NEWS MERL work on scene-aware interaction featured in IEEE Spectrum
Date released: March 4, 2022
-
NEWS MERL work on scene-aware interaction featured in IEEE Spectrum Date:
March 1, 2022
-
Description:
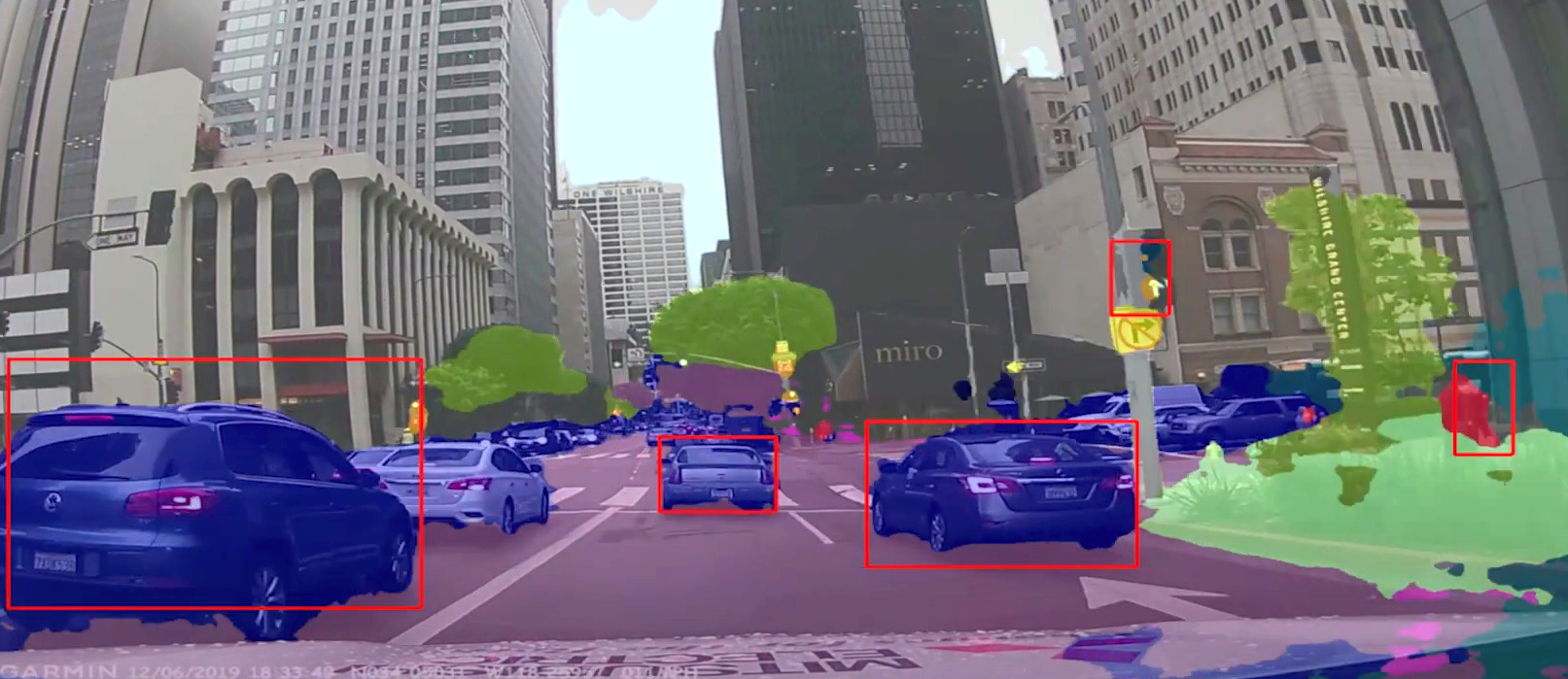
MERL's research on scene-aware interaction was recently featured in an IEEE Spectrum article. The article, titled "At Last, A Self-Driving Car That Can Explain Itself" and authored by MERL Senior Principal Research Scientist Chiori Hori and MERL Director Anthony Vetro, gives an overview of MERL's efforts towards developing a system that can analyze multimodal sensing information for highly natural and intuitive interaction with humans through context-dependent generation of natural language. The technology recognizes contextual objects and events based on multimodal sensing information, such as images and video captured with cameras, audio information recorded with microphones, and localization information measured with LiDAR.
