TR2019-120
Quasi-Newton Trust Region Policy Optimization
-
- , "Quasi-Newton Trust Region Policy Optimization", Conference on Robot Learning (CoRL), Leslie Pack Kaelbling and Danica Kragic and Komei Sugiura, Eds., October 2019, pp. 945-954.BibTeX TR2019-120 PDF Software
- @inproceedings{Jha2019oct,
- author = {Jha, Devesh K. and Raghunathan, Arvind and Romeres, Diego},
- title = {Quasi-Newton Trust Region Policy Optimization},
- booktitle = {Conference on Robot Learning (CoRL)},
- year = 2019,
- editor = {Leslie Pack Kaelbling and Danica Kragic and Komei Sugiura},
- pages = {945--954},
- month = oct,
- publisher = {Proceedings of Machine Learning Research},
- url = {https://www.merl.com/publications/TR2019-120}
- }
- , "Quasi-Newton Trust Region Policy Optimization", Conference on Robot Learning (CoRL), Leslie Pack Kaelbling and Danica Kragic and Komei Sugiura, Eds., October 2019, pp. 945-954.
-
MERL Contacts:
-
Research Areas:
Artificial Intelligence, Machine Learning, Optimization, Robotics



Abstract:
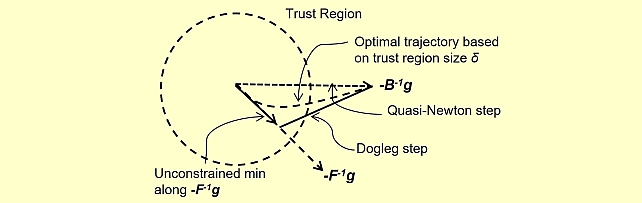
We propose a trust region method for policy optimization that employs Quasi-Newton approximation for the Hessian, called Quasi-Newton Trust Region Policy Optimization (QNTRPO). Gradient descent is the de facto algorithm for reinforcement learning tasks with continuous controls. The algorithm has achieved state-of-the-art performance when used in reinforcement learning across a wide range of tasks. However, the algorithm suffers from a number of drawbacks including: lack of stepsize selection criterion, and slow convergence. We investigate the use of a trust region method using dogleg step and a Quasi-Newton approximation for the Hessian for policy optimization. We demonstrate through numerical experiments over a wide range of challenging continuous control tasks that our particular choice is efcient in terms of number of samples and improves performance.
Software & Data Downloads
Related News & Events
-
NEWS MERL researcher Diego Romeres gave an invited talk at University of Connecticut on Reinforcement Learning for Robotics Date: November 20, 2019
MERL Contact: Diego Romeres
Research Areas: Artificial Intelligence, Data Analytics, Machine Learning, RoboticsBrief- Diego Romeres, a Research Scientist in MERL's Data Analytics group, gave a seminar lecture at the Electrical and Computer Engineering Colloquium of the University of Connecticut. The talk described novel reinforcement algorithms based on combining physical models with non-parametric models of robotic systems derived from data.
Related Publications
- @inproceedings{Jha2019dec,
- author = {Jha, Devesh K. and Raghunathan, Arvind and Romeres, Diego},
- title = {QNTRPO: Including Curvature in TRPO},
- booktitle = {Optimization Foundations for Reinforcement Learning Workshop at NeurIPS},
- year = 2019,
- month = dec,
- url = {https://www.merl.com/publications/TR2019-154}
- }