Artificial Intelligence
Making machines smarter for improved safety, efficiency and comfort.
Our AI research encompasses advances in computer vision, speech and audio processing, as well as data analytics. Key research themes include improved perception based on machine learning techniques, learning control policies through model-based reinforcement learning, as well as cognition and reasoning based on learned semantic representations. We apply our work to a broad range of automotive and robotics applications, as well as building and home systems.
Quick Links
-
Researchers

Jonathan
Le Roux

Toshiaki
Koike-Akino

Ye
Wang

Gordon
Wichern

Anoop
Cherian

Chiori
Hori

Tim K.
Marks

Michael J.
Jones

Daniel N.
Nikovski

Kieran
Parsons

Devesh K.
Jha

François
Germain

Philip V.
Orlik

Suhas
Lohit

Matthew
Brand

Diego
Romeres

Petros T.
Boufounos

Hassan
Mansour

Pu
(Perry)
Wang
Moitreya
Chatterjee

Siddarth
Jain

Sameer
Khurana

William S.
Yerazunis

Mouhacine
Benosman

Zexu
Pan

Kuan-Chuan
Peng

Arvind
Raghunathan

Radu
Corcodel

Hongbo
Sun

Yebin
Wang

Jianlin
Guo

Chungwei
Lin

Jing
Liu

Yanting
Ma

Bingnan
Wang

Stefano
Di Cairano

Anthony
Vetro

Jinyun
Zhang

Jose
Amaya

Karl
Berntorp

Ankush
Chakrabarty

Vedang M.
Deshpande

Dehong
Liu

James
Queeney

Wataru
Tsujita

Abraham P.
Vinod

Janek
Ebbers

Ryo
Hase

Shinya
Tsuruta

Ryoma
Yataka
-
Awards
-
AWARD Jonathan Le Roux elevated to IEEE Fellow Date: January 1, 2024
Awarded to: Jonathan Le Roux
MERL Contact: Jonathan Le Roux
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL Distinguished Scientist and Speech & Audio Senior Team Leader Jonathan Le Roux has been elevated to IEEE Fellow, effective January 2024, "for contributions to multi-source speech and audio processing."
Mitsubishi Electric celebrated Dr. Le Roux's elevation and that of another researcher from the company, Dr. Shumpei Kameyama, with a worldwide news release on February 15.
Dr. Jonathan Le Roux has made fundamental contributions to the field of multi-speaker speech processing, especially to the areas of speech separation and multi-speaker end-to-end automatic speech recognition (ASR). His contributions constituted a major advance in realizing a practically usable solution to the cocktail party problem, enabling machines to replicate humans’ ability to concentrate on a specific sound source, such as a certain speaker within a complex acoustic scene—a long-standing challenge in the speech signal processing community. Additionally, he has made key contributions to the measures used for training and evaluating audio source separation methods, developing several new objective functions to improve the training of deep neural networks for speech enhancement, and analyzing the impact of metrics used to evaluate the signal reconstruction quality. Dr. Le Roux’s technical contributions have been crucial in promoting the widespread adoption of multi-speaker separation and end-to-end ASR technologies across various applications, including smart speakers, teleconferencing systems, hearables, and mobile devices.
IEEE Fellow is the highest grade of membership of the IEEE. It honors members with an outstanding record of technical achievements, contributing importantly to the advancement or application of engineering, science and technology, and bringing significant value to society. Each year, following a rigorous evaluation procedure, the IEEE Fellow Committee recommends a select group of recipients for elevation to IEEE Fellow. Less than 0.1% of voting members are selected annually for this member grade elevation.
- MERL Distinguished Scientist and Speech & Audio Senior Team Leader Jonathan Le Roux has been elevated to IEEE Fellow, effective January 2024, "for contributions to multi-source speech and audio processing."
-
AWARD Honorable Mention Award at NeurIPS 23 Instruction Workshop Date: December 15, 2023
Awarded to: Lingfeng Sun, Devesh K. Jha, Chiori Hori, Siddharth Jain, Radu Corcodel, Xinghao Zhu, Masayoshi Tomizuka and Diego Romeres
MERL Contacts: Radu Corcodel; Chiori Hori; Siddarth Jain; Devesh K. Jha; Diego Romeres
Research Areas: Artificial Intelligence, Machine Learning, RoboticsBrief- MERL Researchers received an "Honorable Mention award" at the Workshop on Instruction Tuning and Instruction Following at the NeurIPS 2023 conference in New Orleans. The workshop was on the topic of instruction tuning and Instruction following for Large Language Models (LLMs). MERL researchers presented their work on interactive planning using LLMs for partially observable robotic tasks during the oral presentation session at the workshop.
-
AWARD MERL team wins the Audio-Visual Speech Enhancement (AVSE) 2023 Challenge Date: December 16, 2023
Awarded to: Zexu Pan, Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux
MERL Contacts: François Germain; Chiori Hori; Sameer Khurana; Jonathan Le Roux; Zexu Pan; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
The AVSE challenge aims to design better speech enhancement systems by harnessing the visual aspects of speech (such as lip movements and gestures) in a manner similar to the brain’s multi-modal integration strategies. MERL’s system was a scenario-aware audio-visual TF-GridNet, that incorporates the face recording of a target speaker as a conditioning factor and also recognizes whether the predominant interference signal is speech or background noise. In addition to outperforming all competing systems in terms of objective metrics by a wide margin, in a listening test, MERL’s model achieved the best overall word intelligibility score of 84.54%, compared to 57.56% for the baseline and 80.41% for the next best team. The Fisher’s least significant difference (LSD) was 2.14%, indicating that our model offered statistically significant speech intelligibility improvements compared to all other systems.
- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
See All Awards for Artificial Intelligence -
-
News & Events
-
NEWS Diego Romeres gave an invited talk at the Padua University's Seminar series on "AI in Action" Date: April 9, 2024
MERL Contact: Diego Romeres
Research Areas: Artificial Intelligence, Dynamical Systems, Machine Learning, Optimization, RoboticsBrief- Diego Romeres, Principal Research Scientist and Team Leader in the Optimization and Robotics Team, was invited to speak as a guest lecturer in the seminar series on "AI in Action" in the Department of Management and Engineering, at the University of Padua.
The talk, entitled "Machine Learning for Robotics and Automation" described MERL's recent research on machine learning and model-based reinforcement learning applied to robotics and automation.
- Diego Romeres, Principal Research Scientist and Team Leader in the Optimization and Robotics Team, was invited to speak as a guest lecturer in the seminar series on "AI in Action" in the Department of Management and Engineering, at the University of Padua.
-
NEWS Devesh Jha appointed as an Area Chair for NeurIPS 2024 Date: December 9, 2024 - December 15, 2024
Where: NeurIPS 2024
MERL Contact: Devesh K. Jha
