TR2014-029
A vanishing point-based global descriptor for Manhattan scenes
-
- , "A Vanishing Point-based Global Descriptor for Manhattan Scenes", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), DOI: 10.1109/ICASSP.2014.6854423, May 2014, pp. 4349-4353.BibTeX TR2014-029 PDF
- @inproceedings{Naini2014may,
- author = {Naini, R. and Rane, S. and Ramalingam, S.},
- title = {{A Vanishing Point-based Global Descriptor for Manhattan Scenes}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2014,
- pages = {4349--4353},
- month = may,
- publisher = {IEEE},
- doi = {10.1109/ICASSP.2014.6854423},
- url = {https://www.merl.com/publications/TR2014-029}
- }
- , "A Vanishing Point-based Global Descriptor for Manhattan Scenes", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), DOI: 10.1109/ICASSP.2014.6854423, May 2014, pp. 4349-4353.
-
Research Area:
Digital Video
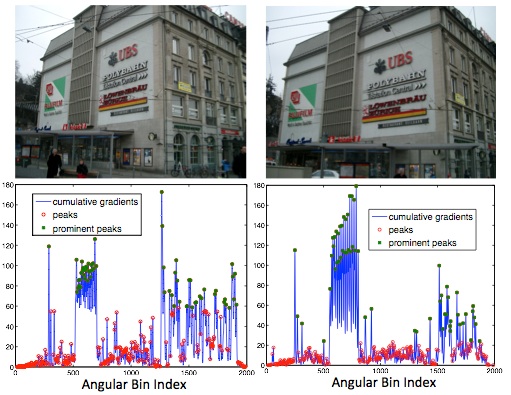
Abstract:
Viewpoint-invariant object matching is challenging due to image distortions caused by several factors such as rotation, translation, illumination, cropping and occlusion. We propose a compact, global image descriptor for Manhattan scenes that captures relative locations and strengths of edges along vanishing directions. To construct the descriptor, an edge map is determined per vanishing point, capturing the edge strengths over a range of angles measured at the vanishing point. For matching, descriptors from two scenes are compared across multiple candidate scales and displacements. The matching performance is refined by comparing edge shapes at the local maxima of the scale-displacement plots. The proposed descriptor matching algorithm achieves an equal error rate of 7% for the Zurich Buildings Database, indicating significant gains in discriminative ability over other global descriptors that rely on aggregate image statistics but do not exploit the underlying scene geometry.