TR2019-104
White-Box Adversarial Defense via Self-Supervised Data Estimation
-
- , "White-Box Adversarial Defense via Self-Supervised Data Estimation", arXiv, September 2019.
-
Research Areas:
Abstract:
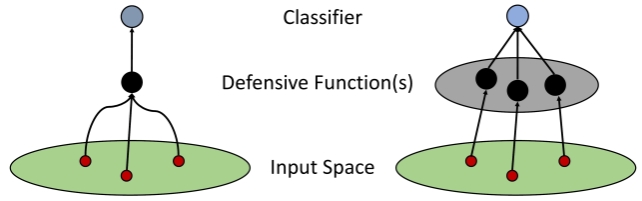
In this paper, we study the problem of how to defend classifiers against adversarial attacks that fool the classifiers using subtly modified input data. In contrast to previous works, here we focus on the white-box adversarial defense where the attackers are granted full access to not only the classifiers but also defenders to produce as strong attack as possible. In such a context we propose viewing a defender as a functional, a high-order function that takes functions as its argument to represent a function space, rather than fixed functions conventionally. From this perspective, a defender should be realized and optimized individually for each adversarial input. To this end, we propose RIDE, an efficient and provably convergent self-supervised learning algorithm for individual data estimation to rescue the predictions from adversarial attacks. We demonstrate the significant improvement of adversarial defense performance on image recognition, e.g. 98%, 76%, 43% test accuracy on MNIST, CIFAR-10, and ImageNet datasets respectively under the state-of-the-art BPDA attacker.