Research Areas: Artificial Intelligence, Machine LearningBrief- Devesh Jha, a Principal Research Scientist in the Optimization & Intelligent Robtics team, has been appointed as an area chair for Conference on Neural Information Processing Systems (NeurIPS) 2024. NeurIPS is the premier Machine Learning (ML) and Artificial Intelligence (AI) conference that includes invited talks, demonstrations, symposia, and oral and poster presentations of refereed papers.
See All News & Events for Artificial Intelligence -
-
Research Highlights
-
Internships
-
ST2083: Deep Learning for Radar Perception
The Computation Sensing team at MERL is seeking a highly motivated intern to conduct fundamental research in radar perception. Expertise in deep learning-based object detection, multiple object tracking, data association, and representation learning (detection points, heatmaps, and raw radar waveforms) is required. Previous hands-on experience on open indoor/outdoor radar datasets is a plus. Familiarity with the concept of FMCW, MIMO, and range-Doppler-angle spectrum is an asset. The intern will collaborate with a small group of MERL researchers to develop novel algorithms, design experiments with MERL in-house testbed, and prepare results for patents and publication. The expected duration of the internship is 3 months with a flexible start date.
-
CI2049: Efficient/Green AI
MERL is seeking highly motivated and qualified interns to work on efficient machine learning techniques. The ideal candidates would have significant research experience in federated learning, generative large language models, and efficient/green AI. A mature understanding of modern machine learning methods, proficiency with Python, and familiarity with deep learning frameworks are expected. Candidates at or beyond the middle of their Ph.D. program are encouraged to apply. The expected duration is 3 months long with flexible start dates.
-
CI2091: Robust AI for Operational Technology Security
MERL is seeking a highly motivated and qualified intern to work on operational technology security. The ideal candidate would have significant research experience in cybersecurity for operational technology, anomaly detection, robust machine learning, and defenses against adversarial examples. A mature understanding of modern machine learning methods, proficiency with Python, and familiarity with deep learning frameworks are expected. Candidates at or beyond the middle of their Ph.D. program are encouraged to apply. The expected duration is 3 months with flexible start dates.
See All Internships for Artificial Intelligence -
-
Recent Publications
- , "Late Audio-Visual Fusion for In-The-Wild Speaker Diarization", Hands-free Speech Communication and Microphone Arrays (HSCMA), April 2024.BibTeX TR2024-029 PDF
- @inproceedings{Pan2024apr,
- author = {Pan, Zexu and Wichern, Gordon and Germain, François G and Subramanian, Aswin and Le Roux, Jonathan},
- title = {Late Audio-Visual Fusion for In-The-Wild Speaker Diarization},
- booktitle = {Hands-free Speech Communication and Microphone Arrays (HSCMA)},
- year = 2024,
- month = apr,
- url = {https://www.merl.com/publications/TR2024-029}
- }
- , "Optimal Transport Perturbations for Safe Reinforcement Learning with Robustness Guarantees", Transactions on Machine Learning Research (TMLR), April 2024.BibTeX TR2024-037 PDF
- @article{Queeney2024apr,
- author = {Queeney, James and Ozcan, Erhan Can and Paschalidis, Ioannis Ch. and Cassandras, Christos G.},
- title = {Optimal Transport Perturbations for Safe Reinforcement Learning with Robustness Guarantees},
- journal = {Transactions on Machine Learning Research (TMLR)},
- year = 2024,
- month = apr,
- issn = {2835-8856},
- url = {https://www.merl.com/publications/TR2024-037}
- }
- , "Understanding and Controlling Generative Music Transformers by Probing Individual Attention Heads", IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA), April 2024.BibTeX TR2024-032 PDF
- @inproceedings{Koo2024apr,
- author = {Koo, Junghyun and Wichern, Gordon and Germain, François G and Khurana, Sameer and Le Roux, Jonathan},
- title = {Understanding and Controlling Generative Music Transformers by Probing Individual Attention Heads},
- booktitle = {IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA)},
- year = 2024,
- month = apr,
- url = {https://www.merl.com/publications/TR2024-032}
- }
- , "Multi-level Reasoning for Robotic Assembly: From Sequence Inference to Contact Selection", IEEE International Conference on Robotics and Automation (ICRA), March 2024.BibTeX TR2024-033 PDF Video
- @inproceedings{Zhu2024mar,
- author = {Zhu, Xinghao and Jha, Devesh K. and Romeres, Diego and Sun, Lingfeng and Tomizuka, Masayoshi and Cherian, Anoop},
- title = {Multi-level Reasoning for Robotic Assembly: From Sequence Inference to Contact Selection},
- booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-033}
- }
- , "Generation or Replication: Auscultating Audio Latent Diffusion Models", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2024.BibTeX TR2024-027 PDF
- @inproceedings{Bralios2024mar,
- author = {Bralios, Dimitrios and Wichern, Gordon and Germain, François G and Pan, Zexu and Khurana, Sameer and Hori, Chiori and Le Roux, Jonathan},
- title = {Generation or Replication: Auscultating Audio Latent Diffusion Models},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-027}
- }
- , "Why does music source separation benefit from cacophony?", IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA), March 2024.BibTeX TR2024-030 PDF Video
- @inproceedings{Jeon2024mar,
- author = {Jeon, Chang-Bin and Wichern, Gordon and Germain, François G and Le Roux, Jonathan},
- title = {Why does music source separation benefit from cacophony?},
- booktitle = {IEEE ICASSP Satellite Workshop on Explainable Machine Learning for Speech and Audio (XAI-SA)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-030}
- }
- , "NIIRF: Neural IIR Filter Field for HRTF Upsampling and Personalization", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2024.BibTeX TR2024-026 PDF
- @inproceedings{Masuyama2024mar,
- author = {Masuyama, Yoshiki and Wichern, Gordon and Germain, François G and Pan, Zexu and Khurana, Sameer and Hori, Chiori and Le Roux, Jonathan},
- title = {NIIRF: Neural IIR Filter Field for HRTF Upsampling and Personalization},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-026}
- }
- , "NeuroHeed+: Improving Neuro-steered Speaker Extraction with Joint Auditory Attention Detection", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2024.BibTeX TR2024-025 PDF
- @inproceedings{Pan2024mar,
- author = {Pan, Zexu and Wichern, Gordon and Germain, François G and Khurana, Sameer and Le Roux, Jonathan},
- title = {NeuroHeed+: Improving Neuro-steered Speaker Extraction with Joint Auditory Attention Detection},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2024,
- month = mar,
- url = {https://www.merl.com/publications/TR2024-025}
- }
- , "Late Audio-Visual Fusion for In-The-Wild Speaker Diarization", Hands-free Speech Communication and Microphone Arrays (HSCMA), April 2024.
-
Videos
-
Software & Data Downloads
-
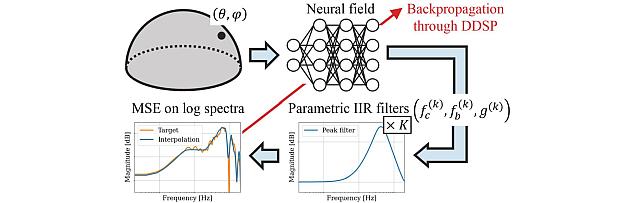
neural-IIR-field -

