SLAM-MER: Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling
SLAM-MER is a new C++ pipeline that combines a temporal buffer of recent keyframes with a 3D cell-based spatial scene model.

MERL Researchers: Pedro Miraldo, Lalit Manam.
Joint work with:
Masashi Yamazaki (Mitsubishi Electric Corporation, Tokyo),
Valter Piedade (Instituto Superior Tecnico, Lisbon),
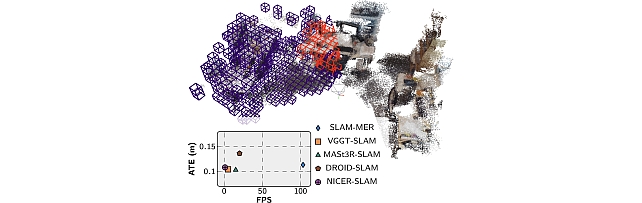
Visual SLAM is one of the central problems in computer vision, with direct applications to AR/VR, robotics, and 3D scene reconstruction. Real-time monocular SLAM remains especially challenging in the uncalibrated setting, where existing systems are often either computationally heavy or insufficiently modular. We introduce SLAM-MER, a new C++ pipeline that combines a temporal buffer of recent keyframes with a 3D cell-based spatial scene model. By pairing sparse 3D-2D localization with feed-forward geometry priors, SLAM-MER achieves real-time operation above 80 FPS while maintaining competitive or improved localization accuracy.
Applications
SLAM-MER is designed for real-time localization and mapping in applications such as augmented reality, robotics, autonomous navigation, and indoor scene reconstruction. Its sparse localization front end and semi-dense reconstruction layer let the system run efficiently while still producing an informative map of the environment. Above, we show representative reconstructions from several challenging indoor sequences.
We also propose a transformer-based model, AssemblyDyno, which uses the instructional manual and the 3D shape of each part to jointly predict assembly order and part assembly trajectories. AssemblyDyno outperforms prior works in both assembly pose estimation and trajectory feasibility, where the latter is evaluated by our physics-based simulations.

Method
SLAM-MER represents the scene with keyframes, sparse 3D map-points, and a 3D cell grid. For each incoming frame, it extracts 2D keypoints and queries candidate 3D points from two sources: a temporal buffer of recently localized frames and a spatial lookup over visible 3D cells. These 3D-2D correspondences are then used to estimate the camera pose, even when the camera intrinsics are unknown.
When a frame is promoted to a keyframe, the system runs feed-forward depth inference only for that keyframe to create local 3D points, rather than invoking dense inference on every frame. This gives the pipeline a hybrid design: sparse keypoint-based localization for speed, combined with anchor-point-driven semi-dense geometry for improved map quality and flexibility.
The back end maintains a covisibility graph and continuously refines keyframe poses and map-points with an incremental ISAM2 optimization. Keyframe creation depends not only on the number of pose-estimation inliers, but also on how well tracked points cover the image and how their distribution changes across keyframes, helping the system recognize revisits and strengthen the map at the right moments.
Loop closure and relocalization are handled through image retrieval plus geometric validation, and the entire framework is modular enough to swap in different keypoint detectors, depth estimators, or place-recognition modules. Experiments on TUM RGB-D and 7-Scenes show that SLAM-MER delivers real-time performance above 80 FPS while matching or improving localization accuracy relative to prior uncalibrated monocular SLAM pipelines.
Software & Data Downloads
MERL Publications
- , "Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), May 2026.BibTeX TR2026-056 PDF Video Software Presentation
- @inproceedings{Piedade2026may,
- author = {{Piedade, Valter and Manam, Lalit and Yamazaki, Masashi and Miraldo, Pedro}},
- title = {{Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = may,
- url = {https://www.merl.com/publications/TR2026-056}
- }