Speech & Audio
Audio source separation, recognition, and understanding.
Our current research focuses on application of machine learning to estimation and inference problems in speech and audio processing. Topics include end-to-end speech recognition and enhancement, acoustic modeling and analysis, statistical dialog systems, as well as natural language understanding and adaptive multimodal interfaces.
Quick Links
-
Researchers
-
Awards
-
AWARD MERL team wins the Listener Acoustic Personalisation (LAP) 2024 Challenge Date: August 29, 2024
Awarded to: Yoshiki Masuyama, Gordon Wichern, Francois G. Germain, Christopher Ick, and Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Gordon Wichern; Yoshiki Masuyama
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 7 teams in Task 2 of the 1st SONICOM Listener Acoustic Personalisation (LAP) Challenge, which focused on "Spatial upsampling for obtaining a high-spatial-resolution HRTF from a very low number of directions". The team was led by Yoshiki Masuyama, and also included Gordon Wichern, Francois Germain, MERL intern Christopher Ick, and Jonathan Le Roux.
The LAP Challenge workshop and award ceremony was hosted by the 32nd European Signal Processing Conference (EUSIPCO 24) on August 29, 2024 in Lyon, France. Yoshiki Masuyama presented the team's method, "Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization", and received the award from Prof. Michele Geronazzo (University of Padova, IT, and Imperial College London, UK), Chair of the Challenge's Organizing Committee.
The LAP challenge aims to explore challenges in the field of personalized spatial audio, with the first edition focusing on the spatial upsampling and interpolation of head-related transfer functions (HRTFs). HRTFs with dense spatial grids are required for immersive audio experiences, but their recording is time-consuming. Although HRTF spatial upsampling has recently shown remarkable progress with approaches involving neural fields, HRTF estimation accuracy remains limited when upsampling from only a few measured directions, e.g., 3 or 5 measurements. The MERL team tackled this problem by proposing a retrieval-augmented neural field (RANF). RANF retrieves a subject whose HRTFs are close to those of the target subject at the measured directions from a library of subjects. The HRTF of the retrieved subject at the target direction is fed into the neural field in addition to the desired sound source direction. The team also developed a neural network architecture that can handle an arbitrary number of retrieved subjects, inspired by a multi-channel processing technique called transform-average-concatenate.
- MERL's Speech & Audio team ranked 1st out of 7 teams in Task 2 of the 1st SONICOM Listener Acoustic Personalisation (LAP) Challenge, which focused on "Spatial upsampling for obtaining a high-spatial-resolution HRTF from a very low number of directions". The team was led by Yoshiki Masuyama, and also included Gordon Wichern, Francois Germain, MERL intern Christopher Ick, and Jonathan Le Roux.
-
AWARD Jonathan Le Roux elevated to IEEE Fellow Date: January 1, 2024
Awarded to: Jonathan Le Roux
MERL Contact: Jonathan Le Roux
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL Distinguished Scientist and Speech & Audio Senior Team Leader Jonathan Le Roux has been elevated to IEEE Fellow, effective January 2024, "for contributions to multi-source speech and audio processing."
Mitsubishi Electric celebrated Dr. Le Roux's elevation and that of another researcher from the company, Dr. Shumpei Kameyama, with a worldwide news release on February 15.
Dr. Jonathan Le Roux has made fundamental contributions to the field of multi-speaker speech processing, especially to the areas of speech separation and multi-speaker end-to-end automatic speech recognition (ASR). His contributions constituted a major advance in realizing a practically usable solution to the cocktail party problem, enabling machines to replicate humans’ ability to concentrate on a specific sound source, such as a certain speaker within a complex acoustic scene—a long-standing challenge in the speech signal processing community. Additionally, he has made key contributions to the measures used for training and evaluating audio source separation methods, developing several new objective functions to improve the training of deep neural networks for speech enhancement, and analyzing the impact of metrics used to evaluate the signal reconstruction quality. Dr. Le Roux’s technical contributions have been crucial in promoting the widespread adoption of multi-speaker separation and end-to-end ASR technologies across various applications, including smart speakers, teleconferencing systems, hearables, and mobile devices.