Pixel-Grounded Prototypical Part Networks -
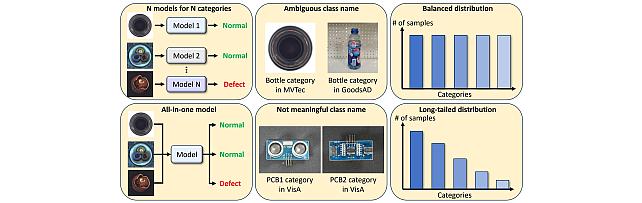
Long-Tailed Anomaly Detection (LTAD) Dataset -
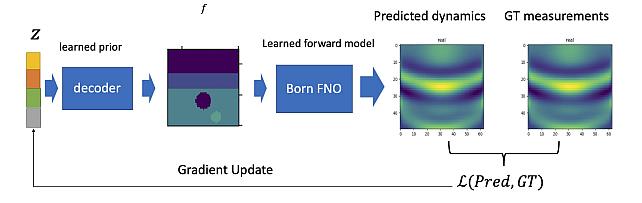
DeepBornFNO -
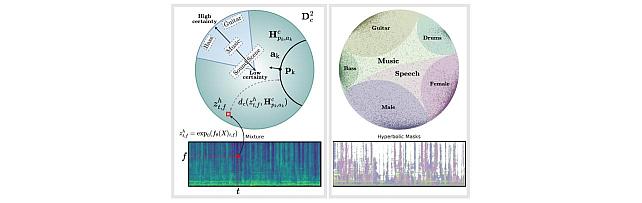
Hyperbolic Audio Source Separation -

