Gordon Wichern

- Phone: 617-621-7574
- Email:
-
Position:
Research / Technical Staff
Senior Principal Research Scientist -
Education:
Ph.D., Arizona State University, 2010 -
Research Areas:
External Links:
Gordon's Quick Links
-
Biography
Gordon's research interests are at the intersection of signal processing and machine learning applied to speech, music, and environmental sounds. Prior to joining MERL, Gordon worked at iZotope inc. developing audio signal processing software, and at MIT Lincoln Laboratory where he worked in radar target tracking.
-
Recent News & Events
-
EVENT MERL Contributes to ICASSP 2024 Date: Sunday, April 14, 2024 - Friday, April 19, 2024
Location: Seoul, South Korea
MERL Contacts: Petros T. Boufounos; François Germain; Chiori Hori; Sameer Khurana; Toshiaki Koike-Akino; Jonathan Le Roux; Hassan Mansour; Zexu Pan; Kieran Parsons; Joshua Rapp; Anthony Vetro; Pu (Perry) Wang; Gordon Wichern; Ryoma Yataka
Research Areas: Artificial Intelligence, Computational Sensing, Machine Learning, Robotics, Signal Processing, Speech & AudioBrief- MERL has made numerous contributions to both the organization and technical program of ICASSP 2024, which is being held in Seoul, Korea from April 14-19, 2024.
Sponsorship and Awards
MERL is proud to be a Bronze Patron of the conference and will participate in the student job fair on Thursday, April 18. Please join this session to learn more about employment opportunities at MERL, including openings for research scientists, post-docs, and interns.
MERL is pleased to be the sponsor of two IEEE Awards that will be presented at the conference. We congratulate Prof. Stéphane G. Mallat, the recipient of the 2024 IEEE Fourier Award for Signal Processing, and Prof. Keiichi Tokuda, the recipient of the 2024 IEEE James L. Flanagan Speech and Audio Processing Award.
Jonathan Le Roux, MERL Speech and Audio Senior Team Leader, will also be recognized during the Awards Ceremony for his recent elevation to IEEE Fellow.
Technical Program
MERL will present 13 papers in the main conference on a wide range of topics including automated audio captioning, speech separation, audio generative models, speech and sound synthesis, spatial audio reproduction, multimodal indoor monitoring, radar imaging, depth estimation, physics-informed machine learning, and integrated sensing and communications (ISAC). Three workshop papers have also been accepted for presentation on audio-visual speaker diarization, music source separation, and music generative models.
Perry Wang is the co-organizer of the Workshop on Signal Processing and Machine Learning Advances in Automotive Radars (SPLAR), held on Sunday, April 14. It features keynote talks from leaders in both academia and industry, peer-reviewed workshop papers, and lightning talks from ICASSP regular tracks on signal processing and machine learning for automotive radar and, more generally, radar perception.
Gordon Wichern will present an invited keynote talk on analyzing and interpreting audio deep learning models at the Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA), held on Monday, April 15. He will also appear in a panel discussion on interpretable audio AI at the workshop.
Perry Wang also co-organizes a two-part special session on Next-Generation Wi-Fi Sensing (SS-L9 and SS-L13) which will be held on Thursday afternoon, April 18. The special session includes papers on PHY-layer oriented signal processing and data-driven deep learning advances, and supports upcoming 802.11bf WLAN Sensing Standardization activities.
Petros Boufounos is participating as a mentor in ICASSP’s Micro-Mentoring Experience Program (MiME).
About ICASSP
ICASSP is the flagship conference of the IEEE Signal Processing Society, and the world's largest and most comprehensive technical conference focused on the research advances and latest technological development in signal and information processing. The event attracts more than 3000 participants.
- MERL has made numerous contributions to both the organization and technical program of ICASSP 2024, which is being held in Seoul, Korea from April 14-19, 2024.
