TR2023-123
Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes
-
- , "Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes", IEEE International Conference on Computer Vision (ICCV), DOI: 10.1109/ICCV51070.2023.00894, October 2023, pp. 3715-3724.BibTeX TR2023-123 PDF Video Software
- @inproceedings{Delattre2023oct,
- author = {Delattre, Fabien and Dirnfeld, David and Nguyen, Phat and Scarano, Stephen and Jones, Michael J. and Miraldo, Pedro and Learned-Miller, Erik},
- title = {{Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes}},
- booktitle = {IEEE International Conference on Computer Vision (ICCV)},
- year = 2023,
- pages = {3715--3724},
- month = oct,
- publisher = {IEEE/CVF},
- doi = {10.1109/ICCV51070.2023.00894},
- issn = {2380-7504},
- isbn = {979-8-3503-0718-4},
- url = {https://www.merl.com/publications/TR2023-123}
- }
- , "Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes", IEEE International Conference on Computer Vision (ICCV), DOI: 10.1109/ICCV51070.2023.00894, October 2023, pp. 3715-3724.
-
MERL Contacts:
-
Research Area:


Abstract:
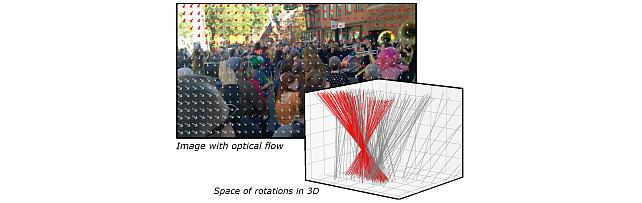
We present an approach to estimating camera rotation in crowded, real-world scenes from handheld monocular video. While camera rotation estimation is a well-studied problem, no previous methods exhibit both high accuracy and acceptable speed in this setting. Because the setting is not addressed well by other datasets, we provide a new dataset and benchmark, with high-accuracy, rigorously verified ground truth, on 17 video sequences. Methods developed for wide baseline stereo (e.g., 5-point methods) perform poorly on monocular video. On the other hand, methods used in autonomous driving (e.g., SLAM) lever- age specific sensor setups, specific motion models, or lo- cal optimization strategies (lagging batch processing) and do not generalize well to handheld video. Finally, for dynamic scenes, commonly used robustification techniques like RANSAC require large numbers of iterations, and be- come prohibitively slow. We introduce a novel generalization of the Hough transform on SO(3) to efficiently and ro- bustly find the camera rotation most compatible with op- tical flow. Among comparably fast methods, ours reduces error by almost 50% over the next best, and is more ac- curate than any method, irrespective of speed. This repre- sents a strong new performance point for crowded scenes, an important setting for computer vision. The code and the dataset are available at https://fabiendelattre.com/robust- rotation-estimation.
Software & Data Downloads
Related News & Events
-
NEWS MERL researchers presenting four papers and organizing the VLAR-SMART101 Workshop at ICCV 2023 Date: October 2, 2023 - October 6, 2023
Where: Paris/France
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Michael J. Jones; Toshiaki Koike-Akino; Suhas Lohit; Tim K. Marks; Pedro Miraldo; Kuan-Chuan Peng; Ye Wang
Research Areas: Artificial Intelligence, Computer Vision, Machine LearningBrief- MERL researchers are presenting 4 papers and organizing the VLAR-SMART-101 workshop at the ICCV 2023 conference, which will be held in Paris, France October 2-6. ICCV is one of the most prestigious and competitive international conferences in computer vision. Details are provided below.
1. Conference paper: “Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image Synthesis,” by Nithin Gopalakrishnan Nair, Anoop Cherian, Suhas Lohit, Ye Wang, Toshiaki Koike-Akino, Vishal Patel, and Tim K. Marks
Conditional generative models typically demand large annotated training sets to achieve high-quality synthesis. As a result, there has been significant interest in plug-and-play generation, i.e., using a pre-defined model to guide the generative process. In this paper, we introduce Steered Diffusion, a generalized framework for fine-grained photorealistic zero-shot conditional image generation using a diffusion model trained for unconditional generation. The key idea is to steer the image generation of the diffusion model during inference via designing a loss using a pre-trained inverse model that characterizes the conditional task. Our model shows clear qualitative and quantitative improvements over state-of-the-art diffusion-based plug-and-play models, while adding negligible computational cost.