Simple Multimodal Algorithmic Reasoning Task Dataset -
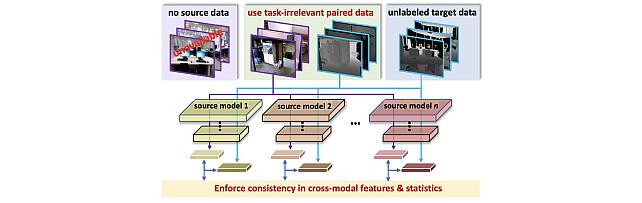
SOurce-free Cross-modal KnowledgE Transfer -
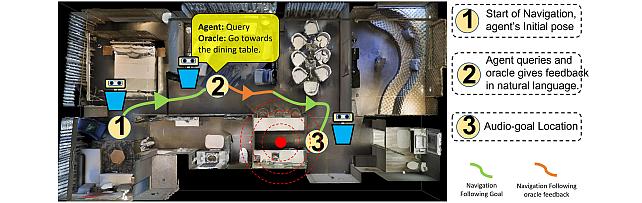
Audio-Visual-Language Embodied Navigation in 3D Environments -
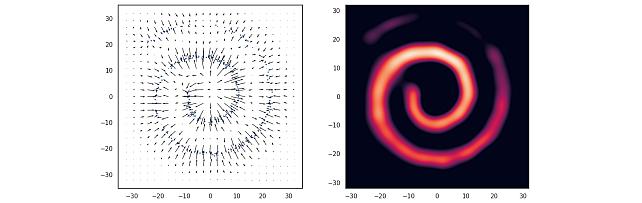
Nonparametric Score Estimators -