-
NEWS MERL co-organizes the 2023 Sound Demixing (SDX2023) Challenge and Workshop Date: January 23, 2023 - November 4, 2023
Where: International Symposium of Music Information Retrieval (ISMR)
MERL Contacts: Jonathan Le Roux; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL Speech & Audio team members Gordon Wichern and Jonathan Le Roux co-organized the 2023 Sound Demixing Challenge along with researchers from Sony, Moises AI, Audioshake, and Meta.
The SDX2023 Challenge was hosted on the AI Crowd platform and had a prize pool of $42,000 distributed to the winning teams across two tracks: Music Demixing and Cinematic Sound Demixing. A unique aspect of this challenge was the ability to test the audio source separation models developed by challenge participants on non-public songs from Sony Music Entertainment Japan for the music demixing track, and movie soundtracks from Sony Pictures for the cinematic sound demixing track. The challenge ran from January 23rd to May 1st, 2023, and had 884 participants distributed across 68 teams submitting 2828 source separation models. The winners will be announced at the SDX2023 Workshop, which will take place as a satellite event at the International Symposium of Music Information Retrieval (ISMR) in Milan, Italy on November 4, 2023.
MERL’s contribution to SDX2023 focused mainly on the cinematic demixing track. In addition to sponsoring the prizes awarded to the winning teams for that track, the baseline system and initial training data were MERL’s Cocktail Fork separation model and Divide and Remaster dataset, respectively. MERL researchers also contributed to a Town Hall kicking off the challenge, co-authored a scientific paper describing the challenge outcomes, and co-organized the SDX2023 Workshop.
- MERL Speech & Audio team members Gordon Wichern and Jonathan Le Roux co-organized the 2023 Sound Demixing Challenge along with researchers from Sony, Moises AI, Audioshake, and Meta.
See All News & Events for Gordon -
-
Awards
-
AWARD MERL team wins the Audio-Visual Speech Enhancement (AVSE) 2023 Challenge Date: December 16, 2023
Awarded to: Zexu Pan, Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux
MERL Contacts: François Germain; Chiori Hori; Sameer Khurana; Jonathan Le Roux; Zexu Pan; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
The AVSE challenge aims to design better speech enhancement systems by harnessing the visual aspects of speech (such as lip movements and gestures) in a manner similar to the brain’s multi-modal integration strategies. MERL’s system was a scenario-aware audio-visual TF-GridNet, that incorporates the face recording of a target speaker as a conditioning factor and also recognizes whether the predominant interference signal is speech or background noise. In addition to outperforming all competing systems in terms of objective metrics by a wide margin, in a listening test, MERL’s model achieved the best overall word intelligibility score of 84.54%, compared to 57.56% for the baseline and 80.41% for the next best team. The Fisher’s least significant difference (LSD) was 2.14%, indicating that our model offered statistically significant speech intelligibility improvements compared to all other systems.
- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
-
AWARD MERL Intern and Researchers Win ICASSP 2023 Best Student Paper Award Date: June 9, 2023
Awarded to: Darius Petermann, Gordon Wichern, Aswin Subramanian, Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Gordon Wichern
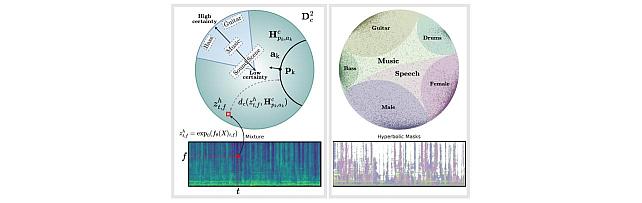
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- Former MERL intern Darius Petermann (Ph.D. Candidate at Indiana University) has received a Best Student Paper Award at the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023) for the paper "Hyperbolic Audio Source Separation", co-authored with MERL researchers Gordon Wichern and Jonathan Le Roux, and former MERL researcher Aswin Subramanian. The paper presents work performed during Darius's internship at MERL in the summer 2022. The paper introduces a framework for audio source separation using embeddings on a hyperbolic manifold that compactly represent the hierarchical relationship between sound sources and time-frequency features. Additionally, the code associated with the paper is publicly available at https://github.com/merlresearch/hyper-unmix.