2. Conference paper: "BANSAC: A dynamic BAyesian Network for adaptive SAmple Consensus," by Valter Piedade and Pedro Miraldo
We derive a dynamic Bayesian network that updates individual data points' inlier scores while iterating RANSAC. At each iteration, we apply weighted sampling using the updated scores. Our method works with or without prior data point scorings. In addition, we use the updated inlier/outlier scoring for deriving a new stopping criterion for the RANSAC loop. Our method outperforms the baselines in accuracy while needing less computational time.
3. Conference paper: "Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes," by Fabien Delattre, David Dirnfeld, Phat Nguyen, Stephen Scarano, Michael J. Jones, Pedro Miraldo, and Erik Learned-Miller
We present a novel approach to estimating camera rotation in crowded, real-world scenes captured using a handheld monocular video camera. Our method uses a novel generalization of the Hough transform on SO3 to efficiently find the camera rotation most compatible with the optical flow. Because the setting is not addressed well by other data sets, we provide a new dataset and benchmark, with high-accuracy and rigorously annotated ground truth on 17 video sequences. Our method is more accurate by almost 40 percent than the next best method.
4. Workshop paper: "Tensor Factorization for Leveraging Cross-Modal Knowledge in Data-Constrained Infrared Object Detection" by Manish Sharma*, Moitreya Chatterjee*, Kuan-Chuan Peng, Suhas Lohit, and Michael Jones
While state-of-the-art object detection methods for RGB images have reached some level of maturity, the same is not true for Infrared (IR) images. The primary bottleneck towards bridging this gap is the lack of sufficient labeled training data in the IR images. Towards addressing this issue, we present TensorFact, a novel tensor decomposition method which splits the convolution kernels of a CNN into low-rank factor matrices with fewer parameters. This compressed network is first pre-trained on RGB images and then augmented with only a few parameters. This augmented network is then trained on IR images, while freezing the weights trained on RGB. This prevents it from over-fitting, allowing it to generalize better. Experiments show that our method outperforms state-of-the-art.
5. “Vision-and-Language Algorithmic Reasoning (VLAR) Workshop and SMART-101 Challenge” by Anoop Cherian, Kuan-Chuan Peng, Suhas Lohit, Tim K. Marks, Ram Ramrakhya, Honglu Zhou, Kevin A. Smith, Joanna Matthiesen, and Joshua B. Tenenbaum
MERL researchers along with researchers from MIT, GeorgiaTech, Math Kangaroo USA, and Rutgers University are jointly organizing a workshop on vision-and-language algorithmic reasoning at ICCV 2023 and conducting a challenge based on the SMART-101 puzzles described in the paper: Are Deep Neural Networks SMARTer than Second Graders?. A focus of this workshop is to bring together outstanding faculty/researchers working at the intersections of vision, language, and cognition to provide their opinions on the recent breakthroughs in large language models and artificial general intelligence, as well as showcase their cutting edge research that could inspire the audience to search for the missing pieces in our quest towards solving the puzzle of artificial intelligence.
Workshop link: https://wvlar.github.io/iccv23/
- MERL researchers are presenting 4 papers and organizing the VLAR-SMART-101 workshop at the ICCV 2023 conference, which will be held in Paris, France October 2-6. ICCV is one of the most prestigious and competitive international conferences in computer vision. Details are provided below.
Related Video
Related Publication
- @article{Delattre2023oct2,
- author = {Delattre, Fabien and Dirnfeld, David and Nguyen, Phat and Scarano, Stephen and Miraldo, Pedro and Jones, Michael J. and Learned-Miller, Erik},
- title = {{Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes}},
- journal = {arXiv},
- year = 2023,
- month = oct,
- url = {https://arxiv.org/abs/2309.08588}
- }