Speech & Audio
Audio source separation, recognition, and understanding.
Our current research focuses on application of machine learning to estimation and inference problems in speech and audio processing. Topics include end-to-end speech recognition and enhancement, acoustic modeling and analysis, statistical dialog systems, as well as natural language understanding and adaptive multimodal interfaces.
Quick Links
-
Researchers
-
Awards
-
AWARD Jonathan Le Roux elevated to IEEE Fellow Date: January 1, 2024
Awarded to: Jonathan Le Roux
MERL Contact: Jonathan Le Roux
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL Distinguished Scientist and Speech & Audio Senior Team Leader Jonathan Le Roux has been elevated to IEEE Fellow, effective January 2024, "for contributions to multi-source speech and audio processing."
Mitsubishi Electric celebrated Dr. Le Roux's elevation and that of another researcher from the company, Dr. Shumpei Kameyama, with a worldwide news release on February 15.
Dr. Jonathan Le Roux has made fundamental contributions to the field of multi-speaker speech processing, especially to the areas of speech separation and multi-speaker end-to-end automatic speech recognition (ASR). His contributions constituted a major advance in realizing a practically usable solution to the cocktail party problem, enabling machines to replicate humans’ ability to concentrate on a specific sound source, such as a certain speaker within a complex acoustic scene—a long-standing challenge in the speech signal processing community. Additionally, he has made key contributions to the measures used for training and evaluating audio source separation methods, developing several new objective functions to improve the training of deep neural networks for speech enhancement, and analyzing the impact of metrics used to evaluate the signal reconstruction quality. Dr. Le Roux’s technical contributions have been crucial in promoting the widespread adoption of multi-speaker separation and end-to-end ASR technologies across various applications, including smart speakers, teleconferencing systems, hearables, and mobile devices.
IEEE Fellow is the highest grade of membership of the IEEE. It honors members with an outstanding record of technical achievements, contributing importantly to the advancement or application of engineering, science and technology, and bringing significant value to society. Each year, following a rigorous evaluation procedure, the IEEE Fellow Committee recommends a select group of recipients for elevation to IEEE Fellow. Less than 0.1% of voting members are selected annually for this member grade elevation.
- MERL Distinguished Scientist and Speech & Audio Senior Team Leader Jonathan Le Roux has been elevated to IEEE Fellow, effective January 2024, "for contributions to multi-source speech and audio processing."
-
AWARD MERL team wins the Audio-Visual Speech Enhancement (AVSE) 2023 Challenge Date: December 16, 2023
Awarded to: Zexu Pan, Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux
MERL Contacts: François Germain; Chiori Hori; Sameer Khurana; Jonathan Le Roux; Zexu Pan; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
The AVSE challenge aims to design better speech enhancement systems by harnessing the visual aspects of speech (such as lip movements and gestures) in a manner similar to the brain’s multi-modal integration strategies. MERL’s system was a scenario-aware audio-visual TF-GridNet, that incorporates the face recording of a target speaker as a conditioning factor and also recognizes whether the predominant interference signal is speech or background noise. In addition to outperforming all competing systems in terms of objective metrics by a wide margin, in a listening test, MERL’s model achieved the best overall word intelligibility score of 84.54%, compared to 57.56% for the baseline and 80.41% for the next best team. The Fisher’s least significant difference (LSD) was 2.14%, indicating that our model offered statistically significant speech intelligibility improvements compared to all other systems.
- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
-
AWARD MERL Intern and Researchers Win ICASSP 2023 Best Student Paper Award Date: June 9, 2023
Awarded to: Darius Petermann, Gordon Wichern, Aswin Subramanian, Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Gordon Wichern
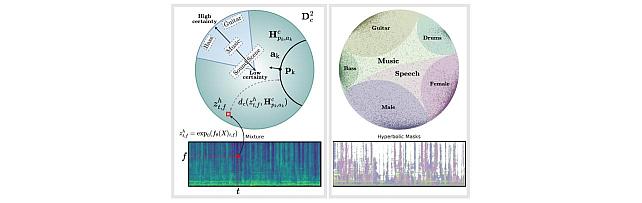
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- Former MERL intern Darius Petermann (Ph.D. Candidate at Indiana University) has received a Best Student Paper Award at the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023) for the paper "Hyperbolic Audio Source Separation", co-authored with MERL researchers Gordon Wichern and Jonathan Le Roux, and former MERL researcher Aswin Subramanian. The paper presents work performed during Darius's internship at MERL in the summer 2022. The paper introduces a framework for audio source separation using embeddings on a hyperbolic manifold that compactly represent the hierarchical relationship between sound sources and time-frequency features. Additionally, the code associated with the paper is publicly available at https://github.com/merlresearch/hyper-unmix.
ICASSP is the flagship conference of the IEEE Signal Processing Society (SPS). ICASSP 2023 was held in the Greek island of Rhodes from June 04 to June 10, 2023, and it was the largest ICASSP in history, with more than 4000 participants, over 6128 submitted papers and 2709 accepted papers. Darius’s paper was first recognized as one of the Top 3% of all papers accepted at the conference, before receiving one of only 5 Best Student Paper Awards during the closing ceremony.