IEEE Fellow is the highest grade of membership of the IEEE. It honors members with an outstanding record of technical achievements, contributing importantly to the advancement or application of engineering, science and technology, and bringing significant value to society. Each year, following a rigorous evaluation procedure, the IEEE Fellow Committee recommends a select group of recipients for elevation to IEEE Fellow. Less than 0.1% of voting members are selected annually for this member grade elevation.
- MERL Distinguished Scientist and Speech & Audio Senior Team Leader Jonathan Le Roux has been elevated to IEEE Fellow, effective January 2024, "for contributions to multi-source speech and audio processing."
-
AWARD MERL team wins the Audio-Visual Speech Enhancement (AVSE) 2023 Challenge Date: December 16, 2023
Awarded to: Zexu Pan, Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux
MERL Contacts: Chiori Hori; Jonathan Le Roux; Gordon Wichern; Yoshiki Masuyama
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
The AVSE challenge aims to design better speech enhancement systems by harnessing the visual aspects of speech (such as lip movements and gestures) in a manner similar to the brain’s multi-modal integration strategies. MERL’s system was a scenario-aware audio-visual TF-GridNet, that incorporates the face recording of a target speaker as a conditioning factor and also recognizes whether the predominant interference signal is speech or background noise. In addition to outperforming all competing systems in terms of objective metrics by a wide margin, in a listening test, MERL’s model achieved the best overall word intelligibility score of 84.54%, compared to 57.56% for the baseline and 80.41% for the next best team. The Fisher’s least significant difference (LSD) was 2.14%, indicating that our model offered statistically significant speech intelligibility improvements compared to all other systems.
- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
See All Awards for Speech & Audio -
-
News & Events
-
NEWS MERL Papers and Workshops at CVPR 2025 Date: June 11, 2025 - June 15, 2025
Where: Nashville, TN, USA
MERL Contacts: Matthew Brand; Moitreya Chatterjee; Anoop Cherian; Michael J. Jones; Toshiaki Koike-Akino; Jing Liu; Suhas Anand Lohit; Tim K. Marks; Pedro Miraldo; Kuan-Chuan Peng; Pu (Perry) Wang; Ye Wang
Research Areas: Artificial Intelligence, Computer Vision, Machine Learning, Signal Processing, Speech & AudioBrief- MERL researchers are presenting 2 conference papers, co-organizing two workshops, and presenting 7 workshop papers at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2025 conference, which will be held in Nashville, TN, USA from June 11-15, 2025. CVPR is one of the most prestigious and competitive international conferences in the area of computer vision. Details of MERL contributions are provided below:
Main Conference Papers:
1. "UWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing" by Y.H. Lai, J. Ebbers, Y. F. Wang, F. Germain, M. J. Jones, M. Chatterjee
This work deals with the task of weakly‑supervised Audio-Visual Video Parsing (AVVP) and proposes a novel, uncertainty-aware algorithm called UWAV towards that end. UWAV works by producing more reliable segment‑level pseudo‑labels while explicitly weighting each label by its prediction uncertainty. This uncertainty‑aware training, combined with a feature‑mixup regularization scheme, promotes inter‑segment consistency in the pseudo-labels. As a result, UWAV achieves state‑of‑the‑art performance on two AVVP datasets across multiple metrics, demonstrating both effectiveness and strong generalizability.
Paper: https://www.merl.com/publications/TR2025-072
2. "TailedCore: Few-Shot Sampling for Unsupervised Long-Tail Noisy Anomaly Detection" by Y. G. Jung, J. Park, J. Yoon, K.-C. Peng, W. Kim, A. B. J. Teoh, and O. Camps.