Scene-Aware Interaction for car navigation, one target application that the article focuses on, will provide drivers with intuitive route guidance. Scene-Aware Interaction technology is expected to have wide applicability, including human-machine interfaces for in-vehicle infotainment, interaction with service robots in building and factory automation systems, systems that monitor the health and well-being of people, surveillance systems that interpret complex scenes for humans and encourage social distancing, support for touchless operation of equipment in public areas, and much more. MERL's Scene-Aware Interaction Technology had previously been featured in a Mitsubishi Electric Corporation Press Release.
IEEE Spectrum is the flagship magazine and website of the IEEE, the world’s largest professional organization devoted to engineering and the applied sciences. IEEE Spectrum has a circulation of over 400,000 engineers worldwide, making it one of the leading science and engineering magazines. -
External Link:
https://spectrum.ieee.org/at-last-a-self-driving-car-that-can-explain-itself
-
MERL Contacts:
-
Research Areas:
Artificial Intelligence, Computer Vision, Machine Learning, Speech & Audio
-
Related Publications
- , "Audio-Visual Scene-Aware Dialog and Reasoning Using Audio-Visual Transformers with Joint Student-Teacher Learning", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2022, pp. 7732-7736.
BibTeX TR2022-019 PDF- @inproceedings{Shah2022apr,
- author = {Shah, Ankit Parag and Geng, Shijie and Gao, Peng and Cherian, Anoop and Hori, Takaaki and Marks, Tim K. and {Le Roux}, Jonathan and Hori, Chiori},
- title = {{Audio-Visual Scene-Aware Dialog and Reasoning Using Audio-Visual Transformers with Joint Student-Teacher Learning}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2022,
- pages = {7732--7736},
- month = apr,
- publisher = {IEEE},
- issn = {1520-6149},
- isbn = {978-1-6654-0540-9},
- url = {https://www.merl.com/publications/TR2022-019}
- }
- , "(2.5+1)D Spatio-Temporal Scene Graphs for Video Question Answering", AAAI Conference on Artificial Intelligence, DOI: 10.1609/aaai.v36i1.19922, February 2022, pp. 444-453.
BibTeX TR2022-014 PDF Video Presentation- @inproceedings{Cherian2022feb,
- author = {Cherian, Anoop and Hori, Chiori and Marks, Tim K. and {Le Roux}, Jonathan},
- title = {{(2.5+1)D Spatio-Temporal Scene Graphs for Video Question Answering}},
- booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence},
- year = 2022,
- pages = {444--453},
- month = feb,
- doi = {10.1609/aaai.v36i1.19922},
- url = {https://www.merl.com/publications/TR2022-014}
- }
- , "Dynamic Graph Representation Learning for Video Dialog via Multi-Modal Shuffled Transformers", AAAI Conference on Artificial Intelligence, February 2021, pp. 1415-1423.
BibTeX TR2021-010 PDF- @inproceedings{Geng2021feb,
- author = {Geng, Shijie and Gao, Peng and Chatterjee, Moitreya and Hori, Chiori and {Le Roux}, Jonathan and Zhang, Yongfeng and Li, Hongsheng and Cherian, Anoop},
- title = {{Dynamic Graph Representation Learning for Video Dialog via Multi-Modal Shuffled Transformers}},
- booktitle = {AAAI Conference on Artificial Intelligence},
- year = 2021,
- pages = {1415--1423},
- month = feb,
- publisher = {AAAI Press, Palo Alto, California USA},
- isbn = {978-1-57735-866-4},
- url = {https://www.merl.com/publications/TR2021-010}
- }
- , "Joint Student-Teacher Learning for Audio-Visual Scene-Aware Dialog", Interspeech, September 2019, pp. 1886-1890.