ICASSP is the flagship conference of the IEEE Signal Processing Society (SPS). ICASSP 2023 was held in the Greek island of Rhodes from June 04 to June 10, 2023, and it was the largest ICASSP in history, with more than 4000 participants, over 6128 submitted papers and 2709 accepted papers. Darius’s paper was first recognized as one of the Top 3% of all papers accepted at the conference, before receiving one of only 5 Best Student Paper Awards during the closing ceremony.
- Former MERL intern Darius Petermann (Ph.D. Candidate at Indiana University) has received a Best Student Paper Award at the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023) for the paper "Hyperbolic Audio Source Separation", co-authored with MERL researchers Gordon Wichern and Jonathan Le Roux, and former MERL researcher Aswin Subramanian. The paper presents work performed during Darius's internship at MERL in the summer 2022. The paper introduces a framework for audio source separation using embeddings on a hyperbolic manifold that compactly represent the hierarchical relationship between sound sources and time-frequency features. Additionally, the code associated with the paper is publicly available at https://github.com/merlresearch/hyper-unmix.
-
AWARD Joint CMU-MERL team wins DCASE2023 Challenge on Automated Audio Captioning Date: June 1, 2023
Awarded to: Shih-Lun Wu, Xuankai Chang, Gordon Wichern, Jee-weon Jung, Francois Germain, Jonathan Le Roux, Shinji Watanabe
MERL Contacts: François Germain; Jonathan Le Roux; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- A joint team consisting of members of CMU Professor and MERL Alumn Shinji Watanabe's WavLab and members of MERL's Speech & Audio team ranked 1st out of 11 teams in the DCASE2023 Challenge's Task 6A "Automated Audio Captioning". The team was led by student Shih-Lun Wu and also featured Ph.D. candidate Xuankai Chang, Postdoctoral research associate Jee-weon Jung, Prof. Shinji Watanabe, and MERL researchers Gordon Wichern, Francois Germain, and Jonathan Le Roux.
The IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), started in 2013, has been organized yearly since 2016, and gathers challenges on multiple tasks related to the detection, analysis, and generation of sound events. This year, the DCASE2023 Challenge received over 428 submissions from 123 teams across seven tasks.
The CMU-MERL team competed in the Task 6A track, Automated Audio Captioning, which aims at generating informative descriptions for various sounds from nature and/or human activities. The team's system made strong use of large pretrained models, namely a BEATs transformer as part of the audio encoder stack, an Instructor Transformer encoding ground-truth captions to derive an audio-text contrastive loss on the audio encoder, and ChatGPT to produce caption mix-ups (i.e., grammatical and compact combinations of two captions) which, together with the corresponding audio mixtures, increase not only the amount but also the complexity and diversity of the training data. The team's best submission obtained a SPIDEr-FL score of 0.327 on the hidden test set, largely outperforming the 2nd best team's 0.315.
- A joint team consisting of members of CMU Professor and MERL Alumn Shinji Watanabe's WavLab and members of MERL's Speech & Audio team ranked 1st out of 11 teams in the DCASE2023 Challenge's Task 6A "Automated Audio Captioning". The team was led by student Shih-Lun Wu and also featured Ph.D. candidate Xuankai Chang, Postdoctoral research associate Jee-weon Jung, Prof. Shinji Watanabe, and MERL researchers Gordon Wichern, Francois Germain, and Jonathan Le Roux.
-
AWARD Best Poster Award and Best Video Award at the International Society for Music Information Retrieval Conference (ISMIR) 2020 Date: October 15, 2020
Awarded to: Ethan Manilow, Gordon Wichern, Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- Former MERL intern Ethan Manilow and MERL researchers Gordon Wichern and Jonathan Le Roux won Best Poster Award and Best Video Award at the 2020 International Society for Music Information Retrieval Conference (ISMIR 2020) for the paper "Hierarchical Musical Source Separation". The conference was held October 11-14 in a virtual format. The Best Poster Awards and Best Video Awards were awarded by popular vote among the conference attendees.