This work tackles unsupervised anomaly detection in complex scenarios where normal data is noisy and has an unknown, imbalanced class distribution. Existing models face a trade-off between robustness to noise and performance on rare (tail) classes. To address this, the authors propose TailSampler, which estimates class sizes from embedding similarities to isolate tail samples. Using TailSampler, they develop TailedCore, a memory-based model that effectively captures tail class features while remaining noise-robust, outperforming state-of-the-art methods in extensive evaluations.
paper: https://www.merl.com/publications/TR2025-077
MERL Co-Organized Workshops:
1. Multimodal Algorithmic Reasoning (MAR) Workshop, organized by A. Cherian, K.-C. Peng, S. Lohit, H. Zhou, K. Smith, L. Xue, T. K. Marks, and J. Tenenbaum.
Workshop link: https://marworkshop.github.io/cvpr25/
2. The 6th Workshop on Fair, Data-Efficient, and Trusted Computer Vision, organized by N. Ratha, S. Karanam, Z. Wu, M. Vatsa, R. Singh, K.-C. Peng, M. Merler, and K. Varshney.
Workshop link: https://fadetrcv.github.io/2025/
Workshop Papers:
1. "FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations" by N. Sawada, P. Miraldo, S. Lohit, T.K. Marks, and M. Chatterjee (Oral)
With their ability to model object surfaces in a scene as a continuous function, neural implicit surface reconstruction methods have made remarkable strides recently, especially over classical 3D surface reconstruction methods, such as those that use voxels or point clouds. Towards this end, we propose FreBIS - a neural implicit‑surface framework that avoids overloading a single encoder with every surface detail. It divides a scene into several frequency bands and assigns a dedicated encoder (or group of encoders) to each band, then enforces complementary feature learning through a redundancy‑aware weighting module. Swapping this frequency‑stratified stack into an off‑the‑shelf reconstruction pipeline markedly boosts 3D surface accuracy and view‑consistent rendering on the challenging BlendedMVS dataset.
paper: https://www.merl.com/publications/TR2025-074
2. "Multimodal 3D Object Detection on Unseen Domains" by D. Hegde, S. Lohit, K.-C. Peng, M. J. Jones, and V. M. Patel.
LiDAR-based object detection models often suffer performance drops when deployed in unseen environments due to biases in data properties like point density and object size. Unlike domain adaptation methods that rely on access to target data, this work tackles the more realistic setting of domain generalization without test-time samples. We propose CLIX3D, a multimodal framework that uses both LiDAR and image data along with supervised contrastive learning to align same-class features across domains and improve robustness. CLIX3D achieves state-of-the-art performance across various domain shifts in 3D object detection.
paper: https://www.merl.com/publications/TR2025-078
3. "Improving Open-World Object Localization by Discovering Background" by A. Singh, M. J. Jones, K.-C. Peng, M. Chatterjee, A. Cherian, and E. Learned-Miller.
This work tackles open-world object localization, aiming to detect both seen and unseen object classes using limited labeled training data. While prior methods focus on object characterization, this approach introduces background information to improve objectness learning. The proposed framework identifies low-information, non-discriminative image regions as background and trains the model to avoid generating object proposals there. Experiments on standard benchmarks show that this method significantly outperforms previous state-of-the-art approaches.
paper: https://www.merl.com/publications/TR2025-058
4. "PF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector" by K. Li, T. Zhang, K.-C. Peng, and G. Wang.