- Former MERL intern Darius Petermann (Ph.D. Candidate at Indiana University) has received a Best Student Paper Award at the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023) for the paper "Hyperbolic Audio Source Separation", co-authored with MERL researchers Gordon Wichern and Jonathan Le Roux, and former MERL researcher Aswin Subramanian. The paper presents work performed during Darius's internship at MERL in the summer 2022. The paper introduces a framework for audio source separation using embeddings on a hyperbolic manifold that compactly represent the hierarchical relationship between sound sources and time-frequency features. Additionally, the code associated with the paper is publicly available at https://github.com/merlresearch/hyper-unmix.
See All Awards for Speech & Audio -
-
News & Events
-
EVENT MERL Contributes to ICASSP 2024 Date: Sunday, April 14, 2024 - Friday, April 19, 2024
Location: Seoul, South Korea
MERL Contacts: Petros T. Boufounos; François Germain; Chiori Hori; Sameer Khurana; Toshiaki Koike-Akino; Jonathan Le Roux; Hassan Mansour; Zexu Pan; Kieran Parsons; Joshua Rapp; Anthony Vetro; Pu (Perry) Wang; Gordon Wichern; Ryoma Yataka
Research Areas: Artificial Intelligence, Computational Sensing, Machine Learning, Robotics, Signal Processing, Speech & AudioBrief- MERL has made numerous contributions to both the organization and technical program of ICASSP 2024, which is being held in Seoul, Korea from April 14-19, 2024.
Sponsorship and Awards
MERL is proud to be a Bronze Patron of the conference and will participate in the student job fair on Thursday, April 18. Please join this session to learn more about employment opportunities at MERL, including openings for research scientists, post-docs, and interns.
MERL is pleased to be the sponsor of two IEEE Awards that will be presented at the conference. We congratulate Prof. Stéphane G. Mallat, the recipient of the 2024 IEEE Fourier Award for Signal Processing, and Prof. Keiichi Tokuda, the recipient of the 2024 IEEE James L. Flanagan Speech and Audio Processing Award.
Jonathan Le Roux, MERL Speech and Audio Senior Team Leader, will also be recognized during the Awards Ceremony for his recent elevation to IEEE Fellow.
Technical Program
MERL will present 13 papers in the main conference on a wide range of topics including automated audio captioning, speech separation, audio generative models, speech and sound synthesis, spatial audio reproduction, multimodal indoor monitoring, radar imaging, depth estimation, physics-informed machine learning, and integrated sensing and communications (ISAC). Three workshop papers have also been accepted for presentation on audio-visual speaker diarization, music source separation, and music generative models.
Perry Wang is the co-organizer of the Workshop on Signal Processing and Machine Learning Advances in Automotive Radars (SPLAR), held on Sunday, April 14. It features keynote talks from leaders in both academia and industry, peer-reviewed workshop papers, and lightning talks from ICASSP regular tracks on signal processing and machine learning for automotive radar and, more generally, radar perception.
Gordon Wichern will present an invited keynote talk on analyzing and interpreting audio deep learning models at the Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA), held on Monday, April 15. He will also appear in a panel discussion on interpretable audio AI at the workshop.
Perry Wang also co-organizes a two-part special session on Next-Generation Wi-Fi Sensing (SS-L9 and SS-L13) which will be held on Thursday afternoon, April 18. The special session includes papers on PHY-layer oriented signal processing and data-driven deep learning advances, and supports upcoming 802.11bf WLAN Sensing Standardization activities.
Petros Boufounos is participating as a mentor in ICASSP’s Micro-Mentoring Experience Program (MiME).
About ICASSP
ICASSP is the flagship conference of the IEEE Signal Processing Society, and the world's largest and most comprehensive technical conference focused on the research advances and latest technological development in signal and information processing. The event attracts more than 3000 participants.
- MERL has made numerous contributions to both the organization and technical program of ICASSP 2024, which is being held in Seoul, Korea from April 14-19, 2024.
-
TALK [MERL Seminar Series 2024] Greta Tuckute presents talk titled Computational models of human auditory and language processing Date & Time: Wednesday, January 31, 2024; 12:00 PM
Speaker: Greta Tuckute, MIT
MERL Host: Sameer Khurana
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioAbstract Advances in machine learning have led to powerful models for audio and language, proficient in tasks like speech recognition and fluent language generation. Beyond their immense utility in engineering applications, these models offer valuable tools for cognitive science and neuroscience. In this talk, I will demonstrate how these artificial neural network models can be used to understand how the human brain processes language. The first part of the talk will cover how audio neural networks serve as computational accounts for brain activity in the auditory cortex. The second part will focus on the use of large language models, such as those in the GPT family, to non-invasively control brain activity in the human language system.
