TR2022-154
Model-Based Policy Search Using Monte Carlo Gradient Estimation with Real Systems Application
-
- , "Model-Based Policy Search Using Monte Carlo Gradient Estimation with Real Systems Application", IEEE Transaction on Robotics, DOI: 10.1109/TRO.2022.3184837, Vol. 38, No. 6, pp. 3879-3898, December 2022.BibTeX TR2022-154 PDF Videos Software
- @article{Romeres2022dec,
- author = {Amadio, Fabio and Dalla Libera, Alberto and Antonello, Riccardo and Nikovski, Daniel N. and Carli, Ruggero and Romeres, Diego},
- title = {{Model-Based Policy Search Using Monte Carlo Gradient Estimation with Real Systems Application}},
- journal = {IEEE Transaction on Robotics},
- year = 2022,
- volume = 38,
- number = 6,
- pages = {3879--3898},
- month = dec,
- doi = {10.1109/TRO.2022.3184837},
- issn = {1941-0468},
- url = {https://www.merl.com/publications/TR2022-154}
- }
- , "Model-Based Policy Search Using Monte Carlo Gradient Estimation with Real Systems Application", IEEE Transaction on Robotics, DOI: 10.1109/TRO.2022.3184837, Vol. 38, No. 6, pp. 3879-3898, December 2022.
-
MERL Contact:
-
Research Area:

Abstract:
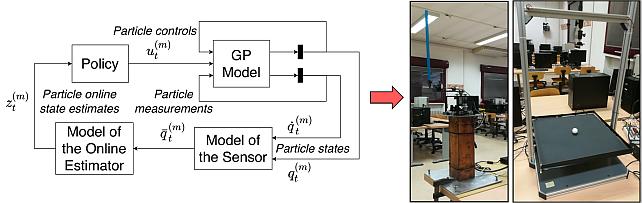
In this paper, we present a Model-Based Reinforcement Learning (MBRL) algorithm named Monte Carlo Probabilistic Inference for Learning COntrol (MC-PILCO). The algorithm relies on Gaussian Processes (GPs) to model the system dynamics and on a Monte Carlo approach to estimate the policy gradient. This defines a framework in which we ablate the choice of the following components: (i) the selection of the cost function, (ii) the optimization of policies using dropout, (iii) an improved data efficiency through the use of structured kernels in the GP models. The combination of the aforementioned aspects affects dramatically the performance of MC-PILCO. Numerical comparisons in a simulated cart-pole environment show that MC-PILCO exhibits better data efficiency and control performance w.r.t. state-of-the-art GP-based MBRL algorithms. Finally, we apply MC-PILCO to real systems, considering in particular systems with partially measurable states. We discuss the importance of modeling both the measurement system and the state estimators during policy optimization. The effectiveness of the proposed solutions has been tested in simulation and on two real systems, a Furuta pendulum and a ball-and-plate rig.
Software & Data Downloads
Related News & Events
-
NEWS MERL Researcher Diego Romeres Collaborates with Mitsubishi Electric and University of Padua to Advance Physics-Embedded AI for Predictive Equipment Maintenance Date: December 10, 2025
Research Areas: Artificial Intelligence, Machine Learning, RoboticsBrief- Mitsubishi Electric Research Laboratories (MERL) researchers, together with collaborators at Mitsubishi Electric’s Information Technology R&D Center in Kamakura, Kanagawa Prefecture, Japan, and the Department of Information Engineering at the University of Padua, have developed a cutting-edge physics-embedded AI technology that substantially improves the accuracy of equipment degradation estimation using minimal training data. This collaborative effort has culminated in a press release by Mitsubishi Electric Corporation announcing the new AI technology as part of its Neuro-Physical AI initiative under the Maisart program.
The interdisciplinary team, including MERL Senior Principal Research Scientist and Team Leader Diego Romeres and University of Padua researchers Alberto Dalla Libera and Giulio Giacomuzzo, combined expertise in machine learning, physical modeling, and real-world industrial systems to embed physics-based models directly into AI frameworks. By training AI with theoretical physical laws and real operational data, the resulting system delivers reliable degradation estimates on the torque of robotic arms even with limited datasets. This result addresses key challenges in preventive maintenance for complex manufacturing environments and supports reduced downtime, maintained quality, and lower lifecycle costs.
The successful integration of these foundational research efforts into Mitsubishi Electric’s business-scale AI solutions exemplifies MERL’s commitment to translating fundamental innovation into real-world impact.
- Mitsubishi Electric Research Laboratories (MERL) researchers, together with collaborators at Mitsubishi Electric’s Information Technology R&D Center in Kamakura, Kanagawa Prefecture, Japan, and the Department of Information Engineering at the University of Padua, have developed a cutting-edge physics-embedded AI technology that substantially improves the accuracy of equipment degradation estimation using minimal training data. This collaborative effort has culminated in a press release by Mitsubishi Electric Corporation announcing the new AI technology as part of its Neuro-Physical AI initiative under the Maisart program.