The paper proposes a new method for isolating individual sounds in an audio mixture that accounts for the hierarchical relationship between sound sources. Many sounds we are interested in analyzing are hierarchical in nature, e.g., during a music performance, a hi-hat note is one of many such hi-hat notes, which is one of several parts of a drumkit, itself one of many instruments in a band, which might be playing in a bar with other sounds occurring. Inspired by this, the paper re-frames the audio source separation problem as hierarchical, combining similar sounds together at certain levels while separating them at other levels, and shows on a musical instrument separation task that a hierarchical approach outperforms non-hierarchical models while also requiring less training data. The paper, poster, and video can be seen on the paper page on the ISMIR website.
- Former MERL intern Ethan Manilow and MERL researchers Gordon Wichern and Jonathan Le Roux won Best Poster Award and Best Video Award at the 2020 International Society for Music Information Retrieval Conference (ISMIR 2020) for the paper "Hierarchical Musical Source Separation". The conference was held October 11-14 in a virtual format. The Best Poster Awards and Best Video Awards were awarded by popular vote among the conference attendees.
-
-
Research Highlights
-
MERL Publications
- , "Late Audio-Visual Fusion for In-The-Wild Speaker Diarization", Hands-free Speech Communication and Microphone Arrays (HSCMA), April 2024.BibTeX TR2024-029 PDF
- @inproceedings{Pan2024apr,
- author = {Pan, Zexu and Wichern, Gordon and Germain, François G and Subramanian, Aswin and Le Roux, Jonathan},
- title = {Late Audio-Visual Fusion for In-The-Wild Speaker Diarization},
- booktitle = {Hands-free Speech Communication and Microphone Arrays (HSCMA)},
- year = 2024,
- month = apr,
- url = {https://www.merl.com/publications/TR2024-029}
- }
- , "SMITIN: Self-Monitored Inference-Time INtervention for Generative Music Transformers", arXiv, April 2024.BibTeX arXiv
- @article{Koo2024apr2,
- author = {Koo, Junghyun and Wichern, Gordon and Germain, François G and Khurana, Sameer and Le Roux, Jonathan},
- title = {SMITIN: Self-Monitored Inference-Time INtervention for Generative Music Transformers},
- journal = {arXiv},
- year = 2024,
- month = apr,
- url = {https://arxiv.org/abs/2404.02252}
- }
- , "Understanding and Controlling Generative Music Transformers by Probing Individual Attention Heads", IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA), April 2024.BibTeX TR2024-032 PDF
- @inproceedings{Koo2024apr,
- author = {Koo, Junghyun and Wichern, Gordon and Germain, François G and Khurana, Sameer and Le Roux, Jonathan},
- title = {Understanding and Controlling Generative Music Transformers by Probing Individual Attention Heads},
- booktitle = {IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA)},
- year = 2024,
- month = apr,
- url = {https://www.merl.com/publications/TR2024-032}
- }
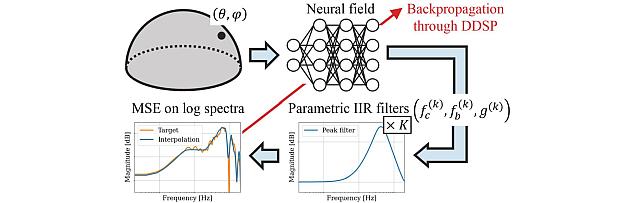
- , "Improving Audio Captioning Models with Fine-grained Audio Features, Text Embedding Supervision, and LLM Mix-up Augmentation", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2024.BibTeX TR2024-028 PDF
- @inproceedings{Wu2024mar,
- author = {Wu, Shih-Lun and Chang, Xuankai and Wichern, Gordon and Jung, Jee-weon and Germain, François G and Le Roux, Jonathan and Watanabe, Shinji},
- title = {Improving Audio Captioning Models with Fine-grained Audio Features, Text Embedding Supervision, and LLM Mix-up Augmentation},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-028}
- }
- , "Generation or Replication: Auscultating Audio Latent Diffusion Models", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2024.BibTeX TR2024-027 PDF
- @inproceedings{Bralios2024mar,
- author = {Bralios, Dimitrios and Wichern, Gordon and Germain, François G and Pan, Zexu and Khurana, Sameer and Hori, Chiori and Le Roux, Jonathan},
- title = {Generation or Replication: Auscultating Audio Latent Diffusion Models},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-027}
- }
- , "Late Audio-Visual Fusion for In-The-Wild Speaker Diarization", Hands-free Speech Communication and Microphone Arrays (HSCMA), April 2024.