This work addresses challenges in 3D object detection for autonomous driving by improving the fusion of LiDAR and camera data, which is often hindered by domain gaps and limited labeled data. Leveraging advances in foundation models and prompt engineering, the authors propose PF3Det, a multi-modal detector that uses foundation model encoders and soft prompts to enhance feature fusion. PF3Det achieves strong performance even with limited training data. It sets new state-of-the-art results on the nuScenes dataset, improving NDS by 1.19% and mAP by 2.42%.
paper: https://www.merl.com/publications/TR2025-076
5. "Noise Consistency Regularization for Improved Subject-Driven Image Synthesis" by Y. Ni., S. Wen, P. Konius, A. Cherian
Fine-tuning Stable Diffusion enables subject-driven image synthesis by adapting the model to generate images containing specific subjects. However, existing fine-tuning methods suffer from two key issues: underfitting, where the model fails to reliably capture subject identity, and overfitting, where it memorizes the subject image and reduces background diversity. To address these challenges, two auxiliary consistency losses are porposed for diffusion fine-tuning. First, a prior consistency regularization loss ensures that the predicted diffusion noise for prior (non- subject) images remains consistent with that of the pretrained model, improving fidelity. Second, a subject consistency regularization loss enhances the fine-tuned model’s robustness to multiplicative noise modulated latent code, helping to preserve subject identity while improving diversity. Our experimental results demonstrate the effectiveness of our approach in terms of image diversity, outperforming DreamBooth in terms of CLIP scores, background variation, and overall visual quality.
paper: https://www.merl.com/publications/TR2025-073
6. "LatentLLM: Attention-Aware Joint Tensor Compression" by T. Koike-Akino, X. Chen, J. Liu, Y. Wang, P. Wang, M. Brand
We propose a new framework to convert a large foundation model such as large language models (LLMs)/large multi- modal models (LMMs) into a reduced-dimension latent structure. Our method uses a global attention-aware joint tensor decomposition to significantly improve the model efficiency. We show the benefit on several benchmark including multi-modal reasoning tasks.
paper: https://www.merl.com/publications/TR2025-075
7. "TuneComp: Joint Fine-Tuning and Compression for Large Foundation Models" by T. Koike-Akino, X. Chen, J. Liu, Y. Wang, P. Wang, M. Brand
To reduce model size during post-training, compression methods, including knowledge distillation, low-rank approximation, and pruning, are often applied after fine- tuning the model. However, sequential fine-tuning and compression sacrifices performance, while creating a larger than necessary model as an intermediate step. In this work, we aim to reduce this gap, by directly constructing a smaller model while guided by the downstream task. We propose to jointly fine-tune and compress the model by gradually distilling it to a pruned low-rank structure. Experiments demonstrate that joint fine-tuning and compression significantly outperforms other sequential compression methods.
paper: https://www.merl.com/publications/TR2025-079
- MERL researchers are presenting 2 conference papers, co-organizing two workshops, and presenting 7 workshop papers at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2025 conference, which will be held in Nashville, TN, USA from June 11-15, 2025. CVPR is one of the most prestigious and competitive international conferences in the area of computer vision. Details of MERL contributions are provided below:
-
EVENT MERL Contributes to ICASSP 2025 Date: Sunday, April 6, 2025 - Friday, April 11, 2025
Location: Hyderabad, India
MERL Contacts: Wael H. Ali; Petros T. Boufounos; Radu Corcodel; Chiori Hori; Siddarth Jain; Devesh K. Jha; Toshiaki Koike-Akino; Jonathan Le Roux; Yanting Ma; Hassan Mansour; Yoshiki Masuyama; Joshua Rapp; Diego Romeres; Anthony Vetro; Pu (Perry) Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Communications, Computational Sensing, Electronic and Photonic Devices, Machine Learning, Robotics, Signal Processing, Speech & AudioBrief- MERL has made numerous contributions to both the organization and technical program of ICASSP 2025, which is being held in Hyderabad, India from April 6-11, 2025.
Sponsorship
MERL is proud to be a Silver Patron of the conference and will participate in the student job fair on Thursday, April 10. Please join this session to learn more about employment opportunities at MERL, including openings for research scientists, post-docs, and interns.
MERL is pleased to be the sponsor of two IEEE Awards that will be presented at the conference. We congratulate Prof. Björn Erik Ottersten, the recipient of the 2025 IEEE Fourier Award for Signal Processing, and Prof. Shrikanth Narayanan, the recipient of the 2025 IEEE James L. Flanagan Speech and Audio Processing Award. Both awards will be presented in-person at ICASSP by Anthony Vetro, MERL President & CEO.