-
AWARD University of Padua and MERL team wins the AI Olympics with RealAIGym competition at IROS24 Date: October 17, 2024
Awarded to: Niccolò Turcato, Alberto Dalla Libera, Giulio Giacomuzzo, Ruggero Carli, Diego Romeres
Research Areas: Artificial Intelligence, Dynamical Systems, Machine Learning, RoboticsBrief- The team composed of the control group at the University of Padua and MERL's Optimization and Robotic team ranked 1st out of the 4 finalist teams that arrived to the 2nd AI Olympics with RealAIGym competition at IROS 24, which focused on control of under-actuated robots. The team was composed by Niccolò Turcato, Alberto Dalla Libera, Giulio Giacomuzzo, Ruggero Carli and Diego Romeres. The competition was organized by the German Research Center for Artificial Intelligence (DFKI), Technical University of Darmstadt and Chalmers University of Technology.
The competition and award ceremony was hosted by IEEE International Conference on Intelligent Robots and Systems (IROS) on October 17, 2024 in Abu Dhabi, UAE. Diego Romeres presented the team's method, based on a model-based reinforcement learning algorithm called MC-PILCO.
- The team composed of the control group at the University of Padua and MERL's Optimization and Robotic team ranked 1st out of the 4 finalist teams that arrived to the 2nd AI Olympics with RealAIGym competition at IROS 24, which focused on control of under-actuated robots. The team was composed by Niccolò Turcato, Alberto Dalla Libera, Giulio Giacomuzzo, Ruggero Carli and Diego Romeres. The competition was organized by the German Research Center for Artificial Intelligence (DFKI), Technical University of Darmstadt and Chalmers University of Technology.
-
NEWS Invited talk given by Diego Romeres at Bentley University Date: November 1, 2023
Research Areas: Artificial Intelligence, Machine Learning, RoboticsBrief- Principal Research Scientist and Team Leader Diego Romeres gave an invited talk with title 'Applications of Machine Learning to Robotics' in the Machine Learning graduate course at Bentley University. The presentation focused mainly on Reinforcement Learning research applied to robotics. The audience consisted mostly of Master’s in Business Analytics (MSBA) students and students in the MBA w/ Business Analytics Concentration program.
-
AWARD Joint University of Padua-MERL team wins Challenge 'AI Olympics With RealAIGym' Date: August 25, 2023
Awarded to: Alberto Dalla Libera, Niccolo' Turcato, Giulio Giacomuzzo, Ruggero Carli, Diego Romeres
Research Areas: Artificial Intelligence, Machine Learning, RoboticsBrief- A joint team consisting of members of University of Padua and MERL ranked 1st in the IJCAI2023 Challenge "Al Olympics With RealAlGym: Is Al Ready for Athletic Intelligence in the Real World?". The team was composed by MERL researcher Diego Romeres and a team from University Padua (UniPD) consisting of Alberto Dalla Libera, Ph.D., Ph.D. Candidates: Niccolò Turcato, Giulio Giacomuzzo and Prof. Ruggero Carli from University of Padua.
The International Joint Conference on Artificial Intelligence (IJCAI) is a premier gathering for AI researchers and organizes several competitions. This year the competition CC7 "AI Olympics With RealAIGym: Is AI Ready for Athletic Intelligence in the Real World?" consisted of two stages: simulation and real-robot experiments on two under-actuated robotic systems. The two robotics systems were treated as separate tracks and one final winner was selected for each track based on specific performance criteria in the control tasks.
The UniPD-MERL team competed and won in both tracks. The team's system made strong use of a Model-based Reinforcement Learning algorithm called (MC-PILCO) that we recently published in the journal IEEE Transaction on Robotics.
- A joint team consisting of members of University of Padua and MERL ranked 1st in the IJCAI2023 Challenge "Al Olympics With RealAlGym: Is Al Ready for Athletic Intelligence in the Real World?". The team was composed by MERL researcher Diego Romeres and a team from University Padua (UniPD) consisting of Alberto Dalla Libera, Ph.D., Ph.D. Candidates: Niccolò Turcato, Giulio Giacomuzzo and Prof. Ruggero Carli from University of Padua.
-
NEWS Karl Berntorp gave Spotlight Talk at CDC Workshop on Gaussian Process Learning-Based Control Date: December 5, 2022
Where: Cancun, Mexico
Research Areas: Control, Machine LearningBrief- Karl Berntorp was an invited speaker at the workshop on Gaussian Process Learning-Based Control organized at the Conference on Decision and Control (CDC) 2022 in Cancun, Mexico.
The talk was part of a tutorial-style workshop aimed to provide insight into the fundamentals behind Gaussian processes for modeling and control and sketching some of the open challenges and opportunities using Gaussian processes for modeling and control. The talk titled ``Gaussian Processes for Learning and Control: Opportunities for Real-World Impact" described some of MERL's efforts in using Gaussian processes (GPs) for learning and control, with several application examples and discussing some of the key benefits and limitations with using GPs for learning-based control.
- Karl Berntorp was an invited speaker at the workshop on Gaussian Process Learning-Based Control organized at the Conference on Decision and Control (CDC) 2022 in Cancun, Mexico.
Related Videos
Related Publication
- @article{Romeres2021feb,
- author = {Romeres, Diego and Amadio, Fabio and Dalla Libera, Alberto and Antonello, Riccardo and Carli, Ruggero and Nikovski, Daniel N.},
- title = {{Model-Based Policy Search Using Monte Carlo Gradient Estimation with Real Systems Application}},
- journal = {arXiv},
- year = 2021,
- month = feb,
- url = {https://arxiv.org/abs/2101.12115}
- }