-
Other Publications
- , "Low-Latency approximation of bidirectional recurrent networks for speech denoising", 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), Oct 2017, pp. 66-70.BibTeX
- @Inproceedings{8169996,
- author = {Wichern, G. and Lukin, A.},
- title = {Low-Latency approximation of bidirectional recurrent networks for speech denoising},
- booktitle = {2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
- year = 2017,
- pages = {66--70},
- month = {Oct}
- }
- , "Quantitative Analysis of Masking in Multitrack Mixes Using Loudness Loss", Sep 2016, Audio Engineering Society Convention 141.BibTeX External
- @Conference{wichern2016quantitative,
- author = {Wichern, G. and Robertson, H. and Wishnick, A.},
- title = {Quantitative Analysis of Masking in Multitrack Mixes Using Loudness Loss},
- booktitle = {Audio Engineering Society Convention 141},
- year = 2016,
- month = {Sep},
- url = {http://www.aes.org/e-lib/browse.cfm?elib=18450}
- }
- , "Comparison of Loudness Features for Automatic Level Adjustment in Mixing", Oct 2015, Audio Engineering Society Convention 139.BibTeX External
- @Conference{wichern2015comparison,
- author = {Wichern, G. and Wishnick, A. and Lukin, A. and Robertson, H.},
- title = {Comparison of Loudness Features for Automatic Level Adjustment in Mixing},
- booktitle = {Audio Engineering Society Convention 139},
- year = 2015,
- month = {Oct},
- url = {http://www.aes.org/e-lib/browse.cfm?elib=17928}
- }
- , "Noise adaptive optimization of matrix initialization for frequency-domain independent component analysis", Digital Signal Processing, Vol. 23, No. 1, pp. 1-8, 2013.BibTeX
- @Article{yamada2013noise,
- author = {Yamada, M. and Wichern, G. and Kondo, K. and Sugiyama, M. and Sawada, H.},
- title = {Noise adaptive optimization of matrix initialization for frequency-domain independent component analysis},
- journal = {Digital Signal Processing},
- year = 2013,
- volume = 23,
- number = 1,
- pages = {1--8},
- publisher = {Academic Press}
- }
- , "Improving the accuracy of least-squares probabilistic classifiers", IEICE transactions on information and systems, Vol. 94, No. 6, pp. 1337-1340, 2011.BibTeX
- @Article{yamada2011improving,
- author = {Yamada, M. and Sugiyama, M. and Wichern, G. and Simm, J.},
- title = {Improving the accuracy of least-squares probabilistic classifiers},
- journal = {IEICE transactions on information and systems},
- year = 2011,
- volume = 94,
- number = 6,
- pages = {1337--1340},
- publisher = {The Institute of Electronics, Information and Communication Engineers}
- }
- , "Audio content-based feature extraction algorithms using J-DSP for arts, media and engineering courses", 2010 IEEE Frontiers in Education Conference (FIE), Oct 2010, pp. T1F-1-T1F-6.BibTeX
- @Inproceedings{5673157,
- author = {Shah, M. and Wichern, G. and Spanias, A. and Thornburg, H.},
- title = {Audio content-based feature extraction algorithms using J-DSP for arts, media and engineering courses},
- booktitle = {2010 IEEE Frontiers in Education Conference (FIE)},
- year = 2010,
- pages = {T1F--1--T1F--6},
- month = {Oct}
- }
- , "Segmentation, Indexing, and Retrieval for Environmental and Natural Sounds", IEEE Transactions on Audio, Speech, and Language Processing, Vol. 18, No. 3, pp. 688-707, March 2010.BibTeX
- @Article{5410056,
- author = {Wichern, G. and Xue, J. and Thornburg, H. and Mechtley, B. and Spanias, A.},
- title = {Segmentation, Indexing, and Retrieval for Environmental and Natural Sounds},
- journal = {IEEE Transactions on Audio, Speech, and Language Processing},
- year = 2010,
- volume = 18,
- number = 3,
- pages = {688--707},
- month = mar
- }