3D MOrphable STyleGAN -
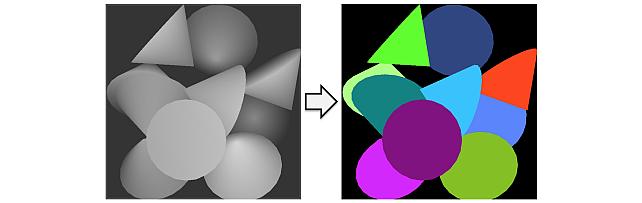
Instance Segmentation GAN -
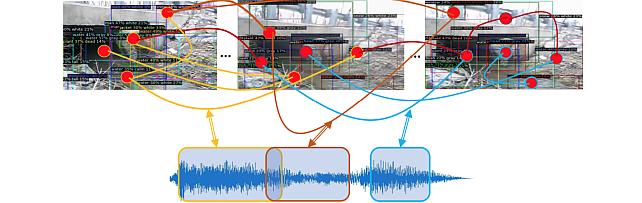
Audio Visual Scene-Graph Segmentor -
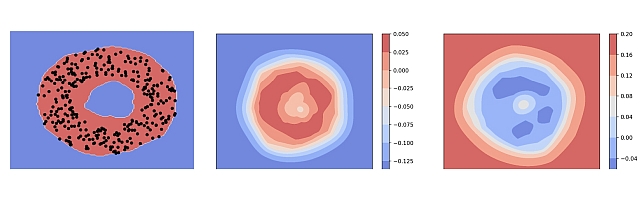
Generalized One-class Discriminative Subspaces -

Goal directed RL with Safety Constraints -
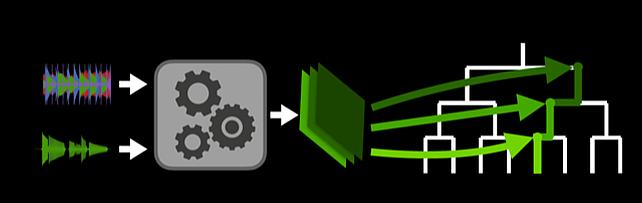
Hierarchical Musical Instrument Separation -

