Chiori Hori

- Phone: 617-621-7568
- Email:
-
Position:
Research / Technical Staff
Senior Principal Research Scientist -
Education:
Ph.D., Tokyo Institute of Technology, 2002 -
Research Areas:
- Artificial Intelligence
- Speech & Audio
- Computer Vision
- Machine Learning
- Robotics
- Human-Computer Interaction
- Signal Processing
External Links:
Chiori's Quick Links
-
Biography
Chiori has been a member of MERL's research team since 2015. Her work is focused on spoken dialog and audio visual scene-aware dialog technologies toward human-robot communications. She's on the editorial board of "Computer Speech and Language" and is a technical committee member of "Speech and Language Processing Group" of IEEE Signal Processing Society. Prior to joining MERL, Chiori spent 8 years at Japan's National Institute of Information and Communication Technology (NICT), where she held the position of Research Manager of the Spoken Language Communication Laboratory. She also spent time researching at Carnegie Mellon and the NTT Communication Science Laboratories, prior to NICT.
-
Recent News & Events
-
EVENT MERL Contributes to ICASSP 2026 Date: Monday, May 4, 2026 - , May 8, 2026
Location: Barcelona, Spain
MERL Contacts: Wael H. Ali; Petros T. Boufounos; Chiori Hori; Jonathan Le Roux; Yanting Ma; Hassan Mansour; Yoshiki Masuyama; Joshua Rapp; Anthony Vetro; Pu (Perry) Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Computational Sensing, Computer Vision, Machine Learning, Optimization, Signal Processing, Speech & AudioBrief- MERL has made numerous contributions to both the organization and technical program of ICASSP 2026, which is being held in Barcelona, Spain from May 4-8, 2026.
Sponsorship
MERL is proud to be a Silver Patron of the conference and will participate in the student job fair on Thursday, May 7. Please join this session to learn more about employment opportunities at MERL, including openings for research scientists, post-docs, and interns. MERL Distinguished Research Scientists Petros T. Boufounos and Jonathan Le Roux will also present a spotlight session on MERL’s research in signal processing on Tuesday, May 5 at 13:05. Finally, MERL will sponsor a photo booth on Thursday, May 7 and Friday, May 8, where ICASSP participants can take professional photos with friends and colleagues, which will be emailed to them.
MERL is also pleased to be the sponsor of two IEEE Awards that will be presented at the conference. We congratulate Prof. Nasir Ahmed, the recipient of the 2026 IEEE Fourier Award for Signal Processing, and Dr. Alex Acero, the recipient of the 2026 IEEE James L. Flanagan Speech and Audio Processing Award.
Technical Program
MERL is presenting 8 papers in the main conference on a wide range of topics including source separation, spatial audio, neural audio codecs, radar-based pose estimation, camera-based airflow sensing, radar array processing, and optimization. Another paper on neural speech codecs will be presented at the Low-Resource Audio Codec (LRAC) Satellite Workshop. MERL researchers will also present two articles published in IEEE Open Journal of Signal Processing (OJSP) on music source separation and head-related transfer function (HRTF) modeling. Finally, Speech and Audio Team members Yoshiki Masuyama and Jonathan Le Roux co-organized a Special Session on Neural Spatial Audio Processing, which will feature six oral presentations.
About ICASSP
ICASSP is the flagship conference of the IEEE Signal Processing Society, and the world's largest and most comprehensive technical conference focused on the research advances and latest technological development in signal and information processing. The event attracts more than 4000 participants each year.
- MERL has made numerous contributions to both the organization and technical program of ICASSP 2026, which is being held in Barcelona, Spain from May 4-8, 2026.
-
NEWS MERL Researchers at NeurIPS 2025 presented 2 conference papers, 5 workshop papers, and organized a workshop. Date: December 2, 2025 - December 7, 2025
Where: San Diego
MERL Contacts: Petros T. Boufounos; Anoop Cherian; Radu Corcodel; Stefano Di Cairano; Chiori Hori; Christopher R. Laughman; Suhas Lohit; Pedro Miraldo; Saviz Mowlavi; Kuan-Chuan Peng; Arvind Raghunathan; Abraham P. Vinod; Pu (Perry) Wang
Research Areas: Artificial Intelligence, Computational Sensing, Computer Vision, Control, Data Analytics, Dynamical Systems, Machine Learning, Multi-Physical Modeling, Optimization, Robotics, Signal Processing, Speech & AudioBrief- MERL researchers presented 2 main-conference papers and 5 workshop papers, as well as organized a workshop, at NeurIPS 2025.