BibTeX TR2019-097 PDF- @inproceedings{Hori2019sep,
- author = {Hori, Chiori and Cherian, Anoop and Marks, Tim K. and Hori, Takaaki},
- title = {{Joint Student-Teacher Learning for Audio-Visual Scene-Aware Dialog}},
- booktitle = {Interspeech},
- year = 2019,
- pages = {1886--1890},
- month = sep,
- publisher = {ISCA},
- url = {https://www.merl.com/publications/TR2019-097}
- }
- , "Audio-Visual Scene-Aware Dialog", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), DOI: 10.1109/CVPR.2019.00774, June 2019, pp. 7550-7559.
BibTeX TR2019-048 PDF- @inproceedings{Alamri2019jun,
- author = {Alamri, Huda and Cartillier, Vincent and Das, Abhishek and Wang, Jue and Lee, Stefan and Anderson, Peter and Essa, Irfan and Parikh, Devi and Batra, Dhruv and Cherian, Anoop and Marks, Tim K. and Hori, Chiori},
- title = {{Audio-Visual Scene-Aware Dialog}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2019,
- pages = {7550--7559},
- month = jun,
- doi = {10.1109/CVPR.2019.00774},
- url = {https://www.merl.com/publications/TR2019-048}
- }
- , "End-to-End Audio Visual Scene-Aware Dialog Using Multimodal Attention-Based Video Features", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), DOI: 10.1109/ICASSP.2019.8682583, May 2019.
BibTeX TR2019-016 PDF- @inproceedings{Hori2019may2,
- author = {Hori, Chiori and Alamri, Huda and Wang, Jue and Wichern, Gordon and Hori, Takaaki and Cherian, Anoop and Marks, Tim K. and Cartillier, Vincent and Lopes, Raphael and Das, Abhishek and Essa, Irfan and Batra, Dhruv and Parikh, Devi},
- title = {{End-to-End Audio Visual Scene-Aware Dialog Using Multimodal Attention-Based Video Features}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2019,
- month = may,
- doi = {10.1109/ICASSP.2019.8682583},
- url = {https://www.merl.com/publications/TR2019-016}
- }
- , "Early and Late Integration of Audio Features for Automatic Video Description", IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), DOI: 10.1109/ASRU.2017.8268968, December 2017.
BibTeX TR2017-183 PDF- @inproceedings{Hori2017dec2,
- author = {Hori, Chiori and Hori, Takaaki and Marks, Tim K. and Hershey, John R.},
- title = {{Early and Late Integration of Audio Features for Automatic Video Description}},
- booktitle = {IEEE Automatic Speech Recognition and Understanding Workshop (ASRU)},
- year = 2017,
- month = dec,
- doi = {10.1109/ASRU.2017.8268968},
- url = {https://www.merl.com/publications/TR2017-183}
- }
- , "Attention-Based Multimodal Fusion for Video Description", IEEE International Conference on Computer Vision (ICCV), DOI: 10.1109/ICCV.2017.450, October 2017.
BibTeX TR2017-156 PDF- @inproceedings{Hori2017oct,
- author = {Hori, Chiori and Hori, Takaaki and Lee, Teng-Yok and Zhang, Ziming and Harsham, Bret A. and Sumi, Kazuhiko and Marks, Tim K. and Hershey, John R.},
- title = {{Attention-Based Multimodal Fusion for Video Description}},
- booktitle = {IEEE International Conference on Computer Vision (ICCV)},
- year = 2017,
- month = oct,
- doi = {10.1109/ICCV.2017.450},
- url = {https://www.merl.com/publications/TR2017-156}
- }
- , "Audio-Visual Scene-Aware Dialog and Reasoning Using Audio-Visual Transformers with Joint Student-Teacher Learning", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2022, pp. 7732-7736.
-