Generating Visual Dynamics from Sound and Context -

Adversarially-Contrastive Optimal Transport -
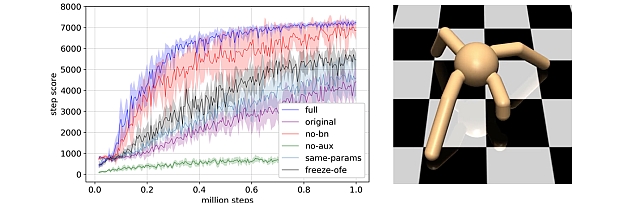
Online Feature Extractor Network -
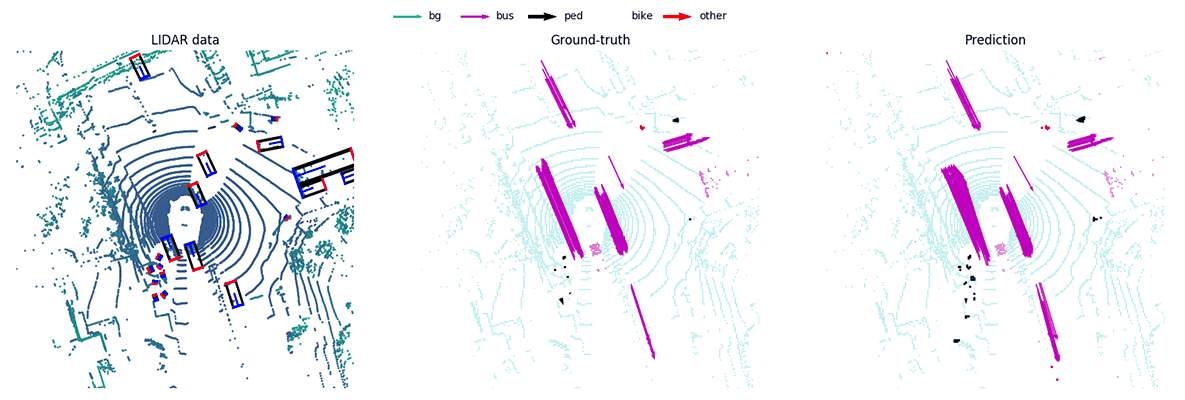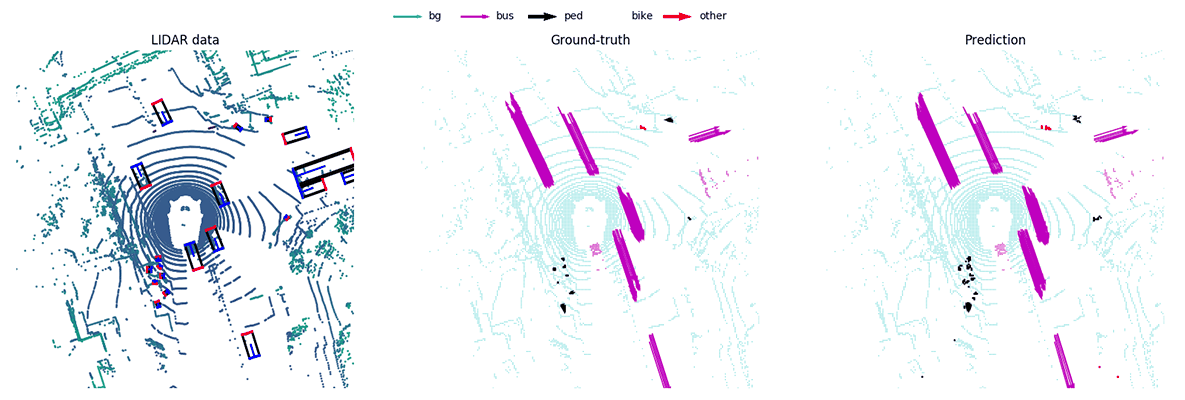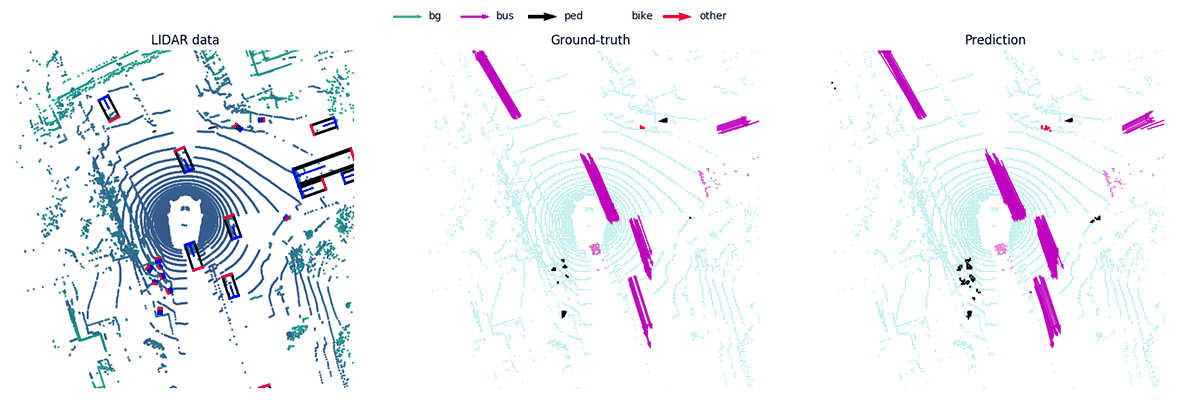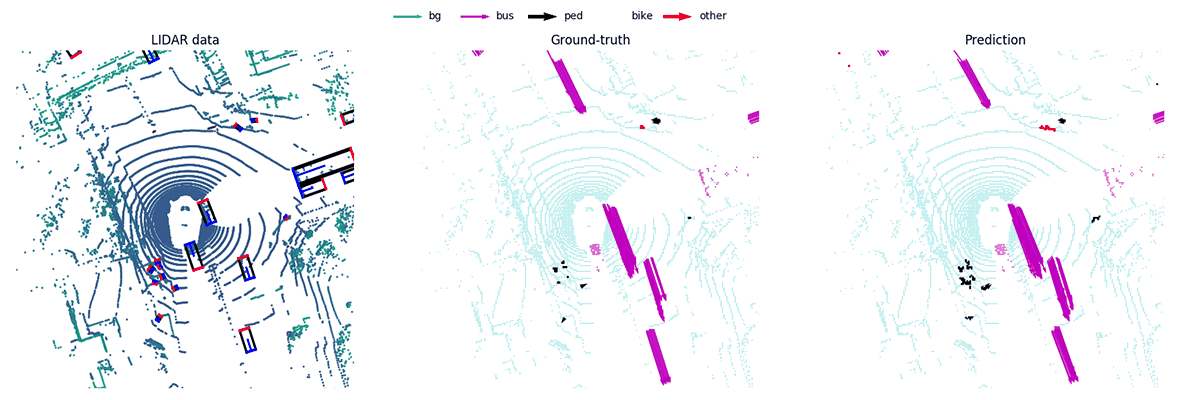
MotionNet -