Technical Program
MERL is presenting 15 papers in the main conference on a wide range of topics including source separation, sound event detection, sound anomaly detection, speaker diarization, music generation, robot action generation from video, indoor airflow imaging, WiFi sensing, Doppler single-photon Lidar, optical coherence tomography, and radar imaging. Another paper on spatial audio will be presented at the Generative Data Augmentation for Real-World Signal Processing Applications (GenDA) Satellite Workshop.
MERL Researchers Petros Boufounos and Hassan Mansour will present a Tutorial on “Computational Methods in Radar Imaging” in the afternoon of Monday, April 7.
Petros Boufounos will also be giving an industry talk on Thursday April 10 at 12pm, on “A Physics-Informed Approach to Sensing".
About ICASSP
ICASSP is the flagship conference of the IEEE Signal Processing Society, and the world's largest and most comprehensive technical conference focused on the research advances and latest technological development in signal and information processing. The event has been attracting more than 4000 participants each year.
- MERL has made numerous contributions to both the organization and technical program of ICASSP 2025, which is being held in Hyderabad, India from April 6-11, 2025.
See All News & Events for Speech & Audio -
-
Research Highlights
-
Internships
-
SA0186: Internship - Neural Spatial Audio Processing and Understanding
-
SA0188: Internship - Audio separation, generation, and analysis
-
SA0191: Internship - Human-Robot Interaction Based on Multimodal Scene Understanding
See All Internships for Speech & Audio -
-
Openings
See All Openings at MERL -
Recent Publications
- , "Handling Domain Shifts for Anomalous Sound Detection: A Review of DCASE-Related Work", Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE), October 2025.BibTeX TR2025-157 PDF
- @inproceedings{Wilkinghoff2025oct,
- author = {Wilkinghoff, Kevin and Fujimura, Takuya and Imoto, Keisuke and {Le Roux}, Jonathan and Tan, Zheng-Hua and Toda, Tomoki},
- title = {{Handling Domain Shifts for Anomalous Sound Detection: A Review of DCASE-Related Work}},
- booktitle = {Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE)},
- year = 2025,
- month = oct,
- url = {https://www.merl.com/publications/TR2025-157}
- }
- , "Physics-Informed Direction-Aware Neural Acoustic Fields", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), October 2025.BibTeX TR2025-142 PDF
- @inproceedings{Masuyama2025oct,
- author = {Masuyama, Yoshiki and Germain, François G and Wichern, Gordon and Ick, Christopher and {Le Roux}, Jonathan},
- title = {{Physics-Informed Direction-Aware Neural Acoustic Fields}},
- booktitle = {IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
- year = 2025,
- month = oct,
- url = {https://www.merl.com/publications/TR2025-142}
- }
- , "FasTUSS: Faster Task-Aware Unified Source Separation", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), October 2025.BibTeX TR2025-143 PDF
- @inproceedings{Paissan2025oct,
- author = {Paissan, Francesco and Wichern, Gordon and Masuyama, Yoshiki and Aihara, Ryo and Germain, François G and Saijo, Kohei and {Le Roux}, Jonathan},
- title = {{FasTUSS: Faster Task-Aware Unified Source Separation}},
- booktitle = {IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
- year = 2025,
- month = oct,
- url = {https://www.merl.com/publications/TR2025-143}
- }
