title: "System and Method for Detecting Adversarial Attacks"
Inventors: Le Roux, Jonathan; Jayashankar, Tejas; Moulin, Pierre
Patent No.: 11,462,211
Issue Date: Oct 4, 2022 -
Title: "Low-latency Captioning System"
Inventors: Hori, Chiori; Hori, Takaaki; Cherian, Anoop; Marks, Tim; Le Roux, Jonathan
Patent No.: 11,445,267
Issue Date: Sep 13, 2022 -
Title: "System and Method for Streaming end-to-end Speech Recognition with Asynchronous Decoders pruning prefixes using a joint label and frame information in transcribing technique"
Inventors: Moritz, Niko; Hori, Takaaki; Le Roux, Jonathan
Patent No.: 11,373,639
Issue Date: Jun 28, 2022 -
Title: "Scene-Aware Video Dialog"
Inventors: Geng, Shijie; Gao, Peng; Cherian, Anoop; Hori, Chiori; Le Roux, Jonathan
Patent No.: 11,210,523
Issue Date: Dec 28, 2021 -
Title: "System and Method for End-to-End Speech Recognition with Triggered Attention"
Inventors: Moritz, Niko; Hori, Takaaki; Le Roux, Jonathan
Patent No.: 11,100,920
Issue Date: Aug 24, 2021 -
Title: "Method and System for Multi-Label Classification"
Inventors: Hori, Takaaki; Hori, Chiori; Watanabe, Shinji; Hershey, John R.; Harsham, Bret A.; Le Roux, Jonathan
Patent No.: 11,086,918
Issue Date: Aug 10, 2021 -
Title: "Methods and Systems for Recognizing Simultaneous Speech by Multiple Speakers"
Inventors: Le Roux, Jonathan; Hori, Takaaki; Settle, Shane; Seki, Hiroshi; Watanabe, Shinji; Hershey, John R.
Patent No.: 10,811,000
Issue Date: Oct 20, 2020 -
Title: "Methods and Systems for Enhancing Audio Signals Corrupted by Noise"
Inventors: Le Roux, Jonathan; Watanabe, Shinji; Hershey, John R.; Wichern, Gordon P
Patent No.: 10,726,856
Issue Date: Jul 28, 2020 -
Title: "Method and Apparatus for Multi-Lingual End-to-End Speech Recognition"
Inventors: Watanabe, Shinji; Hori, Takaaki; Seki, Hiroshi; Le Roux, Jonathan; Hershey, John R.
Patent No.: 10,593,321
Issue Date: Mar 17, 2020 -
Title: "Neural Networks for Transforming Signals"
Inventors: Le Roux, Jonathan; Hershey, John R.; Weninger, Felix
Patent No.: 10,592,800
Issue Date: Mar 17, 2020 -
Title: "Methods and Systems for End-to-End Speech Separation with Unfolded Iterative Phase Reconstruction"
Inventors: Le Roux, Jonathan; Hershey, John R.; Wang, Zhongqiu; Wichern, Gordon P
Patent No.: 10,529,349
Issue Date: Jan 7, 2020 -
Title: "Method for Enhancing Audio Signal using Phase Information"
Inventors: Erdogan, Hakan; Hershey, John R.; Watanabe, Shinji; Le Roux, Jonathan
Patent No.: 9,881,631
Issue Date: Jan 30, 2018 -
Title: "Method for Distinguishing Components of Signal of Environment"
Inventors: Hershey, John R.; Le Roux, Jonathan; Watanabe, Shinji; Chen, Zhuo
Patent No.: 9,685,155
Issue Date: Jun 20, 2017 -
Title: "Source Signal Separation by Discriminatively-Trained Non-Negative Matrix Factorization"
Inventors: Le Roux, Jonathan; Hershey, John R.; Weninger, Felix; Watanabe, Shinji
Patent No.: 9,679,559
Issue Date: Jun 13, 2017 -
Title: "Flat-Panel Acoustic Apparatus"
Inventors: Le Roux, Jonathan; Hershey, John R.; Yerazunis, William S.; Boufounos, Petros T.; Daudet, Laurent
Patent No.: 9,661,414
Issue Date: May 23, 2017 -
Title: "Method for Processing Speech Signals Using an Ensemble of Speech Enhancement Procedures"
Inventors: Le Roux, Jonathan; Watanabe, Shinji; Hershey, John R.
Patent No.: 9,601,130
Issue Date: Mar 21, 2017 -
Title: "Neural Networks for Transforming Signals"
Inventors: Hershey, John R.; Le Roux, Jonathan; Weninger, Felix
Patent No.: 9,582,753
Issue Date: Feb 28, 2017 -
Title: "Method and System for Detecting Events in an Acoustic Signal Subject to Cyclo-Stationary Noise"
Inventors: Hershey, John R.; Potluru, Vamsi K.; Le Roux, Jonathan
Patent No.: 9,477,895
Issue Date: Oct 25, 2016 -
Title: "Actions Prediction for Hypothetical Driving Conditions"
Inventors: Harsham, Bret A.; Hershey, John R.; Le Roux, Jonathan; Nikovski, Daniel N.; Esenther, Alan W.
Patent No.: 9,434,389
Issue Date: Sep 6, 2016 -
Title: "Method for Distinguishing Components of an Acoustic Signal"
Inventors: Hershey, John R.; Le Roux, Jonathan; Watanabe, Shinji; Chen, Zhuo
Patent No.: 9,368,110
Issue Date: Jun 14, 2016 -
Title: "Denoising Noisy Speech Signals using Probabilistic Model"
Inventors: Le Roux, Jonathan; Hershey, John R.; Simsekli, Umut
Patent No.: 9,324,338
Issue Date: Apr 26, 2016 -
Title: "Method for Localizing Sources of Signals in Reverberant Environments Using Sparse Optimization"
Inventors: Boufounos, Petros T.; Le Roux, Jonathan; Kang, Kang; Hershey, John R.
Patent No.: 9,251,436
Issue Date: Feb 2, 2016 -
Title: "Method and Apparatus for Processing Text with Variations in Vocabulary Usage"
Inventors: Hershey, John R.; Le Roux, Jonathan; Heakulani, Creighton K.
Patent No.: 9,251,250
Issue Date: Feb 2, 2016 -
Title: "Method and System for Dynamically Adapting user Interfaces in Vehicle Navigation Systems to Minimize Interaction Complexity"
Inventors: Nikovski, Daniel N.; Hershey, John R.; Harsham, Bret A.; Le Roux, Jonathan
Patent No.: 9,170,119
Issue Date: Oct 27, 2015 -
Title: "Method of Text Classification Using Discriminative Topic Transformation"
Inventors: Hershey, John R.; Le Roux, Jonathan
Patent No.: 9,069,798
Issue Date: Jun 30, 2015 -
Title: "Indirect Model-Based Speech Enhancement"
Inventors: Hershey, John R.; Le Roux, Jonathan
Patent No.: 8,880,393
Issue Date: Nov 4, 2014
-
Title: "Method and System for Detecting Anomalous Sound"