TR2014-027
Non-negative source-filter dynamical system for speech enhancement
-
- , "Non-negative Source-filter Dynamical System for Speech Enhancement", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), DOI: 10.1109/ICASSP.2014.6854797, May 2014, pp. 6206-6210.BibTeX TR2014-027 PDF Software
- @inproceedings{Simsekli2014may,
- author = {Simsekli, U. and {Le Roux}, J. and Hershey, J.R.},
- title = {Non-negative Source-filter Dynamical System for Speech Enhancement},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2014,
- pages = {6206--6210},
- month = may,
- publisher = {IEEE},
- doi = {10.1109/ICASSP.2014.6854797},
- url = {https://www.merl.com/publications/TR2014-027}
- }
- , "Non-negative Source-filter Dynamical System for Speech Enhancement", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), DOI: 10.1109/ICASSP.2014.6854797, May 2014, pp. 6206-6210.
-
MERL Contact:
-
Research Areas:

Abstract:
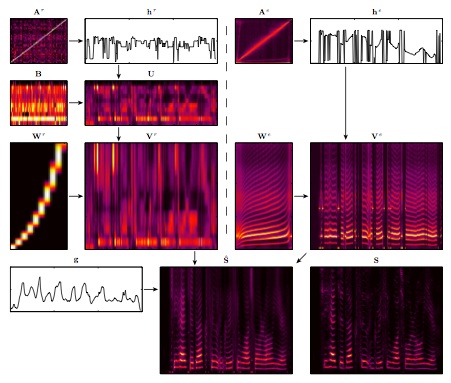
Model-based speech enhancement methods, which rely on separately modeling the speech and the noise, have been shown to be powerful in many different problem settings. When the structure of the noise can be arbitrary, which is often the case in practice, model- based methods have to focus on developing good speech models, whose quality will be key to their performance. In this study, we propose a novel probabilistic model for speech enhancement which precisely models the speech by taking into account the underlying speech production process as well as its dynamics. The proposed model follows a source-filter approach where the excitation and filter parts are modeled as non-negative dynamical systems. We present convergence-guaranteed update rules for each latent factor. In order to assess performance, we evaluate our model on a challenging speech enhancement task where the speech is observed under non-stationary noises recorded in a car. We show that our model outperforms state-of-the-art methods in terms of objective measures.
Software & Data Downloads
Related News & Events
-
NEWS IEEE Spectrum's "Cars That Think" highlights MERL's speech enhancement research Date: March 9, 2015
MERL Contact: Jonathan Le Roux
Research Area: Speech & AudioBrief- Recent research on speech enhancement by MERL's Speech and Audio team was highlighted in "Cars That Think", IEEE Spectrum's blog on smart technologies for cars. IEEE Spectrum is the flagship publication of the Institute of Electrical and Electronics Engineers (IEEE), the world's largest association of technical professionals with more than 400,000 members.
-
NEWS MERL's noise suppression technology featured in Mitsubishi Electric Corporation press release Date: February 17, 2015
MERL Contact: Jonathan Le Roux
Research Area: Speech & AudioBrief- Mitsubishi Electric Corporation announced that it has developed breakthrough noise-suppression technology that significantly improves the quality of hands-free voice communication in noisy conditions, such as making a voice call via a car navigation system. Speech clarity is improved by removing 96% of surrounding sounds, including rapidly changing noise from turn signals or wipers, which are difficult to suppress using conventional methods. The technology is based on recent research on speech enhancement by MERL's Speech and Audio team. .