- , "HASRD: Hierarchical Acoustic and Semantic Representation Disentanglement", Interspeech, DOI: 10.21437/Interspeech.2025-2063, August 2025, pp. 5393-5397.BibTeX TR2025-122 PDF
- @inproceedings{Hussein2025aug,
- author = {Hussein, Amir and Khurana, Sameer and Wichern, Gordon and Germain, François G and {Le Roux}, Jonathan},
- title = {{HASRD: Hierarchical Acoustic and Semantic Representation Disentanglement}},
- booktitle = {Interspeech},
- year = 2025,
- pages = {5393--5397},
- month = aug,
- publisher = {ISCA},
- doi = {10.21437/Interspeech.2025-2063},
- url = {https://www.merl.com/publications/TR2025-122}
- }
- , "Direction-Aware Neural Acoustic Fields for Few-Shot Interpolation of Ambisonic Impulse Responses", Interspeech, DOI: 10.21437/Interspeech.2025-1912, August 2025, pp. 933-937.BibTeX TR2025-120 PDF
- @inproceedings{Ick2025aug,
- author = {Ick, Christopher and Wichern, Gordon and Masuyama, Yoshiki and Germain, François G and {Le Roux}, Jonathan},
- title = {{Direction-Aware Neural Acoustic Fields for Few-Shot Interpolation of Ambisonic Impulse Responses}},
- booktitle = {Interspeech},
- year = 2025,
- pages = {933--937},
- month = aug,
- doi = {10.21437/Interspeech.2025-1912},
- url = {https://www.merl.com/publications/TR2025-120}
- }
- , "Factorized RVQ-GAN For Disentangled Speech Tokenization", Interspeech, DOI: 10.21437/Interspeech.2025-2612, August 2025, pp. 3514-3518.BibTeX TR2025-123 PDF
- @inproceedings{Khurana2025aug,
- author = {Khurana, Sameer and Klement, Dominik and Laurent, Antoine and Bobos, Dominik and Novosad, Juraj and Gazdik, Peter and Zhang, Ellen and Huang, Zilli and Hussein, Amir and Marxer, Ricard and Masuyama, Yoshiki and Aihara, Ryo and Hori, Chiori and Germain, François G and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{Factorized RVQ-GAN For Disentangled Speech Tokenization}},
- booktitle = {Interspeech},
- year = 2025,
- pages = {3514--3518},
- month = aug,
- publisher = {ISCA},
- doi = {10.21437/Interspeech.2025-2612},
- url = {https://www.merl.com/publications/TR2025-123}
- }
- , "Investigating Continuous Autoregressive Generative Speech Enhancement", Interspeech, DOI: doi: 10.21437/Interspeech.2025-2335, August 2025, pp. 2360-2364.BibTeX TR2025-119 PDF
- @inproceedings{Yang2025aug,
- author = {Yang, Haici and Wichern, Gordon and Aihara, Ryo and Masuyama, Yoshiki and Khurana, Sameer and Germain, François G and {Le Roux}, Jonathan},
- title = {{Investigating Continuous Autoregressive Generative Speech Enhancement}},
- booktitle = {Interspeech},
- year = 2025,
- pages = {2360--2364},
- month = aug,
- publisher = {ISCA},
- doi = {doi: 10.21437/Interspeech.2025-2335},
- url = {https://www.merl.com/publications/TR2025-119}
- }
- , "Audio Signal Processing in the Artificial Intelligence Era: Challenges and Directions", Journal of the Audio Engineering Society, August 2025.BibTeX TR2025-116 PDF
- @article{Steinmetz2025aug,
- author = {Steinmetz, Christian and Uhle, Christian and Everardo, Flavio and Mitcheltree, Christopher and McElveen, J. Keith and Jot, Jean-Marc and Wichern, Gordon},
- title = {{Audio Signal Processing in the Artificial Intelligence Era: Challenges and Directions}},
- journal = {Journal of the Audio Engineering Society},
- year = 2025,
- month = aug,
- url = {https://www.merl.com/publications/TR2025-116}
- }
- , "Handling Domain Shifts for Anomalous Sound Detection: A Review of DCASE-Related Work", Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE), October 2025.
