TR2009-031
Semi-Supervised Information Extraction From Variable-Length Web-Page Lists
-
- , "Semi-Supervised Information Extraction from Variable-Length Web-Page Lists", International Conference on Enterprise Information Systems (ICEIS), May 2009.BibTeX TR2009-031 PDF
- @inproceedings{Nikovski2009may,
- author = {Nikovski, D. and Esenther, A. and Baba, A.},
- title = {{Semi-Supervised Information Extraction from Variable-Length Web-Page Lists}},
- booktitle = {International Conference on Enterprise Information Systems (ICEIS)},
- year = 2009,
- month = may,
- url = {https://www.merl.com/publications/TR2009-031}
- }
- , "Semi-Supervised Information Extraction from Variable-Length Web-Page Lists", International Conference on Enterprise Information Systems (ICEIS), May 2009.
-
MERL Contact:
-
Research Areas:

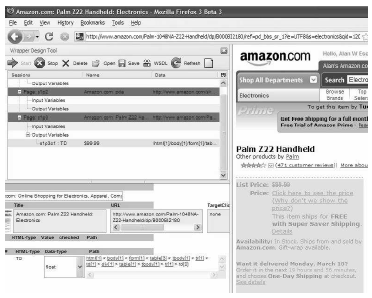
Abstract:
We propose two methods for constructing automated programs for extraction of information from a class of web pages that are very common and of high practical significance -- variable-length lists of records with identical structure. Whereas most existing methods would require multiple example instances of the target web page in order to be able to construct extraction rules, our algorithms require only a single example instance. The first method analyzes the document object model (DOM) tree of the web page to identify repeatable structure that includes all of the specified data fields of interest. The second method provides an interactive way of discovering the list node of the DOM tree by visualizing the correspondence between portions of XPath expressions and visual elements in the web page. Both methods construct extraction rules in the form of XPath expressions, facilitating ease of deployment and integration with other information systems.
Related News & Events
-
NEWS ICEIS 2009: publication by Daniel Nikovski, Alan Esenther and others Date: May 6, 2009
Where: International Conference on Enterprise Information Systems (ICEIS)
MERL Contact: Daniel N. Nikovski
Research Area: Data AnalyticsBrief- The paper "Semi-Supervised Information Extraction from Variable-Length Web-Page Lists" by Nikovski, D., Esenther, A. and Baba, A. was presented at the International Conference on Enterprise Information Systems (ICEIS).