Main Conference Papers:
1) Sorachi Kato, Ryoma Yataka, Pu Wang, Pedro Miraldo, Takuya Fujihashi, and Petros Boufounos, "RAPTR: Radar-based 3D Pose Estimation using Transformer", Code available at: https://github.com/merlresearch/radar-pose-transformer
2) Runyu Zhang, Arvind Raghunathan, Jeff Shamma, and Na Li, "Constrained Optimization From a Control Perspective via Feedback Linearization"
Workshop Papers:
1) Yuyou Zhang, Radu Corcodel, Chiori Hori, Anoop Cherian, and Ding Zhao, "SpinBench: Perspective and Rotation as a Lens on Spatial Reasoning in VLMs", NeuriIPS 2025 Workshop on SPACE in Vision, Language, and Embodied AI (SpaVLE) (Best Paper Runner-up)
2) Xiaoyu Xie, Saviz Mowlavi, and Mouhacine Benosman, "Smooth and Sparse Latent Dynamics in Operator Learning with Jerk Regularization", Workshop on Machine Learning and the Physical Sciences (ML4PS)
3) Spencer Hutchinson, Abraham Vinod, François Germain, Stefano Di Cairano, Christopher Laughman, and Ankush Chakrabarty, "Quantile-SMPC for Grid-Interactive Buildings with Multivariate Temporal Fusion Transformers", Workshop on UrbanAI: Harnessing Artificial Intelligence for Smart Cities (UrbanAI)
4) Yuki Shirai, Kei Ota, Devesh Jha, and Diego Romeres, "Sim-to-Real Contact-Rich Pivoting via Optimization-Guided RL with Vision and Touch", Worskhop on Embodied World Models for Decision Making
5) Mark Van der Merwe and Devesh Jha, "In-Context Policy Iteration for Dynamic Manipulation", Workshop on Embodied World Models for Decision Making
Workshop Organized:
MERL members co-organized the Multimodal Algorithmic Reasoning (MAR) Workshop (https://marworkshop.github.io/neurips25/). Organizers: Anoop Cherian (Mitsubishi Electric Research Laboratories), Kuan-Chuan Peng (Mitsubishi Electric Research Laboratories), Suhas Lohit (Mitsubishi Electric Research Laboratories), Honglu Zhou (Salesforce AI Research), Kevin Smith (Massachusetts Institute of Technology), and Joshua B. Tenenbaum (Massachusetts Institute of Technology).
- MERL researchers presented 2 main-conference papers and 5 workshop papers, as well as organized a workshop, at NeurIPS 2025.
See All News & Events for Chiori -
-
Awards
-
AWARD Honorable Mention Award at NeurIPS 23 Instruction Workshop Date: December 15, 2023
Awarded to: Lingfeng Sun, Devesh K. Jha, Chiori Hori, Siddharth Jain, Radu Corcodel, Xinghao Zhu, Masayoshi Tomizuka and Diego Romeres
MERL Contacts: Radu Corcodel; Chiori Hori; Siddarth Jain
Research Areas: Artificial Intelligence, Machine Learning, RoboticsBrief- MERL Researchers received an "Honorable Mention award" at the Workshop on Instruction Tuning and Instruction Following at the NeurIPS 2023 conference in New Orleans. The workshop was on the topic of instruction tuning and Instruction following for Large Language Models (LLMs). MERL researchers presented their work on interactive planning using LLMs for partially observable robotic tasks during the oral presentation session at the workshop.
-
AWARD MERL team wins the Audio-Visual Speech Enhancement (AVSE) 2023 Challenge Date: December 16, 2023
Awarded to: Zexu Pan, Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux
MERL Contacts: Chiori Hori; Jonathan Le Roux; Gordon Wichern; Yoshiki Masuyama
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
The AVSE challenge aims to design better speech enhancement systems by harnessing the visual aspects of speech (such as lip movements and gestures) in a manner similar to the brain’s multi-modal integration strategies. MERL’s system was a scenario-aware audio-visual TF-GridNet, that incorporates the face recording of a target speaker as a conditioning factor and also recognizes whether the predominant interference signal is speech or background noise. In addition to outperforming all competing systems in terms of objective metrics by a wide margin, in a listening test, MERL’s model achieved the best overall word intelligibility score of 84.54%, compared to 57.56% for the baseline and 80.41% for the next best team. The Fisher’s least significant difference (LSD) was 2.14%, indicating that our model offered statistically significant speech intelligibility improvements compared to all other systems.
- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
-
-
Research Highlights
-
Internships with Chiori
See All Internships at MERL -
MERL Publications
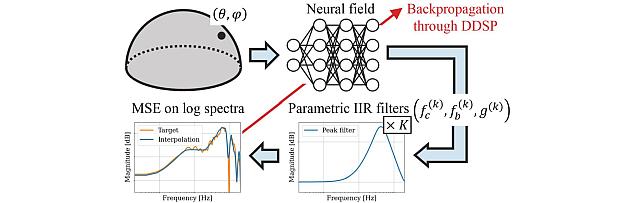
- , "Velocity Potential Neural Field for Efficient Ambisonics Impulse Response Modeling", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), May 2026.BibTeX TR2026-033 PDF
- @inproceedings{Masuyama2026may,
- author = {Masuyama, Yoshiki and Germain, François G and Wichern, Gordon and Hori, Chiori and {Le Roux}, Jonathan},
- title = {{Velocity Potential Neural Field for Efficient Ambisonics Impulse Response Modeling}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2026,
- month = may,
- url = {https://www.merl.com/publications/TR2026-033}
- }
- , "Embedding Morphology into Transformers for Cross-Robot Policy Learning", International Conference on Learning Representations (ICLR) Workshop, April 2026.BibTeX TR2026-048 PDF
- @inproceedings{Suzuki2026apr,
- author = {Suzuki, Kei and Liu, Jing and Wang, Ye and Hori, Chiori and Brand, Matthew and Romeres, Diego and Koike-Akino, Toshiaki},
- title = {{Embedding Morphology into Transformers for Cross-Robot Policy Learning}},
- booktitle = {International Conference on Learning Representations (ICLR) Workshop},
- year = 2026,
- month = apr,
- url = {https://www.merl.com/publications/TR2026-048}
- }
- , "SpinBench: 3D Rotation as a Lens on Spatial Reasoning in VLMs", International Conference on Learning Representations (ICLR) 2026, April 2026.BibTeX TR2026-045 PDF
- @inproceedings{Zhang2026apr2,
- author = {Zhang, Yuyou and Corcodel, Radu and Hori, Chiori and Cherian, Anoop and Zhao, Ding},
- title = {{SpinBench: 3D Rotation as a Lens on Spatial Reasoning in VLMs}},
- booktitle = {International Conference on Learning Representations (ICLR) 2026},
- year = 2026,
- month = apr,
- url = {https://www.merl.com/publications/TR2026-045}
- }
- , "AxisBench: What Can Go Wrong in VLMs’ Spatial Reasoning?", Advances in Neural Information Processing Systems (NeurIPS) workshop, December 2025.BibTeX TR2025-168 PDF
- @inproceedings{Zhang2025dec2,
- author = {{{Zhang, Yuyou and Corcodel, Radu and Hori, Chiori and Cherian, Anoop and Zhao, Ding}}},
- title = {{{AxisBench: What Can Go Wrong in VLMs’ Spatial Reasoning?}}},
- booktitle = {Advances in Neural Information Processing Systems (NeurIPS) workshop},
- year = 2025,
- month = dec,
- url = {https://www.merl.com/publications/TR2025-168}
- }
- , "Robot Confirmation Generation and Action Planning Using Long-context Q-Former Integrated with Multimodal LLM", IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), DOI: 10.1109/ASRU65441.2025.11434641, December 2025.BibTeX TR2025-167 PDF
- @inproceedings{Hori2025dec,
- author = {Hori, Chiori and Masuyama, Yoshiki and Jain, Siddarth and Corcodel, Radu and Jha, Devesh K. and Romeres, Diego and {Le Roux}, Jonathan},
- title = {{Robot Confirmation Generation and Action Planning Using Long-context Q-Former Integrated with Multimodal LLM}},
- booktitle = {IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU)},
- year = 2025,
- month = dec,
- doi = {10.1109/ASRU65441.2025.11434641},
- issn = {2997-6995},
- isbn = {979-8-3315-4426-3},
- url = {https://www.merl.com/publications/TR2025-167}
- }
- , "Velocity Potential Neural Field for Efficient Ambisonics Impulse Response Modeling", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), May 2026.