-
Videos
-
Software & Data Downloads
-
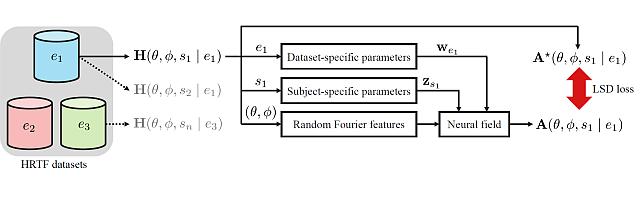
Subject- and Dataset-Aware Neural Field for HRTF Modeling -
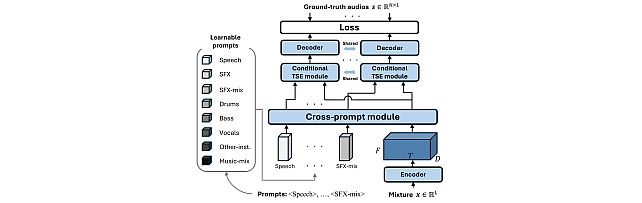
Task-Aware Unified Source Separation -
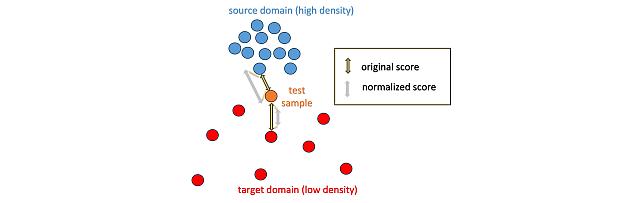
Local Density-Based Anomaly Score Normalization for Domain Generalization -
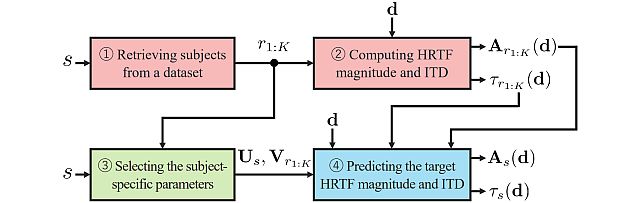
Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization -
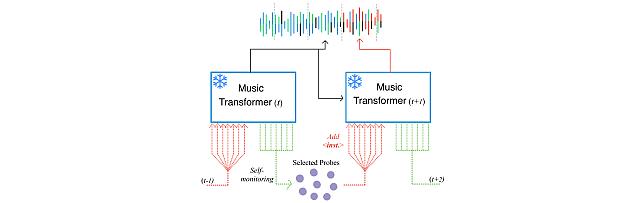
Self-Monitored Inference-Time INtervention for Generative Music Transformers -
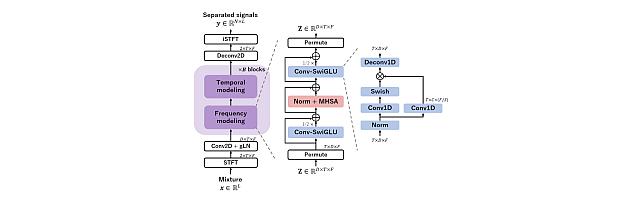
Transformer-based model with LOcal-modeling by COnvolution -
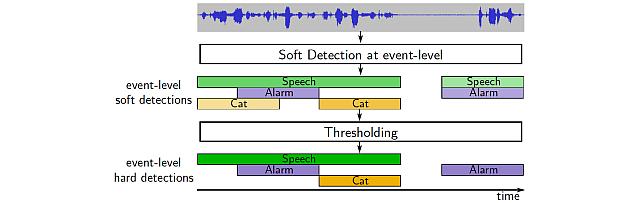