- , "Direct importance estimation with probabilistic principal component analyzers", 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, March 2010, pp. 1962-1965.BibTeX
- @Inproceedings{5495290,
- author = {Yamada, M. and Sugiyama, M. and Wichern, G.},
- title = {Direct importance estimation with probabilistic principal component analyzers},
- booktitle = {2010 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2010,
- pages = {1962--1965},
- month = mar
- }
- , "Acceleration of sequence kernel computation for real-time speaker identification", 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, March 2010, pp. 1626-1629.BibTeX
- @Inproceedings{5495542,
- author = {Yamada, M. and Sugiyama, M. and Wichern, G. and Matsui, T.},
- title = {Acceleration of sequence kernel computation for real-time speaker identification},
- booktitle = {2010 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2010,
- pages = {1626--1629},
- month = mar
- }
- , "Automatic audio tagging using covariate shift adaptation", 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, March 2010, pp. 253-256.BibTeX
- @Inproceedings{5495973,
- author = {Wichern, G. and Yamada, M. and Thornburg, H. and Sugiyama, M. and Spanias, A.},
- title = {Automatic audio tagging using covariate shift adaptation},
- booktitle = {2010 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2010,
- pages = {253--256},
- month = mar
- }
- , "Combining semantic, social, and acoustic similarity for retrieval of environmental sounds", 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, March 2010, pp. 2402-2405.BibTeX
- @Inproceedings{5496225,
- author = {Mechtley, B. and Wichern, G. and Thornburg, H. and Spanias, A.},
- title = {Combining semantic, social, and acoustic similarity for retrieval of environmental sounds},
- booktitle = {2010 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2010,
- pages = {2402--2405},
- month = mar
- }
- , "Re-Sonification of Geographic Sound Activity using Acoustic, Semantic and Social Information", Proceedings of the 16th International Conference on Auditory Display (ICAD2010), 2010.BibTeX
- @Inproceedings{fink2010re,
- author = {Fink, A. and Mechtley, B. and Wichern, G. and Liu, J. and Thornburg, H. and Spanias, A. and Coleman, G.},
- title = {Re-Sonification of Geographic Sound Activity using Acoustic, Semantic and Social Information},
- booktitle = {Proceedings of the 16th International Conference on Auditory Display (ICAD2010)},
- year = 2010,
- organization = {Georgia Institute of Technology}
- }
- , "An ontological framework for retrieving environmental sounds using semantics and acoustic content", EURASIP Journal on Audio, Speech, and Music Processing, Vol. 2010, No. 1, pp. 192363, 2010.BibTeX
- @Article{wichern2010ontological,
- author = {Wichern, G. and Mechtley, B. and Fink, A. and Thornburg, H. and Spanias, A.},
- title = {An ontological framework for retrieving environmental sounds using semantics and acoustic content},
- journal = {EURASIP Journal on Audio, Speech, and Music Processing},
- year = 2010,
- volume = 2010,
- number = 1,
- pages = 192363,
- publisher = {Springer International Publishing}
- }
- , "Direct importance estimation with a mixture of probabilistic principal component analyzers", IEICE Transactions on Information and Systems, Vol. 93, No. 10, pp. 2846-2849, 2010.BibTeX
- @Article{yamada2010direct,
- author = {Yamada, M. and Sugiyama, M. and Wichern, G. and Simm, J.},
- title = {Direct importance estimation with a mixture of probabilistic principal component analyzers},
- journal = {IEICE Transactions on Information and Systems},
- year = 2010,
- volume = 93,
- number = 10,
- pages = {2846--2849},