-
Software & Data Downloads
-
Videos
-
MERL Issued Patents
-
Title: "Method and System for Generating a Sequence of Actions for Controlling a Robot"
Inventors: Hori, Chiori; Le Roux, Jonathan; Jha, Devesh; Jain, Siddarth; Corcodel, Radu Ioan; Romeres, Diego; Peng, Puyuang; Liu, Xinyu; Harwath, David
Patent No.: 12,613,523
Issue Date: Apr 28, 2026 -
Title: "System and Method for Robotic Planning in Partially Observable Environments Using Large Language Models"
Inventors: Jha, Devesh; Sun, Lingfeng; Hori, Chiori; Romeres, Diego
Patent No.: 12,515,331
Issue Date: Jan 6, 2026 -
Title: "Long-context End-to-end Speech Recognition System"
Inventors: Hori, Takaaki; Moritz, Niko; Hori, Chiori; Le Roux, Jonathan
Patent No.: 11,978,435
Issue Date: May 7, 2024 -
Title: "System and Method for Using Human Relationship Structures for Email Classification"
Inventors: Harsham, Bret A.; Hori, Chiori
Patent No.: 11,651,222
Issue Date: May 16, 2023 -
Title: "Method and System for Scene-Aware Interaction"
Inventors: Hori, Chiori; Cherian, Anoop; Chen, Siheng; Marks, Tim; Le Roux, Jonathan; Hori, Takaaki; Harsham, Bret A.; Vetro, Anthony; Sullivan, Alan
Patent No.: 11,635,299
Issue Date: Apr 25, 2023 -
Title: "Scene-Aware Video Encoder System and Method"
Inventors: Cherian, Anoop; Hori, Chiori; Le Roux, Jonathan; Marks, Tim; Sullivan, Alan
Patent No.: 11,582,485
Issue Date: Feb 14, 2023 -
Title: "Low-latency Captioning System"
Inventors: Hori, Chiori; Hori, Takaaki; Cherian, Anoop; Marks, Tim; Le Roux, Jonathan
Patent No.: 11,445,267
Issue Date: Sep 13, 2022 -
Title: "System and Method for a Dialogue Response Generation System"
Inventors: Hori, Chiori; Cherian, Anoop; Marks, Tim; Hori, Takaaki
Patent No.: 11,264,009
Issue Date: Mar 1, 2022 -
Title: "Scene-Aware Video Dialog"
Inventors: Geng, Shijie; Gao, Peng; Cherian, Anoop; Hori, Chiori; Le Roux, Jonathan
Patent No.: 11,210,523
Issue Date: Dec 28, 2021 -
Title: "Method and System for Multi-Label Classification"
Inventors: Hori, Takaaki; Hori, Chiori; Watanabe, Shinji; Hershey, John R.; Harsham, Bret A.; Le Roux, Jonathan
Patent No.: 11,086,918
Issue Date: Aug 10, 2021 -
Title: "Position Estimation Under Multipath Transmission"
Inventors: Kim, Kyeong-Jin; Orlik, Philip V.; Hori, Chiori
Patent No.: 11,079,495
Issue Date: Aug 3, 2021 -
Title: "Method and System for Multi-Modal Fusion Model"
Inventors: Hori, Chiori; Hori, Takaaki; Hershey, John R.; Marks, Tim
Patent No.: 10,417,498
Issue Date: Sep 17, 2019 -
Title: "Method and System for Training Language Models to Reduce Recognition Errors"
Inventors: Hori, Takaaki; Hori, Chiori; Watanabe, Shinji; Hershey, John R.
Patent No.: 10,176,799
Issue Date: Jan 8, 2019 -
Title: "Method and System for Role Dependent Context Sensitive Spoken and Textual Language Understanding with Neural Networks"
Inventors: Hori, Chiori; Hori, Takaaki; Watanabe, Shinji; Hershey, John R.
Patent No.: 9,842,106
Issue Date: Dec 12, 2017
-
Title: "Method and System for Generating a Sequence of Actions for Controlling a Robot"