Sound Event Bounding Boxes -
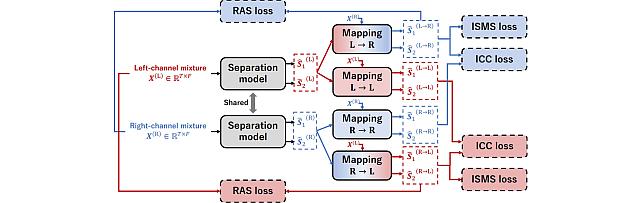
Enhanced Reverberation as Supervision -
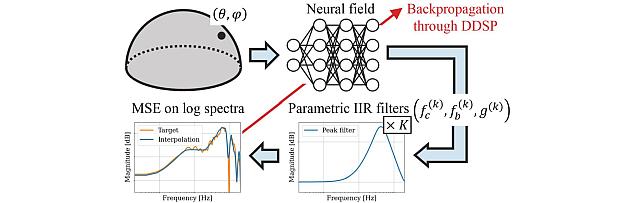
Neural IIR Filter Field for HRTF Upsampling and Personalization -
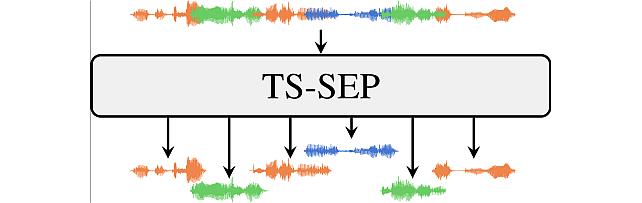
Target-Speaker SEParation -
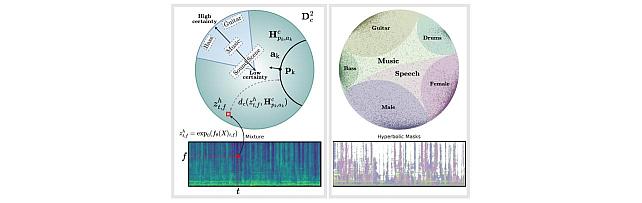
Hyperbolic Audio Source Separation -
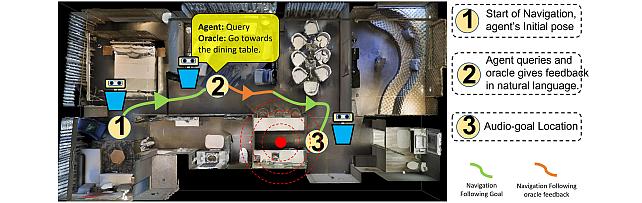
Audio-Visual-Language Embodied Navigation in 3D Environments -
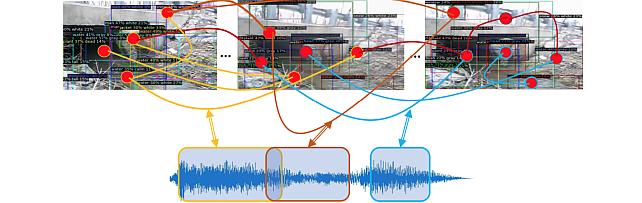
Audio Visual Scene-Graph Segmentor -
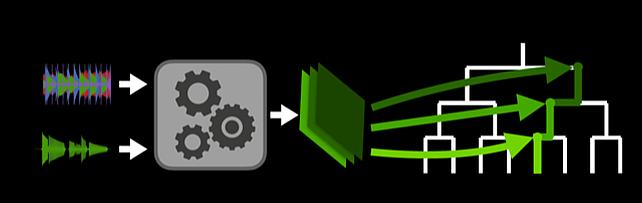
Hierarchical Musical Instrument Separation -
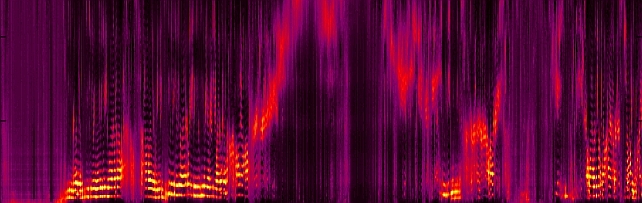
Non-negative Dynamical System model
-

