- publisher = {The Institute of Electronics, Information and Communication Engineers}
- }
- , "Unifying semantic and content-based approaches for retrieval of environmental sounds", 2009 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, Oct 2009, pp. 13-16.BibTeX
- @Inproceedings{5346493,
- author = {Wichern, G. and Thornburg, H. and Spanias, A.},
- title = {Unifying semantic and content-based approaches for retrieval of environmental sounds},
- booktitle = {2009 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics},
- year = 2009,
- pages = {13--16},
- month = {Oct}
- }
- , "Continuous observation and archival of acoustic scenes using wireless sensor networks", 2009 16th International Conference on Digital Signal Processing, July 2009, pp. 1-6.BibTeX
- @Inproceedings{5201082,
- author = {Wichern, G. and Kwon, H. and Spanias, A. and Fink, A. and Thornburg, H.},
- title = {Continuous observation and archival of acoustic scenes using wireless sensor networks},
- booktitle = {2009 16th International Conference on Digital Signal Processing},
- year = 2009,
- pages = {1--6},
- month = jul
- }
- , "Multi-channel audio segmentation for continuous observation and archival of large spaces", 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, April 2009, pp. 237-240.BibTeX
- @Inproceedings{4959564,
- author = {Wichern, G. and Thornburg, H. and Spanias, A.},
- title = {Multi-channel audio segmentation for continuous observation and archival of large spaces},
- booktitle = {2009 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2009,
- pages = {237--240},
- month = apr
- }
- , "Fast query by example of environmental sounds via robust and efficient cluster-based indexing", 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, March 2008, pp. 5-8.BibTeX
- @Inproceedings{4517532,
- author = {Xue, J. and Wichern, G. and Thornburg, H. and Spanias, A.},
- title = {Fast query by example of environmental sounds via robust and efficient cluster-based indexing},
- booktitle = {2008 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2008,
- pages = {5--8},
- month = mar
- }
- , "Distortion-Aware Query-by-Example for Environmental Sounds", 2007 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, Oct 2007, pp. 335-338.BibTeX
- @Inproceedings{4393051,
- author = {Wichern, G. and Xue, J. and Thornburg, H. and Spanias, A.},
- title = {Distortion-Aware Query-by-Example for Environmental Sounds},
- booktitle = {2007 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics},
- year = 2007,
- pages = {335--338},
- month = {Oct}
- }
- , "An Operationally Adaptive System for Rapid Acoustic Transmission Loss Prediction", 2007 International Joint Conference on Neural Networks, Aug 2007, pp. 2262-2267.BibTeX
- @Inproceedings{4371310,
- author = {McCarron, M. and Azimi-Sadjadi, M. R. and Wichem, G. and Mungiole, M.},
- title = {An Operationally Adaptive System for Rapid Acoustic Transmission Loss Prediction},
- booktitle = {2007 International Joint Conference on Neural Networks},
- year = 2007,
- pages = {2262--2267},
- month = {Aug}
- }
- , "Robust Multi-Features Segmentation and Indexing for Natural Sound Environments", 2007 International Workshop on Content-Based Multimedia Indexing, June 2007, pp. 69-76.BibTeX
- @Inproceedings{4275057,
- author = {Wichern, G. and Thornburg, H. and Mechtley, B. and Fink, A. and Tu, K. and Spanias, A.},
- title = {Robust Multi-Features Segmentation and Indexing for Natural Sound Environments},
- booktitle = {2007 International Workshop on Content-Based Multimedia Indexing},
- year = 2007,
- pages = {69--76},
- month = jun
- }
- , "Environmentally adaptive acoustic transmission loss prediction in turbulent and nonturbulent atmospheres", Neural Networks, Vol. 20, No. 4, pp. 484 - 497, 2007.BibTeX External