Advances in machine learning have led to powerful models for audio and language, proficient in tasks like speech recognition and fluent language generation. Beyond their immense utility in engineering applications, these models offer valuable tools for cognitive science and neuroscience. In this talk, I will demonstrate how these artificial neural network models can be used to understand how the human brain processes language. The first part of the talk will cover how audio neural networks serve as computational accounts for brain activity in the auditory cortex. The second part will focus on the use of large language models, such as those in the GPT family, to non-invasively control brain activity in the human language system.
See All News & Events for Speech & Audio -
-
Research Highlights
-
Recent Publications
- , "Late Audio-Visual Fusion for In-The-Wild Speaker Diarization", Hands-free Speech Communication and Microphone Arrays (HSCMA), April 2024.BibTeX TR2024-029 PDF
- @inproceedings{Pan2024apr,
- author = {Pan, Zexu and Wichern, Gordon and Germain, François G and Subramanian, Aswin and Le Roux, Jonathan},
- title = {Late Audio-Visual Fusion for In-The-Wild Speaker Diarization},
- booktitle = {Hands-free Speech Communication and Microphone Arrays (HSCMA)},
- year = 2024,
- month = apr,
- url = {https://www.merl.com/publications/TR2024-029}
- }
- , "Understanding and Controlling Generative Music Transformers by Probing Individual Attention Heads", IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA), April 2024.BibTeX TR2024-032 PDF
- @inproceedings{Koo2024apr,
- author = {Koo, Junghyun and Wichern, Gordon and Germain, François G and Khurana, Sameer and Le Roux, Jonathan},
- title = {Understanding and Controlling Generative Music Transformers by Probing Individual Attention Heads},
- booktitle = {IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA)},
- year = 2024,
- month = apr,
- url = {https://www.merl.com/publications/TR2024-032}
- }
- , "Generation or Replication: Auscultating Audio Latent Diffusion Models", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2024.BibTeX TR2024-027 PDF
- @inproceedings{Bralios2024mar,
- author = {Bralios, Dimitrios and Wichern, Gordon and Germain, François G and Pan, Zexu and Khurana, Sameer and Hori, Chiori and Le Roux, Jonathan},
- title = {Generation or Replication: Auscultating Audio Latent Diffusion Models},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-027}
- }
- , "Why does music source separation benefit from cacophony?", IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA), March 2024.BibTeX TR2024-030 PDF Video
- @inproceedings{Jeon2024mar,
- author = {Jeon, Chang-Bin and Wichern, Gordon and Germain, François G and Le Roux, Jonathan},
- title = {Why does music source separation benefit from cacophony?},
- booktitle = {IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-030}
- }
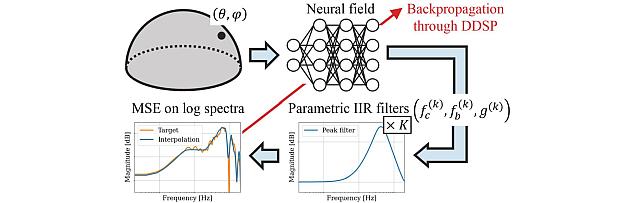
- , "NIIRF: Neural IIR Filter Field for HRTF Upsampling and Personalization", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2024.BibTeX TR2024-026 PDF
- @inproceedings{Masuyama2024mar,
- author = {Masuyama, Yoshiki and Wichern, Gordon and Germain, François G and Pan, Zexu and Khurana, Sameer and Hori, Chiori and Le Roux, Jonathan},
- title = {NIIRF: Neural IIR Filter Field for HRTF Upsampling and Personalization},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-026}
- }
- , "NeuroHeed+: Improving Neuro-steered Speaker Extraction with Joint Auditory Attention Detection", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2024.BibTeX TR2024-025 PDF
- @inproceedings{Pan2024mar,
- author = {Pan, Zexu and Wichern, Gordon and Germain, François G and Khurana, Sameer and Le Roux, Jonathan},
- title = {NeuroHeed+: Improving Neuro-steered Speaker Extraction with Joint Auditory Attention Detection},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-025}
- }
- , "Improving Audio Captioning Models with Fine-grained Audio Features, Text Embedding Supervision, and LLM Mix-up Augmentation", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2024.BibTeX TR2024-028 PDF
- @inproceedings{Wu2024mar,
- author = {Wu, Shih-Lun and Chang, Xuankai and Wichern, Gordon and Jung, Jee-weon and Germain, François G and Le Roux, Jonathan and Watanabe, Shinji},
- title = {Improving Audio Captioning Models with Fine-grained Audio Features, Text Embedding Supervision, and LLM Mix-up Augmentation},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-028}
- }
- , "SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2024.BibTeX TR2024-013 PDF
- @inproceedings{Baoueb2024mar,
- author = {Baoueb, Teysir and Liu, Haocheng and Fontaine, Mathieu and Le Roux, Jonathan and Richard, Gaël},
- title = {SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-013}
- }
- , "Late Audio-Visual Fusion for In-The-Wild Speaker Diarization", Hands-free Speech Communication and Microphone Arrays (HSCMA), April 2024.
-
Videos
-
Software & Data Downloads