FoldingNet++ -
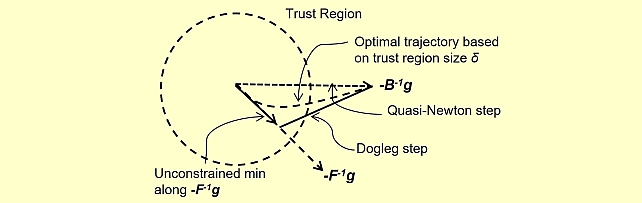
Quasi-Newton Trust Region Policy Optimization -
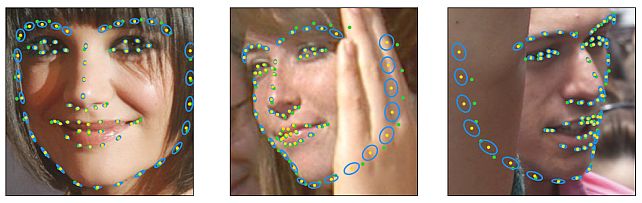
Landmarks’ Location, Uncertainty, and Visibility Likelihood -
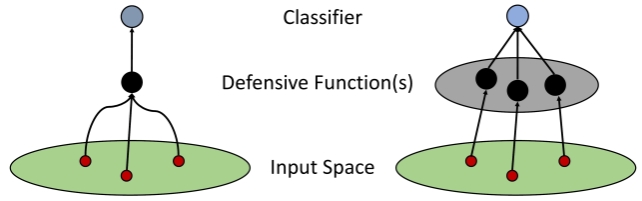
Robust Iterative Data Estimation -
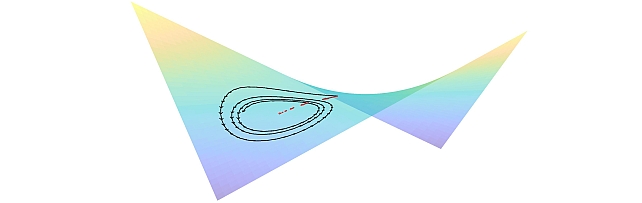
Gradient-based Nikaido-Isoda -

Discriminative Subspace Pooling -
Partial Group Convolutional Neural Networks
-