- @Article{WICHERN2007484,
- author = {Wichern, G. and Azimi-Sadjadi, M. R. and Mungiole, M.},
- title = {Environmentally adaptive acoustic transmission loss prediction in turbulent and nonturbulent atmospheres},
- journal = {Neural Networks},
- year = 2007,
- volume = 20,
- number = 4,
- pages = {484 -- 497},
- note = {Computational Intelligence in Earth and Environmental Sciences},
- url = {http://www.sciencedirect.com/science/article/pii/S089360800700055X}
- }
- , "An Environmentally Adaptive System for Rapid Acoustic Transmission Loss Prediction", The 2006 IEEE International Joint Conference on Neural Network Proceedings, 2006, pp. 5118-5125.BibTeX
- @Inproceedings{1716812,
- author = {Wichern, G. and Azimi-Sadjadi, M. R. and Mungiole, M.},
- title = {An Environmentally Adaptive System for Rapid Acoustic Transmission Loss Prediction},
- booktitle = {The 2006 IEEE International Joint Conference on Neural Network Proceedings},
- year = 2006,
- pages = {5118--5125}
- }
- , "Properties of randomly distributed sparse arrays", Proc. SPIE, 2006, vol. 6201.BibTeX
- @Inproceedings{azimi2006properties,
- author = {Azimi-Sadjadi, MR and Jiang, Y and Wichern, G},
- title = {Properties of randomly distributed sparse arrays},
- booktitle = {Proc. SPIE},
- year = 2006,
- volume = 6201
- }
- , "Unattended sparse acoustic array configurations and beamforming algorithms", Proc. SPIE, 2005, vol. 5796, pp. 40-51.BibTeX
- @Inproceedings{azimi2005unattended,
- author = {Azimi-Sadjadi, MR and Pezeshki, A and Scharf, LL and Wichern, G},
- title = {Unattended sparse acoustic array configurations and beamforming algorithms},
- booktitle = {Proc. SPIE},
- year = 2005,
- volume = 5796,
- pages = {40--51}
- }
- , "Low-Latency approximation of bidirectional recurrent networks for speech denoising", 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), Oct 2017, pp. 66-70.
-
Software & Data Downloads
-
Videos
-
MERL Issued Patents
-
Title: "Method and System for Detecting Anomalous Sound"
Inventors: Wichern, Gordon P; Chakrabarty, Ankush; Wang, Zhongqiu; Le Roux, Jonathan
Patent No.: 11,978,476
Issue Date: May 7, 2024 -
Title: "Low-latency speech separation using LC-BLSTM and Teacher-Student Learning"
Inventors: AIHARA, RYO; HANAZAWA, TOSHIYUKI; OKATO, YOHEI; Wichern, Gordon P; Le Roux, Jonathan
Patent No.: 11798574
Issue Date: Oct 24, 2023 -
Title: "Method and System for Dereverberation of Speech Signals"
Inventors: Wang, Zhongqiu; Wichern, Gordon P; Le Roux, Jonathan
Patent No.: 11,790,930
Issue Date: Oct 17, 2023 -
Title: "System and Method for Producing Metadata of an Audio Signal"
Inventors: Moritz, Niko; Wichern, Gordon P; Hori, Takaaki; Le Roux, Jonathan
Patent No.: 11,756,551
Issue Date: Sep 12, 2023 -
Title: "Manufacturing Automation using Acoustic Separation Neural Network"
Inventors: Wichern, Gordon P; Le Roux, Jonathan; Pishdadian, Fatemeh
Patent No.: 11,579,598
Issue Date: Feb 14, 2023 -
Title: "System and Method for Hierarchical Audio Source Separation"
Inventors: Wichern, Gordon P; Le Roux, Jonathan; Manilow, Ethan
Patent No.: 11,475,908
Issue Date: Oct 18, 2022 -
Title: "Methods and Systems for Enhancing Audio Signals Corrupted by Noise"
Inventors: Le Roux, Jonathan; Watanabe, Shinji; Hershey, John R.; Wichern, Gordon P
Patent No.: 10,726,856
Issue Date: Jul 28, 2020 -
Title: "Methods and Systems for End-to-End Speech Separation with Unfolded Iterative Phase Reconstruction"
Inventors: Le Roux, Jonathan; Hershey, John R.; Wang, Zhongqiu; Wichern, Gordon P
Patent No.: 10,529,349
Issue Date: Jan 7, 2020
-
Title: "Method and System for Detecting Anomalous Sound"